Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Notiz 3-nm-Prozess: TSMC stößt auf mehr Probleme und Verzögerungen
- Ersteller Volker
- Erstellt am
- Zur Notiz: 3-nm-Prozess: TSMC stößt auf mehr Probleme und Verzögerungen
Shaav
Fleet Admiral
- Registriert
- Okt. 2009
- Beiträge
- 12.116
Ich glaube das muss so im Jahre 1990 gewesen sein. Damals sagte man, dass bei der Wellenlänge des Lichts (ca. 400-800nm) Ende ist. Derzeit sind wir so bei 40nm.Hylou schrieb:3nm klingt schon sehr klein
Welche ist denn die Größe bei der zu erwarten ist, dass wir an eine physikalische Grenze stoßen?
Irgendwann wirds doch nicht mehr kleiner gehen.. Oder?
Hylou schrieb:3nm klingt schon sehr klein
Welche ist denn die Größe bei der zu erwarten ist, dass wir an eine physikalische Grenze stoßen?
Irgendwann wirds doch nicht mehr kleiner gehen.. Oder?
Korrekt. So hat z.B. ein siliziumatom einen durchmesser von ungefähr 0,1 nm, 3 nm große Strukturen werden daher durch 30 nebeneinanderliegende Atome (!) gebildet. Es wird vielleicht noch etwas kleiner werden aber in ein paar Jahren ist das ende der Fahnenstange erreicht.
bondage game schrieb:Die zahlen sind ja sowieso geschönt, die richtigen grössen sind gut grösser
Auch korrekt, die meisten Strukturen auf einem Die sind größer. Nur für die Elemente wo eine Verkleinerung einen positiven Effekt hat gibt das auch Sinn, schnöde Sachen wie z.B. simple Leitungen kann man ohne Nachteile größer und damit z.B. Fehlertoleranter machen.
DarkerThanBlack
Commander
- Registriert
- Juli 2016
- Beiträge
- 2.077
danyundsahne schrieb:Tja, das ist das Problem an der Sache....um minimale Fortschritte zu machen sind enorme Anstrengungen nötig bei diesen kleinen Strukturen.
Kleine Fortschritte? Weil es sich nur noch um einstellige Nanometer-Bereiche handelt?JaKno schrieb:Riesensprünge wird es eh nicht mehr geben, so what.
Ihr wisst schon was Prozentrechnung ist oder?
Von 100nm auf 50nm sind 50% Verkleinerung.
Von 7nm auf 3nm sind weit über 50% Verkleinerung. Nur so als Beispiel...
latiose88 schrieb:Ja wir dürfen halt keine solchen Sprünge wie damals erwarten. Er erwartet das von 7 nm auf 5 nm von tsmc gleich 60 oder gar 100 % mehrleistung alleine nur durch den shrink möglich wäre, der lebt halt in einer Traumwelt. Denn es kann niemals eine unendliches Wachstum geben. Das wäre ja unnormal.
Von 14nm(VEGA64) auf 7nm(RX6900XTX) sind es gar fast 300% Leistungszuwachs.
OK, es ist auch eine neue Architektur dazwischen, was wir aber auch bei dem 5nm Schritt durch RDNA3 sehen werden.
Aber ja, man sollte nie soviel erwarten, aber es ist meist doch mehr als man vermutet. 😉
Aber noch etwas zum Thema.
TSMC sollte erst einmal ihren 7nm+ und ihren 5nm Fertigungsschritt ausbauen. Bis wirklich 3nm verfügbar sein wird dauert es sicherlich noch 2-3 Jahre.
Und ja, auch SAMSUNG darf man nicht unterschätzen. Sie mögen zwar augenscheinlich mit ihrer 8nm-Fertigung noch etwas hinter TSMC liegen, aber dies kann sich sehr schnell mit der neuen 3nm-Fertigung ändern, weil TSMC dabei immer noch auf das alte Verfahren setzt und unter Umständen ins Hintertreffen gerät.
Zuletzt bearbeitet:
Shaav schrieb:Ich glaube das muss so im Jahre 1990 gewesen sein. Damals sagte man, dass bei der Wellenlänge des Lichts (ca. 400-800nm) Ende ist. Derzeit sind wir so bei 40nm.
