
Nvidia GB200 NVL2: Blackwell gibt es jetzt auch als Modul mit zwei GPUs und CPUs

Nvidia erweitert die MGX-Plattform für modulare Serverdesigns mit dem GB200 NVL2 um eine Variante, die auf die neuesten AI-Beschleuniger der Blackwell-Generation setzt. Käufer erhalten damit zwei Blackwell-GPUs und zwei Grace-CPUs und können die Platine vergleichsweise schnell in ihre bestehende Server-Infrastruktur integrieren.
Es muss ja nicht immer gleich ein nagelneuer High-End-Server mit 72 Blackwell-GPUs sein, so wie ihn Nvidia mit dem GB200 NVL72 offeriert, um in die Welt der AI-Datenverarbeitung einzusteigen. Nvidias neueste Hardware-Generation soll sich auch vergleichsweise einfach und auf Wunsch in kleinerem Umfang in die bestehende Server-Infrastruktur integrieren lassen. Zur Computex gibt es die passende Lösung.

GB200 NVL2 statt NVL72
GB200 NVL2 ist die Abkürzung für Grace Blackwell 200 NVLink 2, da auf dem Server-Einschub zwei Grace-CPUs mit insgesamt 144 Arm-Neoverse-V2-Kernen sowie zwei Blackwell-GPUs des Typs B200 mit insgesamt 384 GB HBM3e zum Einsatz kommen. Bezieht man den LPDDR5X-RAM der Grace-CPUs mit ein, ergeben sich rund 1,3 TB schneller kohärenter Speicher für die Gesamtlösung. CPU und GPU verbindet jeweils der eigene Interconnect NVLink-C2C mit einer Datenrate von 900 GB/s.
Bei der vorherigen Hopper-Architektur respektive der Grace-Hopper-Kombination war bislang das Maximum der MGX-Plattform erreicht, mit dem GB200 NVL2 ändert sich das. Im Prinzip erhalten Käufer damit eine Einheit aus dem GB200 NVL72, doch kommen dort 36 der GB200 Grace Blackwell Superchips für insgesamt 72 GPUs und 36 CPUs zum Einsatz, die sich wiederum in 18 GB200 Superchip Compute Trays (4 × GPU + 2 × CPU) unterteilen und damit die „Blackwell AI Factory“ aufbauen. Auf dem Modul des GB200 NVL2 sitzen hingegen nur zwei GPUs und CPUs.

Modulare Server-Lösung mit Standard-Chassis
MGX ist Nvidias modulare Server-Plattform (White Paper, PDF), deren standardisiertes Chassis aktuell mehr als 100 Konfigurationen ermöglicht, zu denen mit dem GB200 NVL2 jetzt eine weitere hinzustößt. Zum Einsatz kommen können x86- und Arm-CPUs, verschiedene GPUs, DPUs, NICs, Speicherlösungen und Kühlkonzepte. Erstmals liefern mit dieser Generation auch AMD und Intel eigene CPU-Modul-Designs für die Plattform, die bei AMD auf Turin und bei Intel auf Xeon 6 alias Granite Rapids setzen.
