AMD Ryzen 9000 & AI 300: Details zu Zen-5-Kernen, Leistung, RDNA 3.5, XDNA 2 und mehr

Ryzen 9000 startet am 31. Juli. Doch schon heute gibt es technische Details zu den Desktop-Modellen als auch zu Strix Point für Notebooks. Zum AMD Tech Day 2024 rund um Zen 5 und Co. gab es dann technische Ausblicke auf all das, was nun in Kürze kommt – und in den nächsten Jahren.
AMD lud nach LA und fast alle waren da
Zum AMD Tech Day 2024 hatte sich in Los Angeles in der letzten Woche die technische Elite des Unternehmens der Presse gestellt. Angeführt von Mark Papermaster, CTO und Nummer 2 im Konzern, waren nicht nur die Chefs vieler Sparten mit dabei, sondern auch die Ingenieure, die die Architekturen entwickelt haben. Und so gesellten sich Urgesteine wie Joe Macri dazu, CTO für Ryzen und Radeon, und natürlich Mike Clark, der „Godfather of Zen“. Denn sein Baby ist nun in fünfter Generation erschienen und Zen 6(c) sowie Zen 7 liegen im Plan – offiziell erstmals auf dem Event auch unter diesem Namen bestätigt.
-
 Granite Ridge vom AMD Tech Day 2024
Granite Ridge vom AMD Tech Day 2024



























Doch vor Ort ging es primär erst einmal um Zen 5 und die Produkte Granite Ridge alias Ryzen 9000 im Desktop, aber vor allem um Strix Point alias Ryzen AI 300 für Notebooks. Der Veranstaltung war erneut klar anzumerken, dass dies das wichtigere Produkt ist, denn im Notebook-Markt werden hohe Volumina erzielt und entsprechende Umsätze generiert. Und mit Strix Point sieht das so gut aus wie noch nie zuvor bei AMD. Dies ist den Anstrengungen der letzten vier Jahre zu verdanken, erklärten die Chefs.
Mark Papermaster als CTO des Unternehmens hob hervor, dass AMD nun nicht mehr Hard- und Softwarehersteller sei, sondern sich auf dem Weg zu einem „Holistic Design“ befinde. Bereits seit einem halben Jahr stellt sich der Hersteller öffentlich in diese Richtung auf, die im Grunde genommen alle Bereiche von der Entwicklung inklusive Prozess-Nodes und der Fertigung samt Stacking bis hin zur Hard- und Software in allen Bereichen einschließe – die MI300-Familie sei ein erster Schritt dahin.
Der Ansatz sei nötig, um die gewaltigen Kostensteigerungen in den Griff zu bekommen. Dafür werde AMD auch etwas geben, erklärte Papermaster, so wie zuletzt beim vorgestellten Ultra Accelerator Link, der auf der Infinity-Fabrik-Technologie basiere, die AMD gesponsort hat.

AMD über Intel, Apple, Arm und X3D
Joe Macri fügte in einem 1:1-Interview mit ComputerBase hinzu, dass nun, entgegen früheren Jahren, nicht mehr Intel der Gegenspieler sei, den man primär im Auge hat, sondern Apple. Denn warum solle man auf das gleiche Niveau oder gar auf ein schlechteres zurückschauen, erklärte er mit einem Lachen – Qualcomm äußert sich dieser Tage genauso.
Bei Apple hingegen seien einige Dinge doch viel ausgefeilter. Doch nicht alles, was Apple mache, könne AMD umsetzen: Apple verkauft keine Chips, sondern ein ganzes System. So können sie Dinge ganz anders umsetzen – er würde es auch so machen, wenn er an dieser Stelle stehen würde, erklärte Macri weiter.
Mike Clark, Chefarchitekt von Zen, führte aus, was zuletzt ebenfalls mehrfach zu hören war: Es komme nicht auf die Instruction set architecture (ISA) an, sondern auf das, was man daraus mache. Der gern genannte Vorteil von Arm sei deshalb oft nur ein großer Mythos, auch mit x86 könne so etwas gebaut werden. Denn Arm habe schließlich nicht nur Vorteile, sondern liege in anderen auch zurück, führte Clark weiter aus. Am Ende gehe es um die vier wichtigen Dinge, die bei einem Design berücksichtigt werden müssten: Leistung pro Takt (IPC), Takt, Stromverbrauch und Platzbedarf. Und genau dann koche auch Arm schnell nur noch mit Wasser.
Schnell stellte Clark dabei auch klar, dass es keine IPC-Wall bei x86 gebe. Ja, Moores Law sei nicht mehr genau so wie früher, aber trotzdem gebe es auch heute und in Zukunft stets deutliche Weiterentwicklungen, selbst auf IPC-Ebene. Hier und heute ist die fünfte Zen-Generation am Start und zeige das erneut, erklärte Clark sichtlich stolz. Und in Kürze kommt Zen 5 als X3D-Variante – diese brauche erneut etwas länger aufgrund der Fertigung und Validierung. Man halte hier nichts künstlich zurück. Exakt deshalb kommt heute – genauer gesagt am 31. Juli – auch schon Zen 5, selbst ohne neue Mainboards. Was fertig ist, soll eben einfach raus.
Die technischen Details waren im Rahmen des Tech Days aber noch nicht so ausführlich wie in der Vergangenheit. Einige Dinge hebt sich AMD für spätere Termine auf. Und dennoch gab es bereits viele weitere Informationen zu Zen 5 in LA.
Die Zen-5-Architektur im Überblick
Mark Papermaster und Mike Clark waren es dann natürlich auch, die mehr Details zu Zen 5 offenbarten. Was auf den ersten Blick nach einem kleinen Update aussieht, hat unter der Haube nämlich doch einige deutliche Überarbeitungen erfahren. Clark stellte diesbezüglich direkt klar, dass Zen 5 und seine Anpassungen die Basis für die nächsten Generationen legen werden.