Nochmals korrekt. Damals konnte man sich absolut nicht vorstellen das man mit großen Wellenlängen Strukturen schaffen kann die kleiner und heute sogar viel kleiner als die genutzte Wellenlänge sind, da stehen fundamentale physikalische Gesetze dahinter.
Trotzdem hat man es mit vielen Tricks und auch etwas Magie geschafft das im großtechnischen Maßstab zu etablieren, kommt aber bei den aktuell üblichen Strukturgrößen endgültig an die mit optischen Verfahren erreichbare Grenze. Die Wafer der nächsten Chipgenerationen werden mittels Röntgenstrahlung belichtet werden, dann muss man aber Magnetfelder anstelle von Linsen nutzen - nicht wirklich einfach.
So schnell kann es gehen und die Konkurrenz hat die Möglichkeit, wieder aufzuholen.
Irgendwann werden wir auch auf Grenzen bei der Wirtschaftlichkeit stoßen, aber noch gibt's ein paar Entwicklungen in Arbeit, die den Fortschritt vorantreiben. Gate-all-around steht ja auch noch aus und EUV selbst ist ja auch noch relativ frisch.
7nm und 5nm liefen bei TSMC ja gut durch, dass es jetzt bei 3nm Probleme gibt, hat also erstmal nichts zu bedeuten. Intel hat sich mit ihren 10nm ja auch ordentlich verhoben und 7nm verschiebt sich bisher auch weiter nach hinten. Wie es bei Samsung aussieht, weiß ich nicht, irgendwie bekomme ich da nicht soviel mit.
Aber wenn der klassische Weg bald zu Ende geht, gibt's trotzdem noch potential durch neue Technologien. Die Wissenschaft schläft ja nicht und auch, wenn Quantencomputer wohl nicht für alles gut sind, gibt's vielleicht auch Wege für die Berechnung mit klassischen Bits. Quanteneffekte könnten eventuell den (nahezu) Perfekten Schalter hervorbringen, wodurch weniger Leistungsaufnahme notwendig wird und eventuell eine Taktexplosion hervorbringt. Es gibt auch immer wieder Fortschritte bei der Hochtemperatur-Supraleitung als Beispiel, auch wenn man immer noch weit von der praktischen Nutzung entfernt ist. Aktuell ist man schon bei +15°C angelangt.
Wahrscheinlich wird aber der Aufwand für Hardware irgendwann zu groß, um die Rechnenleistung Daheim zu haben. Es wird dann mehr in die Cloud wandern und zu Hause und Unterwegs sind nur noch Client-Systeme, in einigen Fällen wird ja schon Ausgelagert, die modernen Sprachassistenten als Beispiel funktionieren Lokal nicht. Sprachsteuerung ohne Cloud sind eher Rudimentär auf eine beschränkte Anzahl von Befehlen.
Zur Prozessgröße:
Klar sind die Angaben zur Größe nur Marketingnamen und die tatsächlichen Größen sind völlig andere. Das liegt aber auch daran, das früher die Angabe auf die Gatelänge (soweit ich weiß) bezog aber durch weitere Fortschritte war das dann nicht mehr die ausschlaggebende Größe. Es wurden dann Shrinks möglich, ohne die Gatelänge zu verändern. Inzwischen sind daher mehrere Größen relevant, was viel zu sperrig für eine Prozessbezeichnung wäre. Man hat sich dann dazu entschlossen, eine Quasi-Entsprechung der Gategröße als Namen zu verwenden, gerade weil zuvor die Prozesse nach der Gategröße benannt wurden. Ein Schwenk auf willkürliche Namen war eher wenig sinnvoll.
Auch die tatsächlichen Größen sind nur schwer miteinander vergleichbar, die 4-5 Längenangaben aus Vergleichstabellen geben noch längst nicht alle Parameter wieder, die die Prozesse mit sich bringen, sonst wäre es ja auch nicht so ein Problem, funktionierende Prozesse zu entwickeln.
Packdichten also Transistordichten hängen dagegen auch mit dem Chipdesign zusammen und die tatsächliche Leistung hängt auch stark von der Architektur und den Anwendungszweck ab.
