Arm-Kerne 2022: Cortex-A715 und Cortex-A510 Refresh: Effizienz im Fokus
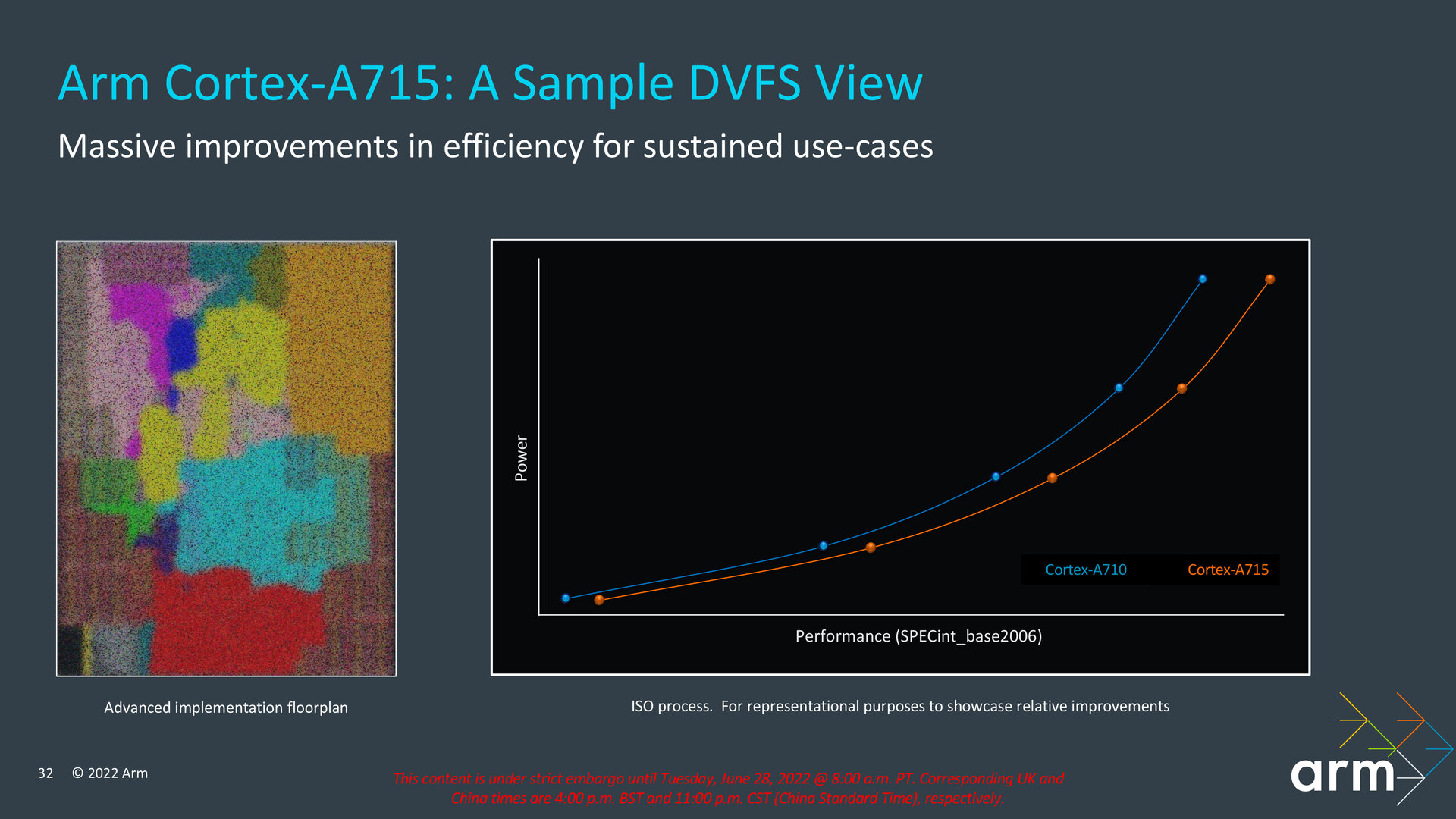
3/3Gleiche Leistung bei 20 Prozent weniger Verbrauch
Während der neue Cortex-X3 analog zu den früheren Iterationen primär auf Leistung getrimmt ist, spielt beim Cortex-A715 als Nachfolger des Cortex-A710 trotz der Auslegung als Performance-Core dennoch die Effizienz eine größere Rolle. Mit dem Cortex-A715 will Arm eine Balance aus Leistung und Effizienz erreichen, weshalb sich die IPC-Zuwächse in Grenzen halten und dieses Jahr die Effizienz den größeren Sprung macht. Soll der Cortex-A715 unter Verwendung desselben Fertigungsprozesses („ISO Process“) dieselbe Leistung wie ein Cortex-A710 liefern, fällt der Energieverbrauch des Kerns satte 20 Prozent niedriger aus. Bei demselben Bedarf wie ein Cortex-A710 kommt der Cortex-A715 hingegen auf ein Plus von 5 Prozent bezogen auf die Leistung.