SMT ist bei AMD weiterhin gesetzt
Nachdem Intel bei Lunar Lake die SMT-Funktionalität (bei Intel Hyper-Threading genannt) in den P-Cores nicht mehr anbietet und das im Desktop bei Arrow Lake auch so sein wird, stellte AMD im Rahmen des Events noch einmal seine Ansicht klar: Die eigene Implementierung sei noch immer so gut, dass sie überall angeboten werde. Denn mit nur 5 bis 10 Prozent zusätzlicher Flächennutzung könne man 20 bis 50 Prozent zusätzliche Leistung erhalten.
Zu Intels Entscheidung wollte er sich nicht direkt äußern, indirekt war es aus seiner Sicht stets etwas schwierig, P-Cores mit SMT und E-Cores ohne SMT zu sehen, was laut seiner Meinung nicht ideal sei und Probleme verursacht haben könnte. Natürlich funktioniert SMT nicht in jeder Anwendung, das wird sich auch nicht ändern. Aber unterm Strich ist und bleibt es die Wahl für beste Leistung. Und beim Kunden kommt so mehr Leistung pro Dollar an.
Im Front End gibt es nun einen Dual-Decoder-Path
Im Front End bringt auch Zen 5 zuallererst eine verbesserte TAGE-Sprungvorhersage. Diese ist nicht nur akkurater und zuverlässiger und sogar bei geringer Latenz arbeitend, sondern es werden auch mehr Vorhersagen per Cycle getroffen. Um sie dann auf dem weiteren Weg vom Micro-Op-Cache und Decoder verarbeiten zu können, wurde an vielen Stellen ein dualer Port implementiert. Unterm Strich soll die Leistung in dem Bereich so deutlich oberhalb von Zen 4 rangieren. Es werden über ein zusätzlich auch breiteres Interface mehr Instructions per Clock zum Back End geliefert.

Das Back End wird breiter und setzt auf volles AVX-512
Der optimierte Dispatch zum Back End ist nun acht Instruktionen breit. Damit wird das ganze Interface breiter; es können mehr Befehle auf einmal bearbeitet werden, die das verbreiterte Front End liefert – wieder einmal geht es Hand in Hand, auch durch neue Unified Scheduler in dem Segment. Doch in dem Bereich greifen dann auch Neuerungen, wenn die Sprungvorhersage und der Dispatch ins Leere laufen: Diese Fenster wurden ebenfalls vergrößert, sodass nicht zu viel Energie verloren geht und die Performance entsprechend hoch bleibt. Das sogenannte „Execution Window“ wurde deshalb um 40 Prozent auf 448 Instruktionen vergrößert.

Helfen wird dabei ebenso der optimierte Cache, der um 50 Prozent größer ist als zuvor: statt 32 nun 48 KByte. Das Problem bei einer Vergrößerung eines Caches ist in der Regel, dass dadurch die Latenz ansteigt. AMD konnte diese mit einigen Kniffen selbst für die 48 KByte L2D-Cache bei 4 Loads per Cycle belassen, ein phänomänaler Job, wie Papermaster entsprechend Lob für das Team aussprach.

Weitere Anpassungen umfassen die Datentransferraten, die nun in dem Bereich zur Verfügung stehen. Für 512-Bit-Instruktionen in der FPU steht die doppelte Bandbreite aus dem L1-Cache bereit. Der L2-Cache zieht mit und liefert die doppelte Bandbreite in Richtung L1-Cache.

