AI-Benchmarks mit Procyon: AMD Ryzen 9 und Intel Core Ultra 7 mit NPU im AI-Test
AI ist der Hype der Stunde, dessen Rechenlast vorrangig gigantische Cloud-Rechenzentren stemmen. Doch mit Windows 11 24H2 soll AI auch lokal breit ausgerollt werden. Optimalerweise kaufen Kunden dafür„AI-PCs“ mit AMD Ryzen AI oder Intel Core Ultra, deren NPUs AI effizient berechnen. Was genau das bedeutet, ergründet der Test.
AI: Cloud vs. Edge
Es ist der größte Hype in der IT-Branche der letzten Jahrzehnte, einige behaupten sogar der größte Hype überhaupt: AI. Und in der Tat bewegt Künstliche Intelligenz (KI) zurzeit mehr Geld als irgendein anderes Thema der IT-Branche und ist in Zukunft nicht mehr wegzudenken. Jeder Hersteller ist in dem Bereich aktiv – oder will/muss es noch werden.
Der Hype findet noch in der Cloud statt
Begonnen hat die Omnipräsenz der AI für die Allgemeinheit mit der Vorstellung von ChatGPT Ende 2022, dem viele weitere Large Language Models (LLM) mit ähnlichen Fähigkeiten folgten.
Im Hintergrund dieser Produkte stehen gigantische Rechenzentren in der Cloud, an denen sich insbesondere Nvidia zuletzt eine goldene Nase verdient hat und wohl auch auf absehbare Zeit noch verdienen wird, denn die anfallende Rechenlast wird vorrangig von Nvidias GPUs gestemmt. Der lokale Rechner empfängt nur das Ergebnis.
Auch Bilder lassen sich über eine AI inzwischen so einfach generieren wie nie zuvor. Einfach ein paar Schlagworte eintippen oder eine Frage stellen, schon erhält man das mehr oder weniger passende Bild. Ob Ergebnisse wie die zu den Prompts „Ein Servertechniker repariert ein von Rebellen zerstörtes Unterseekabel“ oder „The inventor of the graphics card being celebrated by people“ dem gewünschten Ergebnis entsprechen, sei einmal dahingestellt, aber auch in diesem Fall schultert die Rechenlast die Cloud – in der Regel „GPU-beschleunigt“. Dasselbe gilt für das, was der Microsoft Copilot aktuell bereits Unternehmen bietet.
-
 Flott generierte kostenfreie AI-Bilder sind oft zum Schmunzeln
Flott generierte kostenfreie AI-Bilder sind oft zum Schmunzeln


Wer sich mehr über die jüngsten Entwicklungen auf dem Bereich AI, Large Language Models oder den Risiken der AI-Revolution informieren will, findet dazu weitere detaillierte Berichte auf ComputerBase:
- Large Language Models und Chatbots: Die Technologie hinter ChatGPT, Bing-Chat und Google Bard
- Interview: Warum KI nicht die Menschheit auslöscht und wieso Open Source hilft
- Axel Springers OpenAI-Deal: Wie generative KI den Journalismus verändert
AI auf dem Desktop-PC: Ist da schon was?
In der Cloud ist AI definitiv großflächig angekommen, auf dem lokalen Desktop-PC oder Notebook sieht es aber noch anders aus. Zwar gibt es seit Jahren Anwendungen, die auf AI setzen und das betrifft nicht nur Nvidia RTX Broadcast oder andere „AI Noise Cancelling“-Anwendungen, Videokonferenz-Tools mit Gesichtserkennung oder Bild- und Audiobearbeitungssoftware. Doch breit durchdrungen haben AI-Funktionen PCs noch nicht.
Damit stehen PCs aktuell durchaus im Kontrast zu Smartphones, die mit iOS oder Android immer mehr AI-Funktionen und darunter auch immer mehr lokal berechnete bieten und oft bekommt der Nutzer davon kaum etwas mit. AI klassifiziert Fotos, wartet auf Nutzereingaben, durchkämmt E-Mails und Nachrichten nach Terminen oder Kontaktdaten.