Letztendlich kann man nur die fertigen Produkte vergleichen, die auch ähnliche Anwendungsfälle haben. Also beispielsweise Intel-CPUs gegen AMD-CPUs oder Nvidia-GPUs gegen AMD-GPUs, der Vergleich dort zwischen den Fertigungen von Intel, Samsung und TSMC ist damit kaum möglich
Irgendwann werden wir auch auf Grenzen bei der Wirtschaftlichkeit stoßen, aber noch gibt's ein paar Entwicklungen in Arbeit, die den Fortschritt vorantreiben. Gate-all-around steht ja auch noch aus und EUV selbst ist ja auch noch relativ frisch.
7nm und 5nm liefen bei TSMC ja gut durch, dass es jetzt bei 3nm Probleme gibt, hat also erstmal nichts zu bedeuten. Intel hat sich mit ihren 10nm ja auch ordentlich verhoben und 7nm verschiebt sich bisher auch weiter nach hinten. Wie es bei Samsung aussieht, weiß ich nicht, irgendwie bekomme ich da nicht soviel mit.
Aber wenn der klassische Weg bald zu Ende geht, gibt's trotzdem noch potential durch neue Technologien. Die Wissenschaft schläft ja nicht und auch, wenn Quantencomputer wohl nicht für alles gut sind, gibt's vielleicht auch Wege für die Berechnung mit klassischen Bits. Quanteneffekte könnten eventuell den (nahezu) Perfekten Schalter hervorbringen, wodurch weniger Leistungsaufnahme notwendig wird und eventuell eine Taktexplosion hervorbringt. Es gibt auch immer wieder Fortschritte bei der Hochtemperatur-Supraleitung als Beispiel, auch wenn man immer noch weit von der praktischen Nutzung entfernt ist. Aktuell ist man schon bei +15°C angelangt.
Wahrscheinlich wird aber der Aufwand für Hardware irgendwann zu groß, um die Rechnenleistung Daheim zu haben. Es wird dann mehr in die Cloud wandern und zu Hause und Unterwegs sind nur noch Client-Systeme, in einigen Fällen wird ja schon Ausgelagert, die modernen Sprachassistenten als Beispiel funktionieren Lokal nicht. Sprachsteuerung ohne Cloud sind eher Rudimentär auf eine beschränkte Anzahl von Befehlen.
Zur Prozessgröße:
Klar sind die Angaben zur Größe nur Marketingnamen und die tatsächlichen Größen sind völlig andere. Das liegt aber auch daran, das früher die Angabe auf die Gatelänge (soweit ich weiß) bezog aber durch weitere Fortschritte war das dann nicht mehr die ausschlaggebende Größe. Es wurden dann Shrinks möglich, ohne die Gatelänge zu verändern. Inzwischen sind daher mehrere Größen relevant, was viel zu sperrig für eine Prozessbezeichnung wäre. Man hat sich dann dazu entschlossen, eine Quasi-Entsprechung der Gategröße als Namen zu verwenden, gerade weil zuvor die Prozesse nach der Gategröße benannt wurden. Ein Schwenk auf willkürliche Namen war eher wenig sinnvoll.
Auch die tatsächlichen Größen sind nur schwer miteinander vergleichbar, die 4-5 Längenangaben aus Vergleichstabellen geben noch längst nicht alle Parameter wieder, die die Prozesse mit sich bringen, sonst wäre es ja auch nicht so ein Problem, funktionierende Prozesse zu entwickeln.
Packdichten also Transistordichten hängen dagegen auch mit dem Chipdesign zusammen und die tatsächliche Leistung hängt auch stark von der Architektur und den Anwendungszweck ab.
Letztendlich kann man nur die fertigen Produkte vergleichen, die auch ähnliche Anwendungsfälle haben. Also beispielsweise Intel-CPUs gegen AMD-CPUs oder Nvidia-GPUs gegen AMD-GPUs, der Vergleich dort zwischen den Fertigungen von Intel, Samsung und TSMC ist damit kaum möglich
300% na übertreibe mal nicht.DarkerThanBlack schrieb:Kleine Fortschritte? Weil es sich nur noch um einstellige Nanometer-Bereiche handelt?