Davon und ohnehin profitiert die neue AVX-512-Einheit, nun auch „512-bit AI Datapath“ genannt – dem Hype sei Dank, sei sie nun wichtiger als je zuvor, betonte Papermaster. Die sogenannte Math Unit rückt das Ganze weiter in den Fokus, da viele Befehle und Instruktionen eben genau in diesen Bereichen (Gaming, HPC, Content-Creation etc.) zu Hause sind. Aus einen Double-Pumped-256-Bit-Einsatz wird mit Zen 5 ein physischer Datenpfad, der bei vollem Takt von 5,7 GHz AVX-512 bietet. Weiterhin wird aber das bekannte Datenformat unterstützt, es kann also auch zweigeteilt mit 2 × 256 Bit vorgegangen werden – je nachdem, was sich anbietet. Die Überarbeitung der AVX-Einheit hat im Übrigen weitere Optimierungen im Gepäck: „Floating Point ADD“ (FADD) ist nun 2 Cycles schnell statt zuvor 3 – bei diesen Werten eine herausragende Leistung. Dadurch und mit weiteren Optimierungen bei der Bandbreite in Richtung des Load-Store-Bereichs entsteht eine extreme leistungsstarke FPU.
+16 Prozent IPC dank der Ausbauten
Dass am Ende ein durchschnittliches Plus von 16 Prozent als IPC-Wachstum steht, verdankt man ebendiesen vielen Optimierungen und Ausbauten. 34 Prozent des Leistungszuwachses von Zen 5 gegenüber Zen 4 kommen aus der breiteren Execution-Pipeline. Auf den Decoder und den Op-Cache entfallen 27 Prozent. Auch die gesteigerte Bandbreite macht nochmal rund 27 Prozent aus. Der Rest landet im Bereich Sprungvorhersage und Co.



Natürlich ist die AVX-Einheit dabei ein Zugpferd. Dies zeigt sich im AES-XTS-Test von Geekbench, der im Single-Core-Test bei gleichem Takt um 35 Prozent zulegt – das zieht den gesamten Geekbench-Score über den Durchschnitt. Aber auch andere Apps ziehen in diesem Bereich mit. Andere klassische Single-Core-Anwendungen liegen etwas darunter, Browser-basierte mit rund 12 Prozent IPC-Wachstum gegenüber Zen 4 eher auf der anderen Seite.
TSMC-Fertigung primär in N4P, später ein Zen 5 in N3
Die Umsetzung erfolgt weiter bei TSMC. Der Fertigungsschritt N4P ist hier der Hauptprozess. Dort wurde der Metal-Stack entsprechend darauf angepasst, eine höhere Performance zu liefern und gleichzeitig auf weniger Widerstände zu treffen. EDA- und CAD-Partner halfen ebenfalls dabei, dass die Energieeffizienz stimmig ist – vor allem in Bezug auf Strix Point. Und auch die Modularität wurde berücksichtigt: Zen 5 kommt überall hin, vom Server bis in den Embedded-Markt, und mittendrin der Desktop und das Notebook.

Das Thema 3 nm schnitt AMD in einer späteren Session leicht an: Aktuell sei es viel zu teuer und eher für ein Produkt gedacht, das mehr bringt – also einen Markt, der viel Geld zahlt. Alle Produkte dieses Jahres dürften auf N4P basieren.
Auf Zen 5 folgt Zen 6 folgt Zen 7
Eine Roadmap nicht nur zu zeigen, sondern auch umzusetzen – darauf ist AMD stolz und bleibt hier weiter so am Ball, betonte die Nummer 2 des Unternehmens. Ein Team kümmere sich um das aktuelle Produkt, ein weiteres arbeite am nächsten und eines am übernächsten. Und es werde nicht nur versprochen, es auszuliefern, sondern on time auch wirklich verschickt. Und so geht es mit den kommenden Lösungen weiter, versprach Papermaster.

RDNA 3.5 ist ein Effizienz-Update dank Samsung
RDNA 3.5 ist keine neue Lösung an sich. Es ist ein expliziter Sidestep hin zu einer Grafikeinheit, die für den mobilen Markt gedacht ist. Die Ideen dazu stammen unter anderem aus der Zusammenarbeit mit Samsung. Dort wird seit einiger Zeit im Smartphone-Chip auch auf RDNA-IP für mobile Lösungen zurückgegriffen. Also erkannte AMD: Was im Smartphone funktioniert, klappt zum Teil auch für das Notebook.