Das ist auch ohne rapide fallend Akkulaufzeiten möglich, weil moderne Smartphones über Neural Processing Units (NPUs) verfügen. Das sind „AI-Beschleuniger“, die AI-Lasten besonders effizient erledigen, wenn die Software sie denn nutzt – und sowohl iOS/iPadOS als auch Android tun das. Windows-Systeme bieten das noch nicht.
x86: Hardware und Software müssen aufholen
Genau das will Microsoft mit Windows 11 24H2 ändern. Das große Update stellt AI nicht nur mit dem Copiloten in den Fokus, sondern wird auch massiv „AI-PCs“ bewerben, die mit einer NPU ausgestattet sind (aktuell AMD-Ryzen-CPUs mit Ryzen AI und Intel Core Ultra) und über die neue Copilot-Taste verfügen.

Ein Zwang zur NPU – ist das zu kurz gedacht? CPU, GPU oder NPU – grundsätzlich kann jede dieser Einheiten AI-Aufgaben übernehmen, wenn sie denn durch die Software korrekt adressiert wird. Die insbesondere im Notebook, aber letztendlich auch im Desktop entscheidenden Fragen sind allerdings: Wie schnell und wie effizient beziehungsweise stromsparend?
NPUs ziehen im x86-Desktop ein
Die NPUs sind speziell auf diese Aufgaben angepasst und können Berechnungen möglichst effizient erledigen. Insbesondere mit Blick auf das Notebook ergibt es daher Sinn, der NPU wie im Smartphone den Vorrang zu geben. Trotz stetig steigender Leistung gemessen in TOPS dürften große GPUs allerdings weiterhin die schnellere, wenngleich weniger effiziente Alternative sein. Immer vorausgesetzt, die jeweilige Anwendung spricht die Komponente auch korrekt an.


AMDs NPU heißt „Ryzen AI“ und ist bis dato in vielen, wenn auch nicht allen mobilen CPUs der Serien Ryzen 7000 „Phoenix“ und Ryzen 8000 „Hawk Point“ verfügbar. AMDs Ansatz lautet: Erst die Hardware breit ausrollen, dann folgt die Software. Intel und Nvidia setzen verstärkt gleich zu Beginn auch auf Software – Nvidia bekanntlich sehr proprietär und beschützend, Intel mit der Flucht nach vorn mit dem OpenVino-Open-Source-Modell. Welcher Rechner unterstützt unter welchem Windows in welcher Anwendung was? Und was bedeutet das überhaupt? Fragen, die sich auch mit Windows 11 24H2 auf einem „AI-PC“ nicht einfach beantwortet werden lassen.


