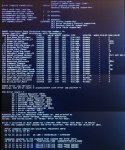
So weiter gehts:
Ich habe jetzt endlich hinbekommen die nfi.exe dazu zu überreden Daten auszuspucken. Der Trick bei mir lag komischer Weise darin die Doppelpunkte beim Laufwerksbuchstaben weg zu lassen.
Resultat:
Anmerkungen in orange
Kurzum: Keiner der fragwürdigen Sektoren gehört zu einer Datei.
Meine Schlussfolgerung: Die geklonte Partition müsste uneingeschränkt lauffähig sein, da Datenverlust nur an Stellen auftrat, an denen garkeine Daten lagen. Oder?
Was ich jetzt gerade überhaupt nicht zuordnen kann: Was bedeutet das jetzt für die M4? Sind da nun wirklich Sektoren kaputt? Bzw. wie ist diese jetzt zu bewerten?
Tatsächlich bootet die M500 eingebaut in den PC einwandfrei. Es gab keine Probleme.
Bleibt die Frage nach eurer Einschätzung und der Frage nach dem Zustand der M4.
Ich habe jetzt endlich hinbekommen die nfi.exe dazu zu überreden Daten auszuspucken. Der Trick bei mir lag komischer Weise darin die Doppelpunkte beim Laufwerksbuchstaben weg zu lassen.
Resultat:
Anmerkungen in orange
Test-File:
C:\Windows\system32>D:\Downloads\Windows_testprogs\nfi\nfi.exe C 2000000
NTFS File Sector Information Utility.
Copyright (C) Microsoft Corporation 1999. All rights reserved.
***Logical sector 2000000 (0x1e8480) on drive C is in file number 16753.
\Windows\Fonts\meiryo.ttc
$STANDARD_INFORMATION (resident)
$FILE_NAME (resident)
$FILE_NAME (resident)
$DATA (nonresident)
logical sectors 1999576-2018199 (0x1e82d8-0x1ecb97)
Clonezilla: "can’t read sector 32776228352, lost data"
C:\Windows\system32>D:\Downloads\Windows_testprogs\nfi\nfi.exe C 32776228352
NTFS File Sector Information Utility.
Copyright (C) Microsoft Corporation 1999. All rights reserved.
***Logical sector 32776228352 (0x7a19d8e00) on drive C is not in any file.
Clonezilla: "can’t read sector 64552631808, lost data"
C:\Windows\system32>D:\Downloads\Windows_testprogs\nfi\nfi.exe C 64552631808
NTFS File Sector Information Utility.
Copyright (C) Microsoft Corporation 1999. All rights reserved.
***Logical sector 64552631808 (0xf07a2fe00) on drive C is not in any file.
Clonezilla: "can’t read sector 69473664512, lost data"
C:\Windows\system32>D:\Downloads\Windows_testprogs\nfi\nfi.exe C 69473664512
NTFS File Sector Information Utility.
Copyright (C) Microsoft Corporation 1999. All rights reserved.
***Logical sector 69473664512 (0x102cf3fe00) on drive C is not in any file.
Clonezilla: "can’t read sector 82821266944, lost data"
Der Befehl "82821266944" ist entweder falsch geschrieben oder
konnte nicht gefunden werden.
C:\Windows\system32>D:\Downloads\Windows_testprogs\nfi\nfi.exe C 82821266944
NTFS File Sector Information Utility.
Copyright (C) Microsoft Corporation 1999. All rights reserved.
***Logical sector 82821266944 (0x1348883e00) on drive C is not in any file.
Kurzum: Keiner der fragwürdigen Sektoren gehört zu einer Datei.
Meine Schlussfolgerung: Die geklonte Partition müsste uneingeschränkt lauffähig sein, da Datenverlust nur an Stellen auftrat, an denen garkeine Daten lagen. Oder?
Was ich jetzt gerade überhaupt nicht zuordnen kann: Was bedeutet das jetzt für die M4? Sind da nun wirklich Sektoren kaputt? Bzw. wie ist diese jetzt zu bewerten?
Ergänzung ()
Tatsächlich bootet die M500 eingebaut in den PC einwandfrei. Es gab keine Probleme.
Bleibt die Frage nach eurer Einschätzung und der Frage nach dem Zustand der M4.