Im Fokus standen also eine deutlich gesteigerte Effizienz sowie eine geringere Leistungsaufnahme nicht nur für die Shader-Einheiten und das Drumherum, sondern insbesondere auch für das Speichersystem. Denn Speicherzugriffe sind traditionell sehr energiehungrig. Der Fokus auf LPDDR5 und ein optimiertes Cache-System, das Speicherzugriffe verringern kann, sparen am Ende viel Strom ein. Unterm Strich steht so ein zweistelliges Wachstum bei der Leistung. Im 3DMark sind es bis zu 32 Prozent von Strix Point gegenüber dem Vorgänger Hawk Point bei 15 Watt.


Unter der Haube hat AMD etwas für die Parallelisierung getan. Einige der wichtigen Einheiten sind nun doppelt vorhanden, diese Vorgehensweise hilft erfahrungsgemäß bei der Effizienz. So gibt es nun eine doppelte Texture-Sampler-Rate, die ein großes Leistungsplus in Spielen mit vielen Texturen bringen kann. Auch im Shader-Subsystem gab es Arbeit: Verdoppelte Pixel-Interpolation und Comparison-Rates bringen mehr Performance.

Wenn etwas im Bereich der Rasterization nun in noch kleinere Stücke geteilt wird, muss davon nicht jedes einen Umweg über den Speicher gehen, denn kleinere Stücke liegen oft einfach im näheren und schnelleren Cache – das spart Energie. Speicher ist bei Grafik-Anwendungen einer der größten Energiefresser. Gepaart mit einer noch besseren Kompression von Daten sollen die Speicherzugriffe so minimal wie möglich ausfallen.
Die neue XDNA-2-Architektur für Ryzen AI
Eine der großen Neuerungen neben Zen 5 ist die XDNA-2-Architektur, die quasi auch die Basis für die neue Produktbezeichung ist: Ryzen AI. In Strix Point, also den neuen Notebook-Chips, wird sie debütieren, später aber auch in andere Produkte integriert. Zum Start stellt AMD deshalb gleich noch einmal klar, dass eine NPU primär für sehr effizientes Arbeiten gedacht ist, nicht für maximale Leistung. In der Metrik Performance pro Watt gewinnt eine NPU deutlich.

Und genau so geht XDNA 2 das Thema dann auch an. Der Ursprung der neuen Lösung ist sechs Jahre alt, da begann im Embedded-Segment die Entwicklung für diese Beschleuniger-Lösungen. XDNA 2 ist von nun an ein großes Update der bisherigen Lösungen, behält aber seine Wurzeln bei. Das beginnt beispielsweise schon beim Aufbau: AMDs AI Engine setzt auf einen Mesh-Aufbau. Der große Vorteil ist die flexible Partitionierung der einzelnen AIE-Tiles, sodass mehrere Aufgaben mit den ihnen zugewiesenen Ressourcen bearbeitet werden können.



Gegenüber XDNA setzt XDNA 2 nun nicht mehr nur auf 20, sondern auf 32 dieser AIE-Tiles. Zusammen mit zwei MACs pro Tiles und dem 1,6-fachen Speicher kommen am Ende 50 TOPS statt bisher lediglich 10 TOPS an rechnerischer Leistung heraus. Und das auch noch viel effizienter.

Block FP16 ist das Ding für AMD XDNA 2
Die hohe Leistung wird im neuen Datentyp „Block Floating Point 16“, kurz „Block FP16“, erzielt. Dier verbindet eine 8-Bit-Performance mit 16-Bit-Genauigkeit – zumindest ist es ganz nahe dran. Das Wichtige an diesem Ansatz ist, dass so nur rund 56 Prozent des ursprünglichen Speicherbedarfs benutzt werden, was Energie spart und vor allem im mobilen Segment nicht unwichtig ist.

Die 50 TOPS an gebotener Leistung von XDNA 2 sind also sowohl Block FP16 als auch INT8. In den ausgewählten Szenarien spielt das neue Datenformat seine Stärken aus. In Grenzbereichen fällt Block FP16 dann aber mitunter auf INT8-Niveau zurück.



Das verdeutlicht dann auch direkt, dass der Vergleich von TOPS einmal mehr kaum möglich ist. Echte Benchmarks für das Segment, die alle Datentypen unterstützen, sind quasi nicht verfügbar und sollen es laut AMD in diesem Jahr auch kaum werden. Zu schnell werden große Schritte absolviert, die Software kommt in vielen Bereichen kaum hinterher. Neuen, angepassten Datenformaten gehört jedoch die Zukunft, glaubt AMD. Das Unternehmen will hier mithalten und mindestens jedes Quartal ein neues großes Software-Paket liefern. Das große Ziel ist ein Unified-AI-Softwarestack, der jedoch erst 2025 erscheinen dürfte und nur für Entwickler als Alpha noch dieses Jahr kommen soll.