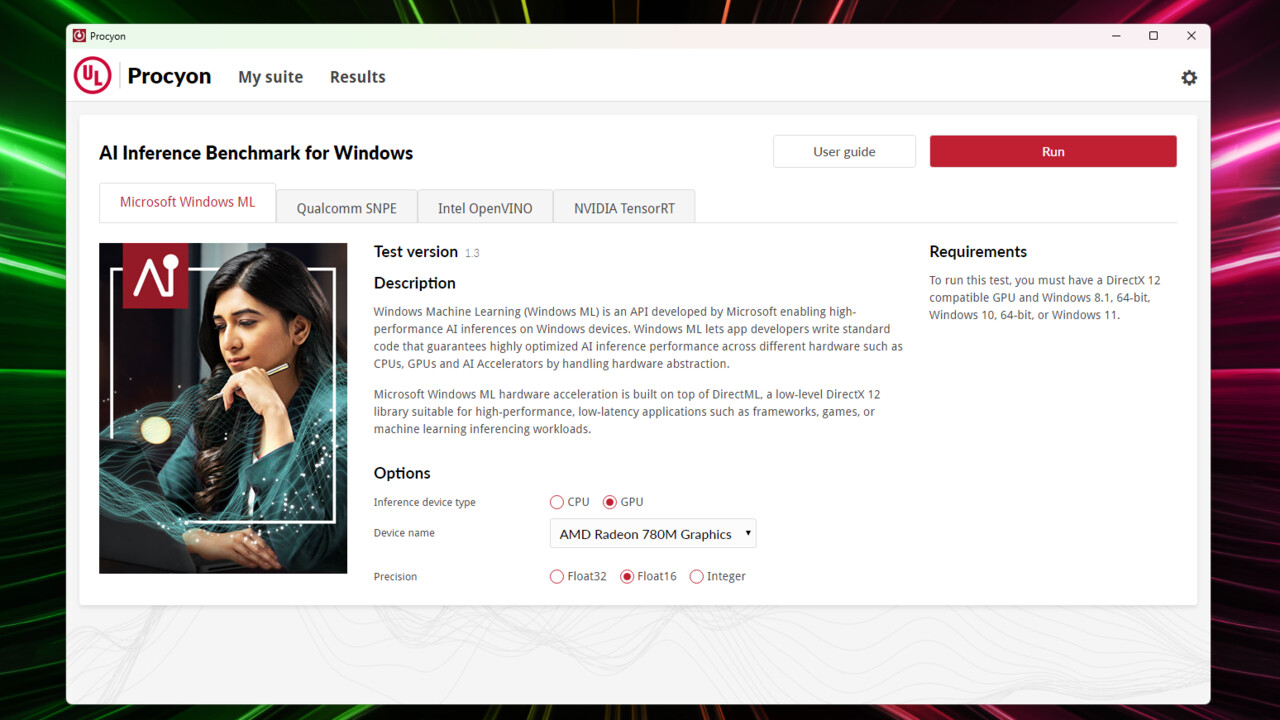
Etwas Licht ins Dunkel bringen könnte der Procyon-Benchmark von UL, den Entwicklern des 3DMark, der AI-Tests sowohl auf den drei Komponenten CPU, GPU und NPU als auch über verschiedene Softwareschnittstellen (Windows ML, OpenVino, TensorRT) ausführen kann.
UL Procyon: der Windows-AI-Benchmark
Die Procyon-Benchmark-Suite testet die AI-Leistungsfähigkeit anhand möglichst realistischer Szenarien und gibt über eine Berechnungsformel ein Endergebnis in Punkten aus.
The UL Procyon AI Inference Benchmark for Windows gives insights into how AI inference engines perform on your hardware in a Windows environment, helping you decide which engines to support to achieve the best performance. The benchmark features several AI inference engines from different vendors, with benchmark scores reflecting the performance of on-device inferencing operations.
The AI workloads used are common machine vision tasks such as image classification, image segmentation, object detection and super-resolution. These tasks are executed using a range of popular, state-of-the-art neural networks and can run on the device’s CPU, GPU or a dedicated AI accelerator for comparing hardware performance differences.

Klingt entsprechend einfach, ist es auch. Man wähle die passende Softwareumgebung, die auf der Hardware funktioniert, und mit dem Druck auf den Startknopf geht es auch schon los. Es werden sechs Subtests durchgeführt, die jeweils 3 Minuten in Anspruch nehmen, dazwischen liegen kleine Pausen. Nach rund 20 Minuten ist ein Ergebnis da, das aus sechs Inference-Testsergebnissen abgeleitet wird.