„Efficient Performance“ lautet das Motto für den Cortex-A715, weshalb bei der Entwicklung ein Leistungszuwachs Vorrang vor einem höheren Verbrauch und einer Vergrößerung der benötigten Fläche auf dem Die hatte. Mehr Leistung sollte es demnach nicht geben, wenn dafür mit den anderen Voraussetzungen gebrochen werden müsste. Aus der bestehenden Out-of-Order-Struktur des Kerns wollte Arm das Maximum herausholen, weshalb der Kern nur minimal in der Tiefe etwa bei den Decoder-Stufen wächst, aber die bisherige Breite beibehält, wo dennoch ein höherer Durchsatz erreicht werden soll. In puncto Bandbreite und Genauigkeit bei der Sprungvorhersage respektive Abdeckung und Genauigkeit beim Prefetching nimmt der Cortex-A715 Anleihen aus der Cortex-X-Entwicklung.
-
 Verbrauch sinkt um 20 Prozent bei gleicher Leistung (Bild: Arm)
Verbrauch sinkt um 20 Prozent bei gleicher Leistung (Bild: Arm)
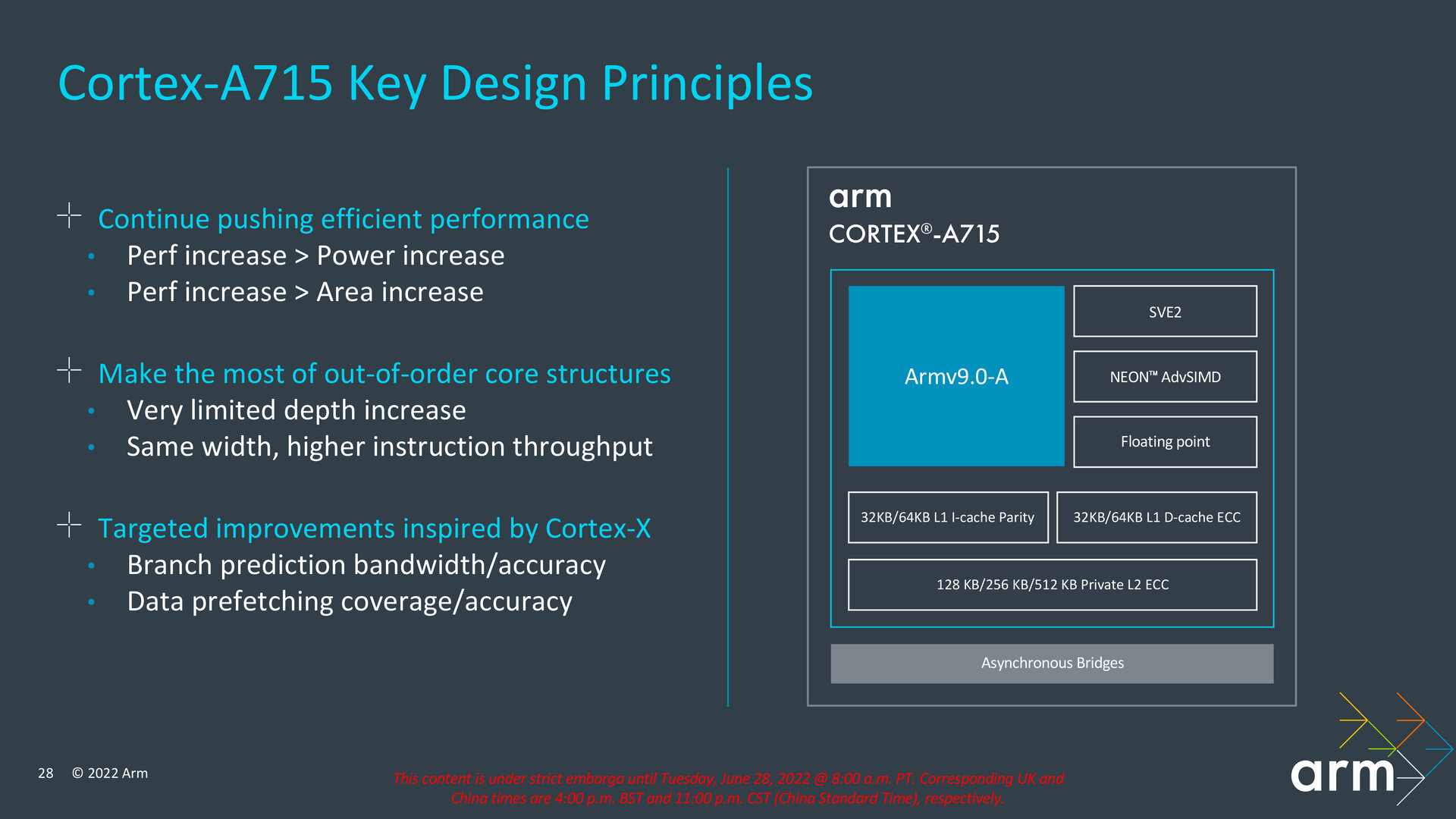
Front-End erhält zweiten Prädiktor
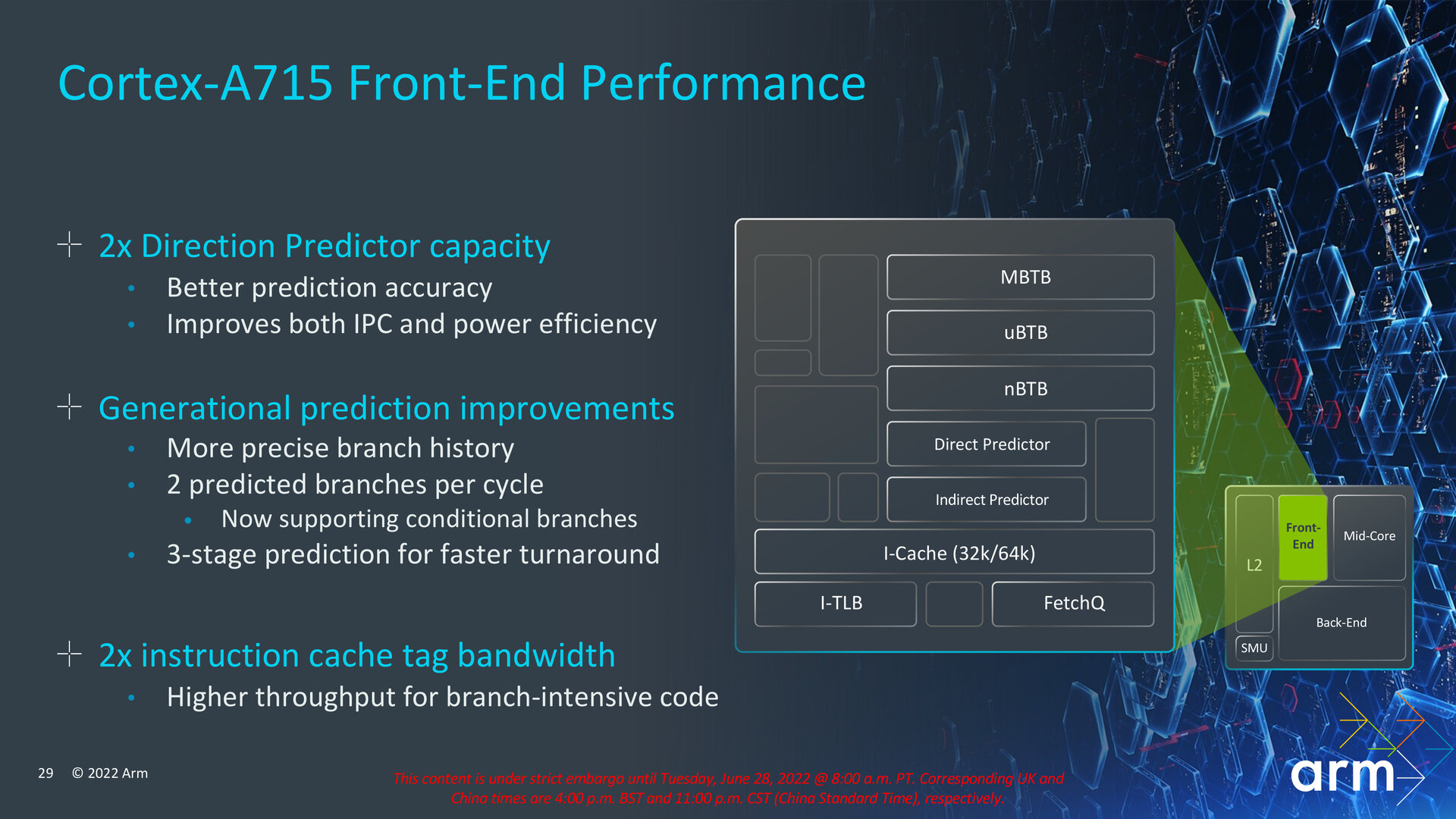
Arm hat das Front-End des Cortex-A715 bei der Sprungvorhersage aufgebohrt und stellt in diesem Bereich jetzt zwei Prädiktoren zur Verfügung: einmal für direkte und einmal für indirekte Sprünge, bei denen zwischen mehr als zwei Branches gewählt werden kann. Mit dieser