Dass AMD sich so fünf Mal schneller als Intel Meteor Lake sieht, überrascht angesichts von 50 TOPS vs. 10 TOPS nicht. Da Lunar Lake aber schon vorgestellt ist und nun auch in Kürze verfügbar wird, ist der Gegenspieler ein anderer. Intel dürfte in seinen eigenen Benchmarks vermutlich dann auch Grenzwerte zeigen, in denen Block FP16 eben nicht überzeugen kann und zurückfällt. Wie üblich sind Hersteller-Benchmarks eben nur das Beste für das eigene Produkt.

AI ist jedoch gekommen, um zu bleiben. Nicht nur im kleinen PC, sondern vor allem im Enterprise- und Geschäftsumfeld. Hier liegt das große Geld, es werden viele Generationen erwartet und die Entwicklung weiter vorantreiben.


Strix Point ist das Aushängeschild aller Neuheiten
Auf dem AMD Tech Day 2024 wurde an nahezu jeder Stelle deutlich, dass Ryzen AI 300, Codename Strix Point, das Aushängeschild ist. Es ist die einzige Lösung, die keine Kompromisse eingehe und Neuheiten überall biete. Dies alles funktioniere aber erst mal nur unter Windows 11, AMD lobte Microsoft an vielen Stellen teils überschwänglich. Angesichts der Probleme beim Qualcomm-Start vor wenigen Wochen hinterließ das vor Ort einen eher mulmigen Eindruck. Denn den Start der neuen Lösungen dort hat letztlich eher Microsoft torpediert.


Der beste Notebook-Start von AMD erwartet
Doch nicht nur Windows ist wichtig: Für Notebooks sind es vor allem die OEMs, die die Chips verbauen und Lösungen präsentieren. Selten zuvor – oder gar noch nie – stand AMD zu einem Start im Notebook-Segment so gut da wie mit Strix Point. Phoenix und Hawk Point haben hier die Grundlagen gelegt, auf die Strix Point nun aufbaut. Von den 300 Notebook-Designs, die die drei Ryzen-AI-Generationen Phoenix, Hawk Point und Strix Point in sich vereinen, werden über 150 auf Strix Point entfallen.

Zu den Launch-Partnern werden Acer, Asus + ROG, HP, Lenovo, MSI und Razer zählen. Vor allem Asus schiebt sich einmal mehr, so wie in den letzten Jahren üblich, als wichtigster Partner zum Start an. Asus war letztlich auch der einzige Partner, der auf der Bühne zu sehen war und sein Portfolio von Vivobook über Zenbook bis ProArt vorstellen durfte, was jedoch quasi der kompletten Computex-2024-Vorstellung des Unternehmens entsprach.
Bruchstücke an technischen Details
Strix Point vereint alle neuen Möglichkeiten, die bereits abgehandelt wurden. Gegenüber dem Vorgägner gibt es mehr Kerne, mehr Cache sowie eine größere GPU und natürlich auch NPU. Einen echten technischen Deep Dive ersparte sich AMD und verkaufte lieber die AI-Features und das Komplettpaket.