Keine Überraschung: Schneller als x86-Server
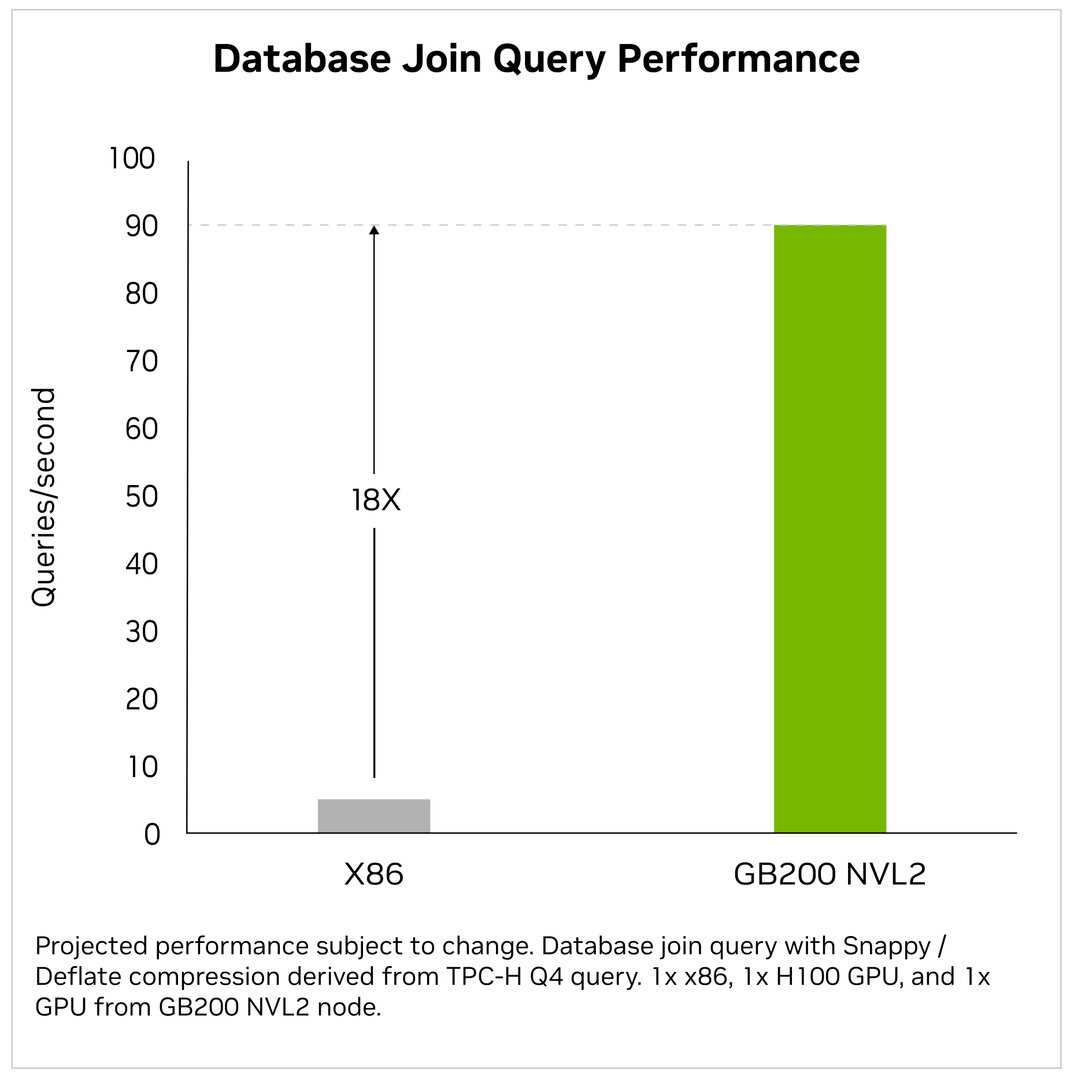
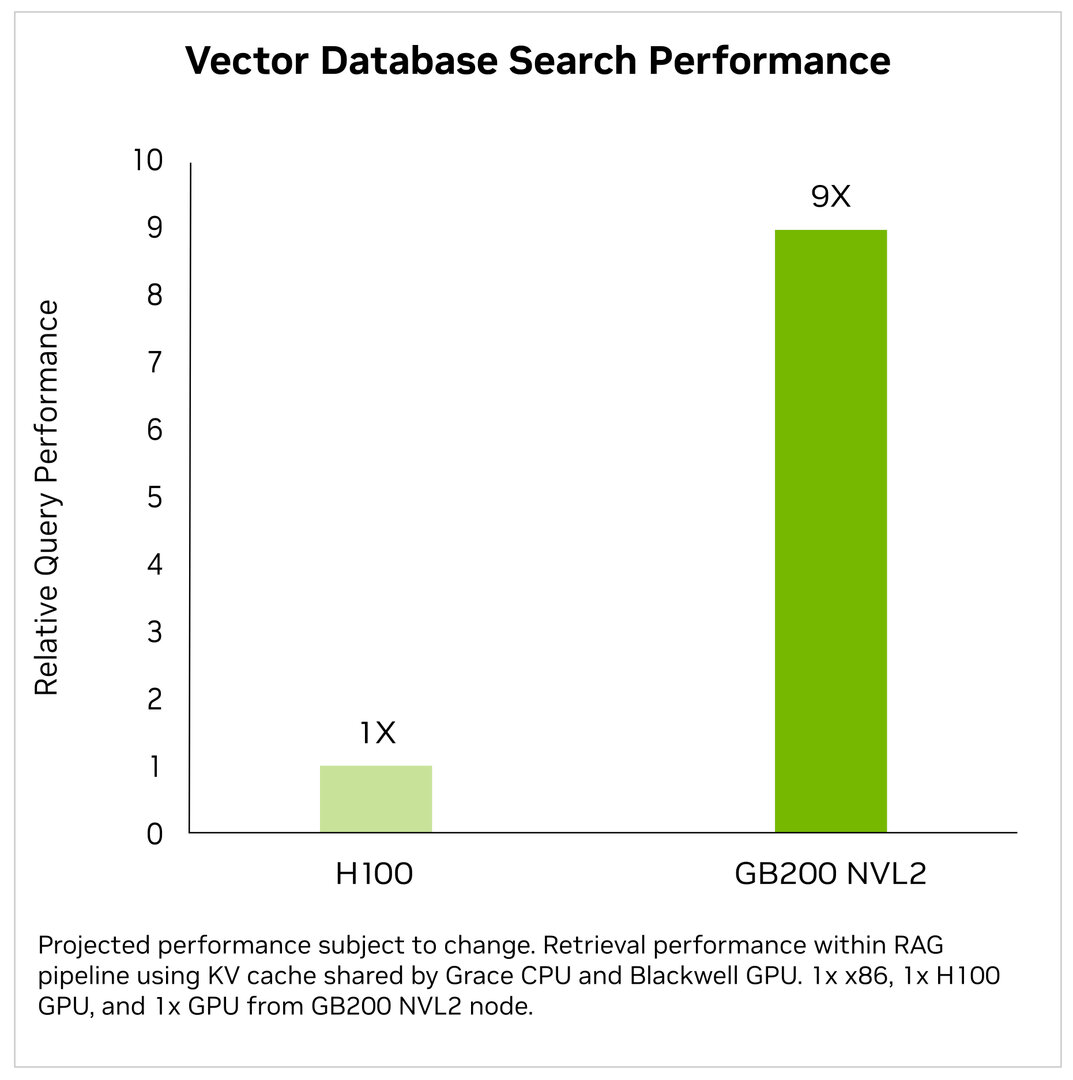
Aufgrund der zwei Blackwell-GPUs kommt der GB200 NVL2 allerdings analog zum GB200 Grace Blackwell Superchip auf 40 PFLOPS AI-Leistung und könne damit laut Nvidia die AI-Datenverarbeitung im Vergleich zu einem klassischen x86-Server nur mit CPUs um den Faktor 18x beschleunigen. Für die bei LLMs genutzt RAG-Vector-Datenbanksuche (Retrieval Augmented Generation) und das Inferencing des Meta-LLMs Llama 3 gibt Nvidia im Vergleich zum HGX H100 Verbesserungen um den Faktor 9x respektive 5x an.

Günstiger und schneller zu integrieren
Diese neue, modulare Hardware können Betreiber in ihre eigenen Server-Chassis integrieren, wobei auch diese abseits des Standards der Plattform von den Partnern und nicht von Nvidia selbst stammen. Laut Nvidia arbeite man bei der MGX-Referenz-Architektur aktuell mit mehr als 25 Partnern für über 90 Systeme zusammen – letztes Jahr seien es noch 14 Partner gewesen. Mit den nach MGX-Architektur vordefinierten Lösungen könnten die Entwicklungskosten um bis zu drei Viertel und die Entwicklungszeit um bis zu zwei Drittel auf lediglich noch sechs Monate für einen neuen Server-Aufbau reduziert werden, ließ Nvidia zur Computex-Keynote in Taipeh, Taiwan verlauten.