| Intel Core Ultra 7 155H | AMD Ryzen 9 8845HS | AMD Ryzen 9 8845HS + RTX 4070 | |
|---|---|---|---|
| Windows ML Test – CPU | |||
| Float32 | 42 | 117 | – |
| Float16 | 18 | 46 | – |
| Integer | 55 | 162 | – |
| Windows ML Test – GPU | |||
| Float32 | 0 (Error im letzten Test, dann alles direkt 0) | 120 | 681 |
| Float16 | 258 | 290 | 1166 |
| Integer | 56 | 68 | 267 |
| Intel OpenVINO – NPU | |||
| Float32 | 281 | – | – |
| Float16 | 281 | – | – |
| Integer | 514 | – | – |
| Intel OpenVINO – CPU | |||
| Float32 | 53 | – | – |
| Float16 | 76 | – | – |
| Integer | 211 | – | – |
| Intel OpenVINO – GPU | |||
| Float32 | 389 | – | – |
| Float16 | 388 | – | – |
| Integer | 593 | – | – |
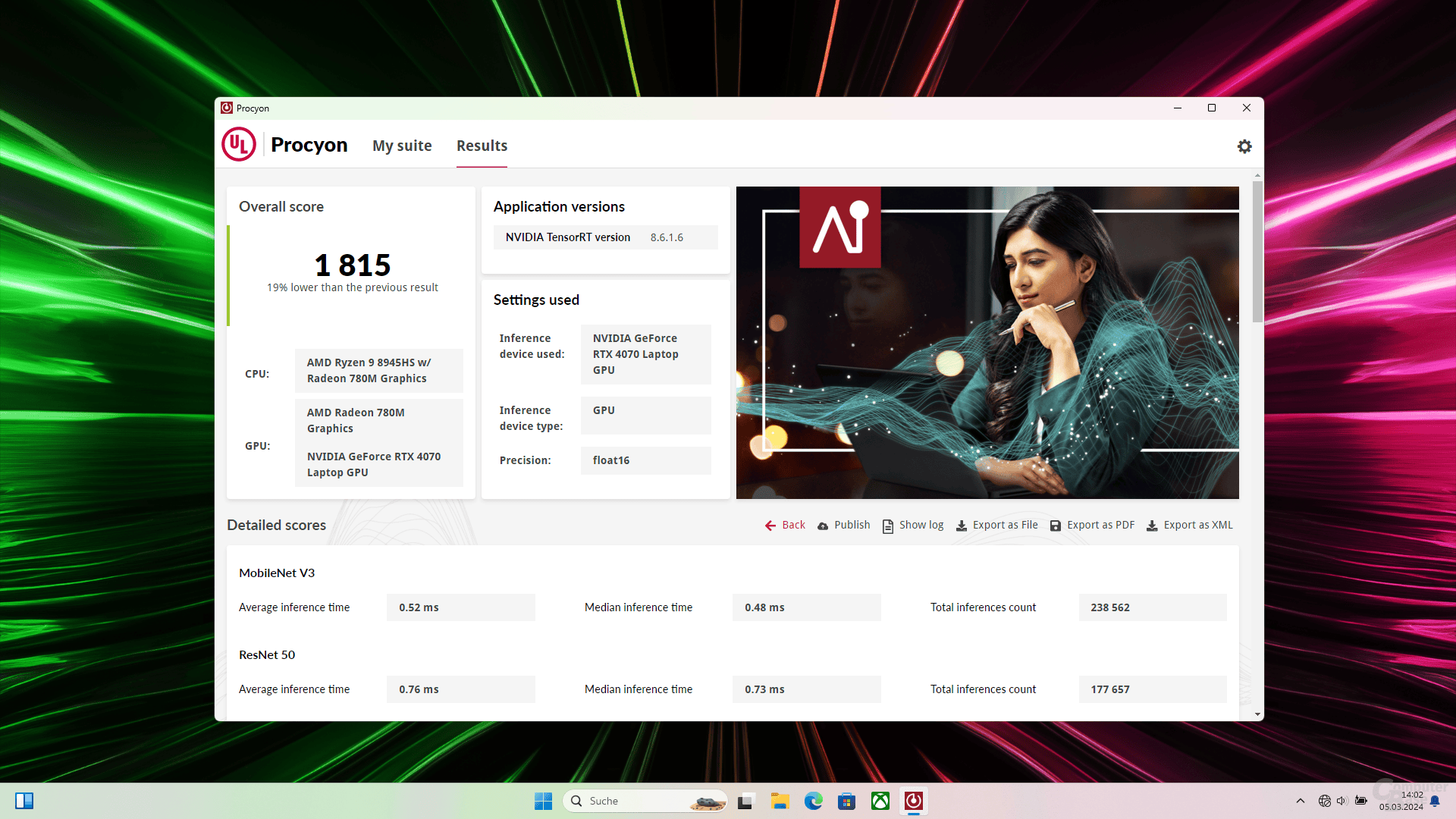
| Nvidia TensorRT | |||
| Float32 | – | – | 923 |
| Float16 | – | – | 1815 |
| Integer | – | – | 2.242 |
Der Blick auf die Testergebnisse präsentiert auch in diesem Bereich einen Flickenteppich: Mit zwei unterschiedlich ausgestatteten Notebooks Überschneidungen für etwaige Vergleiche zu bekommen, gestaltet sich schwierig. Ein jedes Produkt hat schließlich sein präferiertes Umfeld und greift dabei zum Teil auch auf spezielle Engines zurück. Bei Nvidia heißt das TensorRT und zielt auf die Tensor-Cores der GPU, bei Intel wird mit OpenVino das Komplettpaket abgedeckt und es lassen sich explizit GPU, CPU und NPU für die Berechnung auswählen. AMD hält sich hingegen komplett an den kleinsten gemeinsamen Nenner: Windows ML. Wird die CPU gewählt, findet Last unter Umständen auch auf der NPU statt, wird die GPU gewählt, wird die iGPU oder die im Notebook verwendete dGPU genutzt. Als vierte Plattform gibt es Qualcomm SNPE, die im Test aber nicht zum Einsatz kam.