Im Laufe der Stunden an Sessions kamen diese immer nur in Bruchstücken zum Vorschein. Dabei wurde deutlich, dass Strix Point die bisher größte APU von AMD ist und rund 20 Prozent mehr Fläche belegt als der Vorgänger, immerhin allerdings im gleichen Sockel FT8 als BGA-Chip verlötet wird. Dafür war ziemlich viel Arbeit nötig, erklärte AMD, die bis in die kleinste Ebene des Packages gehen musste. In diese nun deutlich teurere Rechnung floss bereits mit ein, dass es nun auch weniger PCIe-Lanes gibt als beim Vorgänger – 16 (statt 20) sind einfach die gängige Wahl in diesem Segment, erklärt der Hersteller, und Platz sparen sie eben auch.
Das Konstrukt aus Zen 5 plus Zen 5c sei so die beste Möglichkeit, im mobilen Umfeld Leistung zu bieten, aber auch nicht zu viel Energie zu verbrauchen. Erneut gibt es dabei keinerlei IP- oder IPC-Unterschiede. Ein kleiner Kern (Compact Core, Zen 5c) kann genau das Gleiche wie ein großer, taktet jedoch nie so hoch. Für Strix Point rutschte deshalb auch das Powermanagement in den Fokus und wurde komplett überarbeitet.
Im Notebook soll es eben sowohl spritzig flott als auch stromsparend sein, kleine Programme wie Teams sollen nicht den Akku leersaugen. So wurden die Voltage-Regulators überarbeitet sowie Stromsparmodi wie C8, C7 und weitere C-States angepasst (etwa C11) und in gewissen Lebenslagen genutzt – letztlich das komplette Powermanagement dynamischer gestaltet. Dem Thema Idle hat sich AMD dabei ebenfalls gewidmet, denn wie das Unternehmen erklärt: Reines Nichtstun und Stromsparen sind ziemlich schwierig umzusetzen.
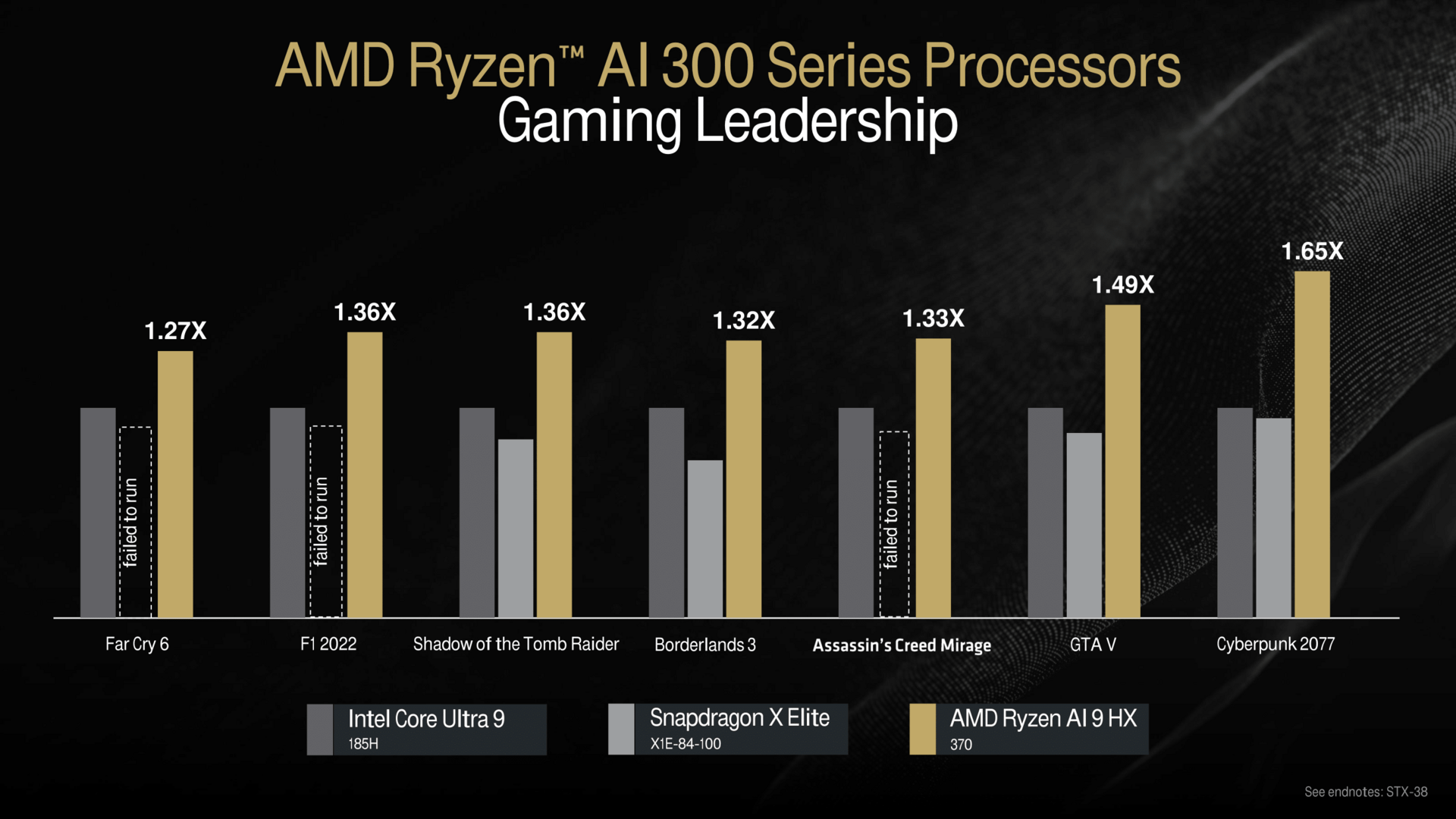
Hinsichtlich der Leistung sieht das in den AMD-Benchmarks erwartungsgemäß sehr gut aus. In Anwendungen werden Intel Core Ultra und Qualcomm Snapdragon zum Teil deutlich geschlagen, beim Gaming mitunter noch mehr – Snapdragon läuft hier bekanntlich oft gar nicht. Auch Apple zieht AMD hier zum Vergleich mit heran, die CPU- und vor allem die AI-Leistung liegen demnach weit über Apples M-Chips.