Maßnahme will Arm sowohl IPC als auch Energieeffizienz steigern. Präziser soll zudem die Historie vorheriger genommener Sprünge und deren genommener Ziele ausfallen. Außerdem werden im überarbeiteten Front-End zwei Branches pro Takt und dabei auch bedingte Branches unterstützt, die in Abhängigkeit zu einer Kondition stehen. Darüber hinaus hat Arm die Bandbreite für Instruction-Cache-Tags verdoppelt, was vor allem Code mit vielen Verzweigungen beschleunigen soll.
Cortex-A715 ist ein reiner 64-Bit-Kern
Einen deutlichen Zugewinn in puncto Effizienz dürfte der Cortex-A715 durch den Wegfall von AArch32-Instruktionen erfahren, die beim Cortex-A710 noch für EL0, also für Applikationen unterstützt wurden. Der Cortex-A715 ist damit nach dem Cortex-X2 und dem neuen Cortex-X3 ein reiner 64-Bit-Kern, sodass nur noch der Cortex-A510 Refresh in einer optionalen Konfiguration für AArch32 übrig bleibt. Sie wird allerdings nur für Legacy-Geräte und Märkte wie Schwellenländer angeboten, wo besonders günstige Geräte auch mit SoCs erwartet werden, die zum Beispiel lediglich mit vier Cortex-A510 laufen. Durch den Wegfall von AArch32 fallen die Decoder des Cortex-A715 viermal kleiner als beim Vorgänger aus, was sich entsprechend positiv auf die Die-Fläche und den Energieverbrauch auswirkt.