AMD hatte sich kürzlich noch einmal zum Thema Ryzen AI und damit zur NPU zu Wort gemeldet. In einem Blog-Eintrag kündigte man an, dass Microsoft in Kürze die NPU auch im Taskmanager anzeigen will. Das sollte im Endeffekt auch das Monitoring über andere Tools erleichtern, denn die Daten aktuell abzugreifen, gestaltet sich mitunter noch immer schwierig. Parallel dazu verwies AMD erst Anfang März auf einen GPT based LLM-powered AI chatbot, der offline auf Radeon-Grafikkarten und auch Ryzen AI funktioniert.
Voll auf Windows (ML) zu setzen, hat für AMD gewisse Vorteile, aber auch Nachteile. Die Durchdringung im Markt und die Nutzung der NPU werden damit in Zukunft zweifelsohne gegeben sein, denn an Windows führt im Endkundengeschäft künftig zunächst nichts vorbei. Dass das Ergebnis dabei nicht das beste ist, scheint AMD zu akzeptieren, denn zunächst geht es allein um Marktdurchdringung. Mehr Leistung durch angepasste Engines und Software zu bekommen, ist nur durch entsprechende Investitionen möglich.
Intel arbeitet an OpenVino schon sehr lange, Nvidia mit den Tensor-Cores der GPU und darauf abgestimmter Software ebenfalls. Intel hat OpenVino gerade in der 2024er-Version via GitHub zum Download freigegeben.
Einzeltests und Engine-Unterschiede inklusive Stromverbrauch
Die global ermittelten Punkte allein sind in ihrer Aussagekraft begrenzt, insbesondere wenn es keine Erfahrungswerte oder Punkte zur Einordnung gibt. Der Blick in die Detail-Ergebnisse zu jedem Test hilft mitunter weiter, denn viele der Subtests in jedem einzelnen Benchmark ermitteln Ergebnisse in Millisekunden – beispielsweise wie lange es gedauert hat, bis ein Bild erstellt oder hochskaliert wurde.