Granite Ridge kommt als Ryzen 9000 am 31. Juli
Granite Ridge war letztlich das kleinste Thema beim Event, so kurios das für einige Leser speziell auch auf ComputerBase sein mag. Der klassische Desktop bleibt bei AMD zwar wichtig, betonte das Unternehmen, doch alles andere ist eben noch ein wenig wichtiger. Und so war Granite Ridge alias Ryzen 9000 letztlich quasi das Schlusslicht.

Ryzen 7 9700X bleibt bei 65 Watt und wird „effizienter“ als 5800X3D
David McAfee als einer der führende Köpfe in dem Segment macht dabei gleich zum Start klar, dass die Gerüchte über eine TDP-Steigerung des 9700X Bogus seien. Gerade dieses Modell solle über die Effizienz extrem punkten können. Dies veranlasste den Hersteller sogar bereits zu einigen komischen Aussagen: Der AMD Ryzen 7 9700X solle im Gaming viel effizienter sein als ein AMD Ryzen 7 5800X3D. Verglichen wurden dabei aber keine echten Verbrauchswerte, sondern TDPs: 65 zu 105 Watt des alten Modells. Hier am Ende letztlich nur 12 Prozent im Durchschnitt vorn zu liegen, ist irgendwie dann so gar keine Errungenschaft mehr. Schließlich verbraucht der 5800X3D in Spielen realistisch gesehen auch eher nur 65 Watt, wie es ComputerBase bereits mehrfach gemessen hat.

Alle neuen CPUs glänzen gegenüber Intel, AMD „vergisst“ den 9950X
Auch AMD Ryzen 9 9900X soll genüber Intel einen Vorsprung herausarbeiten – sowohl in Anwendungen als auch in Spielen. Und das Gleiche gilt für einen 9700X gegenüber einem 14700K oder einem 9600X gegenüber einem 14600K.



Doch ein Modell fehlte in AMDs Angaben stets: das Flaggschiff AMD Ryzen 9 9950X. Auf keiner Folie außer der Übersicht wurde der Prozessor bedacht, später im Show-Demo-Room war er zumindest einmal zu finden, der Großteil aber auch hier mit kleineren CPUs unterwegs. Entweder vermittelt AMD hier, dass nun also schon ein Zwölfkerner reicht, oder spart sich beim 9950X noch etwas anderes auf. Denn dass er triumphieren kann, zeigte am Ende wenigstens ein kleines Übersichts-Slide, in dem sich AMD im Haus bei den TDPs und der Leistung verglich. Denn der höchste Balken steht nun ausgerechnet beim Ryzen 9 9950X gegenüber dem Vorgänger 7950X.

Das zuvor bereits angesprochene angepasste Design der Zen-5-Architektur schlägt sich bei Granite Ridge nieder. Eine deutlich geringere Thermal.Resistance führt hier nun zu deutlich kühleren Chips. Von den Ryzen 7000 hat AMD auch viel über die Hotspots in den Chips gelernt. Eine bessere Positionierung von Sensoren und verbesserte Algorithmen helfen ebenfalls, stets das Optimium erreichen zu können. Davon profitieren die Chips letztlich und lassen eine geringere TDP zu und liefern trotzdem mehr Performance.

Die Maximaltemperatur bleibt aber bei 95 °C, sodass die CPUs letztlich also bei gleicher Zieltemperatur schlichtweg mehr Takt bieten können – das erklärt schnell den Vorsprung des 9950X gegenüber dem 7950X. Anzumerken ist hierbei allerdings, dass die Ryzen 7000 selbst mit viel geringerem Verbrauch nur etwas weniger Leistung lieferten. Die zuvor gewählte TDP war in einigen Fällen einfach schon viel zu hoch.
Overclocking von Speicher on the fly und Curve-Shaper
Neue Optionen für das Overclocking hat AMD auch im Gepäck. DDR5-Speicher kann in Ryzen Master nun im Betrieb übertaktet werden, denn das Tool lädt die Profile wie EXPO oder XMP bereits beim Start des Systems gleich mit. Alle kommenden AMD-Chipsätze werden dies unterstützen, der B840 wird jedoch nur Speicher- und kein CPU-Overclocking bieten. Default-Speicher ist DDR5-5600, der Sweetspot wird nun auf bis zu DDR5-8000 angehoben. Nach wie vor gibt es aber den bekannten internen Teiler: Bei DDR5-6400 wird von 1:1 auf 1:2 gewechselt.


Der neue Curve-Shaper erstellt anhand zusätzlicher Parameter ein Overclocking-Profil für die CPU. Dies geschieht bereits im BIOS, in ersten Varianten ist es schon implementiert. Er wird zum Start den Ryzen 9000 vorbehalten bleiben – genauso wie das neue Speicher-Overclocking. Späterere Anpassungen für Ryzen 7000 sind jedoch möglich, wenngleich AMD dies auch auf Nachfrage heute nicht bestätigen wollte.