Decoder im Mid-Core beherrschen alle Instruktionen
Die eingangs erwähnte minimale Vertiefung der Decoder-Stufen betrifft eine Erweiterung von vier auf fünf, wo neuerdings außerdem Mop-Cache-Features wie das Zusammenführen von Instruktionen direkt im Instruction-Cache unterstützt werden. Denn den Mop-Cache spart sich Arm diesmal beim Cortex-A715, weil dem Unternehmen zufolge der Instruction-Cache jetzt dieselben Features bei weniger Energieverbrauch und Fläche liefere. In der Breite wächst der Kern nicht, aber der bereits erwähnte höhere Durchsatz im Mid-Core ergibt sich daraus, dass jetzt alle Decoder alle Arten von Instruktionen durchführen können, was NEON, SVE und SVE2 zugutekommen soll.
Back-End reduziert DRAM-Zugriffe
Im Back-End baut Arm die Warteschlange für Load-Befehle aus und verdoppelt für den Data-Cache die Speicherbänke, um die Nebenläufigkeit von Schreib- und Lesevorgängen zu steigern. 50 Prozent mehr Einträge nehmen zudem die „Translation Lookaside Buffer“ (TLB) für den L2-Cache auf. Die Genauigkeit beim Vorladen von Daten (Prefetching) aufwärts in der Speicherhierarchie sei zudem gesteigert worden, was der Leistung zugutekomme, aber auch die DRAM-Zugriffe des Cortex-A715 reduziere, was abermals dem Verbrauch hilft.