In den Einzeltests zeigen sich einige Unterschiede, es lassen sich aber auch Quervergleiche ziehen. Da der kleinste gemeinsame Nenner in Form der Inference-Engine Windows ML ist, wird dieses ausgewählt – der float16-GPU-Test, um genau zu sein.
| Einzelergebnisse (float16 GPU Windows ML) |
Intel Core Ultra 5 155H | AMD Ryzen 9 8945HS + Radeon 780M (37 Watt ) |
AMD Ryzen 9 8945HS (54 Watt) + GeForce RTX 4070 (130 Watt) |
|---|---|---|---|
| MobileNet V3 | 1,61 ms | 1,63 ms | 0,42 ms |
| ResNET 50 | 3,89 ms | 5,20 ms | 0,90 ms |
| Inception V4 | 12,42 ms | 16,59 ms | 1,88 ms |
| DeepLab V3 | 26,43 ms | 30,99 ms | 10,39 ms |
| YOLO V3 | 24,10 ms | 17,22 ms | 3,60 ms |
| Real-Esrgan | 1062,50 ms | 400,08 ms | 111,62 ms |
| Endergebnis | 258 Punkte | 283 Punkte | 1318 Punkte |
| Stromverbrauch ⌀/max. | 23,9 / 48,1 Watt | 32,7 / 41,5 Watt | 19,5 + 52,7 / 48,5 + 129,6 Watt |
Bereits in den beiden letzten Tests mit einem AMD Ryzen 8000 war aufgefallen, dass sich durch die Absenkung der TDP die Leistung bei der GPU nicht oder kaum verändert. So auch beim GPU-Test hier und heute: Mit nur rund 32 Watt statt bis zu 54 Watt Package-Power kommt das gleiche Ergebnis heraus.
Die Lastspitzen zwischen dem Intel Core Ultra 7 155H und dem AMD Ryzen 9 8845HS (37 Watt) sind ebenso wie das Gesamtergebnis nun recht ähnlich. Über die reine CPU-GPU-Performance lässt sich kein echter Sieger küren. Aber die Lösungen können ja noch mehr.
Intel Meteor Lake in AI: NPU ersetzt GPU?
Heruntergebrochen auf Intel Meteor Lake allein ist die Betrachtung auch hier für die GPU-Einheit im gleichen float16-Benchmark interessant. Mit dem Wechsel von Windows ML auf OpenVino erhöht sich die Punktzahl markant, was auch klar macht, dass man mit einem Intel-Modell schlichtweg nicht auf Windows ML setzen sollte. Der globale Test hatte dies schon gezeigt: Jeder Test erreicht deutlich weniger Punkte.
Der Blick auf die Punkte zeigt Gemeinsamkeiten zwischen dem Windows-ML-Test der GPU und OpenVino im NPU-Einsatz. Der Hersteller betont, dass die NPU in gewissen Szenarien eine hohe Leistung liefern kann, dafür aber nur einen Bruchteil der Energie verbraucht. Dies hat ComputerBase bei den Testläufen geloggt und festgestellt, beim NPU-Einsatz wird dies unter „System Agent“ aufgezeichnet. Statt wie sonst lediglich 2, 3 oder auch mal 4 Watt zu benötigen, zieht er in den NPU-Tests nun bis zu 10 Watt, was überraschend viel ist. Dafür dürfen die CPU und auch die GPU allerdings mit nur ganz kleinem Verbrauch auskommen.