Im Showroom führte AMD alle Möglichkeiten vor und schloss mit obligatorischem Overclocking der CPUs mit flüssigem Stickstoff. Schnell purzelten hier diverse Rekorde, wie es beim Start von neuen CPU-Generationen aber eigentlich seit Jahren üblich ist. Alles andere wäre schließlich eine Enttäuschung. Der Hersteller erklärte dabei, dass die Prozessoren zu Beginn wohl so ähnlich gehen dürften wie die bisherigen Lösungen. Streuungen in beide Richtungen sind wie üblich aber möglich.
-
 Schnappschüsse vom AMD Tech Day 2024
Schnappschüsse vom AMD Tech Day 2024














Sockel AM5 für viele Generationen, eventuell auch 8+ Jahre
Auf der Bühne erklärten die technischen Chefs von AMD zum Sockel AM5, dass dieser an den Erfolg des Sockel AM4 anschließen werde. Dieser bekommt in diesen Tagen noch einmal neue CPUs und wird so auch noch einige weitere Jahre leben. Und war für den Sockel AM5 intern ursprünglich mal eine Lebenszeit von fünf bis sechs Jahren angesetzt worden, wird daraus nun vermutlich ein Produkt für vielleicht vier Generationen und letztlich dann 8+ Jahre. Offiziell ist das jedoch nicht, erklärte AMD in einer Klarstellung wenige Stunden vor dem Fall des NDAs. Es ist vielmehr der Gedankengang – offizieller Tenor bleibt das zur Computex Gesagte: AM5 lebt bis 2027+.
Mit Ryzen 9000 werden dabei noch nicht mal viele Neuerungen auf der Plattform umgesetzt, in Zukunft sollen ein schnellerer Speicher, neue Standards rund um PCI Express und weitere Aspekte folgen. All diese Punkte wurden bei der Sockel-Infrastruktur neben der bereits bekannten höheren TDP-Unterstützung berücksichtigt. Der primäre Treiber dürfte am Ende echter neuer Speicher sein: Mit DDR6 dürfte dann auch „AM6“ erscheinen.
-
 Granite-Ridge-Systeme zum AMD Tech Day 2024
Granite-Ridge-Systeme zum AMD Tech Day 2024

































Ersteindruck und Ausblick auf Ende Juli
Selbstbewusst wie nie geht AMD in diesen Start – und das kann der Hersteller auch sein. Vor Ort in Los Angeles verkauft sich das Unternehmen sehr gut. Nicht nur unzählige Manager, sondern auch die technische Elite von AMD mischte sich unters Pressevolk, beantwortete nahezu jede Frage und ging auch auf entsprechendes Feedback ein.
Dass dabei Strix Point das Leuchtturmprojekt ist, überrascht letztlich nicht. Es ist der größte Schritt im Notebook bei AMD seit vielen Jahren und die anvisierten Designs geben dem Vorhaben direkt Recht. Es dürfte zweifelsohne eine der erfolgreichsten Notebook-CPUs werden, vor allem, wenn auch noch kleinere Lösungen als die beiden großen SKUs kommen. Was die großen Chips können, wird ein unabhängiger Test in Kürze zeigen.
Granite Ridge alias Ryzen 9000 für den Desktop dürfte ebenfalls ein äußerst solides Produkt, das die regulären Ryzen 7000 schnell in den Schatten stellt, werden. Vor allem die kleinen, aber feinen Details machen hier den Unterschied. In der Mitte werden die CPUs nicht nur schneller, sondern auch effzienter, während an der Spitze das Flaggschiff dank des optimierten Designs und somit höheren Frequenzbereichs viel mehr Leistung bieten kann. Insgesamt gibt es hier vermutlich nichts zu meckern. Intels Probleme mit den aktuellen K-CPUs könnten hier ein echter Sargnagel werden und Arrow Lake wird aktuell erst für Oktober erwartet. Wer kauft die „alten“ Intel Core also nach dem Start von Ryzen 9000 noch? Dieser Frage wird ein Test bis spätestens zum Marktstart am 31. Juli auf den Grund gehen – auch die Preise werden dann endlich offiziell genannt.
ComputerBase hat Informationen zu diesem Artikel von AMD im Rahmen einer Veranstaltung des Herstellers in Los Angeles erhalten. Die Kosten für die Flüge, drei Übernachtungen und die Verpflegung wurden von dem Unternehmen getragen. Eine Einflussnahme des Herstellers auf die oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.