-
 Back-End des Cortex-A715 (Bild: Arm)
Back-End des Cortex-A715 (Bild: Arm)
Cortex-A510 erhält einen Refresh
Die Veränderungen am Cortex-A510 halten sich insofern in Grenzen, als dass Arm dem Kern genau genommen nicht einmal einen neuen Namen spendiert. Während der Präsentation in Austin war lediglich vom Cortex-A510 Refresh oder vom Cortex-A510 (2022) die Rede. In den von Arm freigegebenen Folien heißt der Kern hingegen nur Cortex-A510 und die letztjährige Ausführung wird Cortex-A510 (2021) genannt.
Verbrauch fällt um bis zu 5 Prozent
Für den neuen Cortex-A510 gibt es nicht näher erläuterte Optimierungen mit positiver Auswirkung auf den Energiebedarf, den Arm mit minus 5 Prozent für SPECin_base2006 und minus 4 Prozent für DGEMM („Dense Matrix Multiplication on FP64“) angibt.
Takt darf höher ausfallen
Arm nennt darüber hinaus Frequenzoptimierungen und setzt die maximale Taktfrequenz (Fmax) 5 Prozent oberhalb des Cortex-A510 (2021) an, liefert aber keine absoluten Zahlen, weil diese nur vertraulich den Partnern mitgeteilt werden. In den Fußnoten der aktuellen Präsentation ist der alte Cortex-A510 für Vergleiche mit der neuen Ausführung mit bis zu 2,1 GHz zu finden, allerdings handelt es sich dabei um eine FPGA-Umsetzung speziell für einen ISO-Process-Vergleich. An anderer Stelle ist der Kern mit 2,0 GHz zu finden.

Arm erklärte auf Nachfrage, dass die Angaben in der Präsentation konservative Schätzungen möglicher Umsetzungen bei Partnern seien. Das Unternehmen gehe davon, dass die Taktraten in der Praxis vor allem unter Berücksichtigung neuer Fertigungsprozesse höher ausfallen werden. Über den bis zu 5 Prozent höheren Fmax können Partner ein Leistungsplus mitnehmen oder früher die bisherigen Taktraten erreichen und Energie sparen.
Wo letztlich der Sweet Spot aus Leistung und Effizienz liegen wird, hängt jeweils vom Anwendungsfall, thermischen Restriktionen und der Cluster-Konfiguration der Implementierungen ab. Bisherige Implementierungen des Cortex-A510 (2021) in einem 1+3+4-Cluster setzten den Takt oftmals bei maximal 1,8 GHz fest. Für den neuen Cortex-A510 ist angesichts der Aussagen von Arm von einem höheren Maximaltakt bei vielen Implementierungen auszugehen.
32 Bit kann nur noch der Cortex-A510
Neu für den diesjährigen Cortex-A510 ist der Support von Asymmetric MTE und Enhanced PAN, das zu Beginn des Artikels erläutert wurde. Darüber hinaus lässt sich der Kern noch für AArch32 konfigurieren, was für Legacy-Geräte und gewisse Märkte angeboten wird. Arm hat dabei vor allem China im Blick, weil dieser Mark mit seinen verschiedenen App-Stores dem Google-Play-Ökosystem hinterherhinkt, das seit 2019 entsprechende Apps für neue Uploads und Updates voraussetzt. Im letzten Jahr lag AArch32 noch für den Cortex-A710, aber nicht für den Cortex-A510 vor. Diese optionale Konfiguration rutscht damit eine Stufe nach unten und ist jetzt auf die kleinsten Kerne beschränkt. 32-Bit-Apps können damit ausschließlich noch auf dem Cortex-A510 ausgeführt werden, wenn dieser entsprechend vom Chip-Hersteller konfiguriert wurde.
ComputerBase hat Informationen zu diesem Artikel von Arm im Rahmen einer Veranstaltung des Herstellers in Austin, Texas unter NDA erhalten. Die Kosten für Anreise, Abreise und Hotelübernachtungen wurden von dem Unternehmen getragen. Eine Einflussnahme des Herstellers auf die oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.