| Einzelergebnisse (float16) |
Intel Core Ultra 5 155H (Windows ML GPU) |
Intel Core Ultra 5 155H (OpenVino GPU) |
Intel Core Ultra 5 155H (OpenVino NPU) |
|---|---|---|---|
| MobileNet V3 | 1,61 ms | 1,09 ms | 0,94 ms |
| ResNET 50 | 3,89 ms | 3,28 ms | 3,06 ms |
| Inception V4 | 12,42 ms | 8,69 ms | 10,91 ms |
| DeepLab V3 | 26,43 ms | 14,55 ms | 45,10 ms |
| YOLO V3 | 24,10 ms | 17,92 ms | 21,42 ms |
| Real-Esrgan | 1062,50 ms | 556,88 ms | 1043,99 ms |
| Endergebnis | 258 Punkte | 388 Punkte | 281 Punkte |
| Stromverbrauch ⌀/max. | 23,9 / 48,1 Watt | 25,8 / 57,0 Watt | 14,5 / 66,7 Watt |
Beim neuen Intel Core Ultra mit separater NPU sind mehrere Dinge zu beobachten. Mit Intels OpenVino erreicht die NPU eine ähnliche bis leicht höhere Punktzahl als mit Windows ML im reinen GPU-Test. Im OpenVino-GPU-Test wiederum liegt die Leistung deutlich oberhalb von Windows ML.
Interessant ist der dazu passende Strombedarf. Denn selbst in dem NPU-Test muss gelegentlich die CPU ran, wie im ersten Test und vor allem im vorletzten sichtbar wird. Das einzige System, das wirklich nichts macht, ist die Grafikeinheit: Mit 0,003 Watt Verbrauch (oder ähnlich) schläft sie ganz tief.
Beim Gesamtergebnis schneidet der NPU-Test am besten ab. Im Durchschnitt nur noch knapp 15 Watt benötigt die komplette Intel-CPU für ein annähernd gleiches Ergebnis wie unter Windows ML mit klassischen Methoden und einem Bedarf von im Schnitt 24 Watt. Bei ähnlichem Verbrauch kann wiederum über Intels Software-Schnittstelle ein fast 50 Prozent höheres Ergebnis erzielt werden. Einmal mehr macht dies deutlich: Wer eine Intel-CPU nutzt, sollte um Windows ML einen Bogen machen, sofern die Option besteht.
AMD Ryzen 9 8945HS mit iGPU und RTX 4070
Bei AMD gibt es diese Option (wie bereits geschrieben) nicht. Windows ML ist die einzige Lösung. Im AMD-Notebook ist natürlich insbesondere der Unterschied zwischen integrierter GPU und diskreter RTX 4070 interessant – auf Grundlage des Einsatzes im gleichen Umfeld von Windows ML. Aber auch Nvidia kann mehr als den kleinsten gemeinsamen Nenner nutzen. Sowohl Windows ML im GPU-Test als auch TensorRT fordern die GPU dann mit bis zu 130 Watt heraus, liefern allerdings viel mehr Leistung.
| Einzelergebnisse (float16 GPU) |
AMD Ryzen 9 8945HS + Radeon 780M (Windows ML) |
AMD Ryzen 9 8945HS + GeForce RTX 4070 (Windows ML) |
AMD Ryzen 9 8945HS + GeForce RTX 4070 (TensorRT) |
|---|---|---|---|
| MobileNet V3 | 1,63 ms | 0,42 ms | 0,52 ms |
| ResNET 50 | 5,20 ms | 0,90 ms | 0,76 ms |
| Inception V4 | 16,59 ms | 1,88 ms | 1,89 ms |
| DeepLab V3 | 30,99 ms | 10,39 ms | 3,57 ms |
| YOLO V3 | 17,22 ms | 3,60 ms | 2,23 ms |
| Real-Esrgan | 400,08 ms | 111,62 ms | 74,20 ms |
| Endergebnis | 283 Punkte | 1318 Punkte | 1815 Punkte |
| Stromverbrauch ⌀/max. | 32,7 / 41,5 Watt | 19,5 + 52,7 / 48,5 + 129,6 Watt | 22,9 + 52,3 / 44,8 + 130,1 Watt |
Der AMD Ryzen 9 8945HS und Intels Meteor Lake nähern sich bei einem float16-GPU-Test deutlich an: AMD mit dem Windows-ML-GPU-Test und Intels Core Ultra 5 155H beim OpenVino-NPU-Test. 283 bis 290 Punkte gibt es für AMDs iGPU, 281 Punkte für Intel Core. Beide Tests wurden mitgeloggt und ergeben folgendes Bild.
Auch mit der RTX 4070 wird der gleiche Test wiederholt wie mit der iGPU von AMD – im gleichen Umfeld. Zum Vergleich aber auch die Tensor-RT-Lösung im float16-GPU-Test, die noch einmal mehr Punkte erzielen kann. Nun werden jedoch bis zu 130 Watt von der GPU bezogen, zusätzlich kommt die APU hinzu, die zu der Zeit auch noch einige Watt verlangt.
Doch die Spitzenwerte im Verbrauch sind auch hier nur ein Element, der Durchschnitt etwas anderes. Für die APU plus die RTX 4070 sind es im Durchschnitt 70 bis 75 Watt Leistungsaufnahme sowohl in Windows ML als auch beim TensorRT-Test. Erneut ist dabei die explizite Herstellerlösung die weitaus bessere imd liefert knapp 50 Prozent mehr Punkte.
Aber selbst das Ergebnis unter Windows ML zwischen reiner APU mit integrierten 780M oder dem Setup mit RTX 4070 zeigt Interessantes: Letzteres verbraucht insgesamt zwar mehr als doppelt so viel, leistet dafür aber mehr als vier Mal so viel. Letztlich ist es wie so oft eine Frage der benötigten Leistung oder vielleicht der größtmöglichen Effizienz.
Fazit
Was moderne Systeme mit AI-Fähigkeiten können, bleibt auch nach der kleinen Exkursion nur schwer greifbar. UL versucht es mit einem Benchmark im 3DMark-Stil zwar einfach darzustellen, doch der Zugang bleibt weiterhin schwierig. Ja, mehr Punkte sind besser. Aber dann?
Eines wird allerdings schnell klar: Leistung gibt es nur mit angepasstem Softwarepaket. Mit Windows ML wird der kleinste gemeinsame Nenner geboten, doch wenn man wirklich eine optimierte Version für das eigene Produkt haben möchte, muss selbst Hand angelegt werden.
Vorreiter hierbei ist Nvidia, dafür aber auch stark im Zugang eingeschränkt respektive nicht offen für fremden Input. Intel will OpenVino als freie Software breiter aufstellen, optimiert aber natürlich erstmal für eigene Zwecke. Zurück hängt AMD. Deren Ressourcen sind in Richtung Profibereich verlagert worden, dort liegt zweifelsohne auch das Geld. Wenn ROCm und Co hier saubere Arbeit liefern, könnte dies auch in anderen Bereichen fruchten.
Intels Lösung Meteor Lake zeigt als Komplettpaket heute schon grob, wie es in naher Zukunft laufen könnte. Es funktioniert alles mit dem Basispaket, doch es gibt auch optimierte Engines, die viel mehr Leistung liefern können oder deutlich effizienter arbeiten. Der Grundstein ist gelegt.
Das bereits seit einem halben Jahr von Intel ausgerufene Ziel, über 100 Millionen „AI-PCs“ bis zum kommenden Jahr auszuliefern, dürfte gar nicht so ein großes Problem sein, denn ab Meteor Lake wird jede Intel-Lösung eine NPU besitzen. Ob sie auch mit der darauf abgestimmten Software die dafür präferierten Aufgaben effizient lösen werden, steht noch auf einem anderen Papier.

UL Procyon und der AI-Inference-Benchmark für Windows sind ein erster Schritt, dies auch in heimischer Umgebung messen und beurteilen zu können. Echte Benchmarks für AI-Systeme gibt es bisher quasi nicht. Hier wird es in Zukunft mit Sicherheit aber ebenfalls passende Tests geben, die bei einer objektiven Bewertung helfen können. Dem Buzzword AI müssen definitiv noch einige Taten folgen, dann hat aber auch der Kunde am heimischen PC oder Notebook etwas davon.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.