Ihr wisst schon was Prozentrechnung ist oder?
Von 100nm auf 50nm sind 50% Verkleinerung.
Von 7nm auf 3nm sind weit über 50% Verkleinerung. Nur so als Beispiel...
Von 12nm(VEGA64) auf 7nm(RX6900XTX) sind es gar fast 300% Leistungszuwachs.
OK, es ist auch eine neue Architektur dazwischen, was wir aber auch bei dem 5nm Schritt durch RDNA3 sehen werden.
Aber ja, man sollte nie soviel erwarten, aber es ist meist doch mehr als man vermutet. 😉
Anhang anzeigen 1018604
Also es sind nur 150 % unterschiede. Zudem sind da ja auch noch Optimierungen von amd mit dabei. Ich rede von der reinen leistungsunterschied nur durch das verkleinern an sich ohne das da groß was noch optimiert wurde. Da sieht es dann schon wieder anderst aus. Also da kann man dann wirklich nicht mehr so viel erwarten. Ich spreche also von einfach nur die gpu auf die kleinere bringen. Dann sowas noch mit oc oder dergleichen und nicht mehr Transistoren. So meinte ich das halt. Aber gut. So einen direkt verlgleich mit selben Einheiten und so wird es auch niemals geben echt schade.
Solche Erwartungen sind nicht unrealistisch:latiose88 schrieb:Er erwartet das von 7 nm auf 5 nm von tsmc gleich 60 oder gar 100 % mehrleistung alleine nur durch den shrink möglich wäre, der lebt halt in einer Traumwelt.
| Prozess | Transistoren pro mm² | Steigerung |
| TSMC 7nm | 100 | |
| TSMC 5nm | 170 | 70% |
| TSMC 3nm | 290 | 70% |
DarkerThanBlack
Commander
- Registriert
- Juli 2016
- Beiträge
- 2.077
Wobei es durchaus noch besser sein kann. 😊
https://www.computerbase.de/news/wirtschaft/fertigung-5-nm-tsmc.71392/
https://www.computerbase.de/news/wirtschaft/fertigung-5-nm-tsmc.71392/
- Registriert
- Jan. 2018
- Beiträge
- 19.604
Das hat der8auer schon mal machen lassen.ofenheiz schrieb:Die einzige Möglichkeit an sinnvolle Werte ranzukommen, ist den DIE abschleifen und nachmessen.
Keine Ahnung, ob und wenn ja wieviel das gekostet hat.
Ergänzung ()
Da sind dann Performance pro Watt auch extrem wichtig. Bringt mir ja nix, wenn die neue GPU 20% schneller ist, aber 30% Energie verbrät.DarkerThanBlack schrieb:Von 14nm(VEGA64) auf 7nm(RX6900XTX) sind es gar fast 300% Leistungszuwachs
Ja, ich weiß das RDNA effizienter ist.
Ergänzung ()
Nur, das intel den eigenen Zeitplan mal wieder nach hinten schieben mussteOzmog schrieb:So schnell kann es gehen und die Konkurrenz hat die Möglichkeit, wieder aufzuholen
Zuletzt bearbeitet:
Maggolos
Lieutenant
- Registriert
- Mai 2012
- Beiträge
- 651
DarkerThanBlack schrieb:Kleine Fortschritte? Weil es sich nur noch um einstellige Nanometer-Bereiche handelt?
Ihr wisst schon was Prozentrechnung ist oder?
Von 100nm auf 50nm sind 50% Verkleinerung.
Von 7nm auf 3nm sind weit über 50% Verkleinerung. Nur so als Beispiel..
Du überschätzt die Fertigung und unterschätzt die neuen Architekturen und Software.
Siehe die Tabelle.
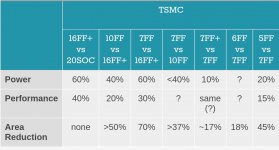
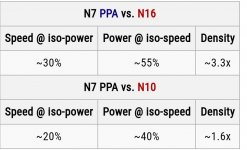
When compared to N7 (1st Generation 7 nm) that solely relies on deep ultraviolet lithography, TSMC lists its N7+ process as providing a 15% to 20% higher transistor density as well as 10% lower power consumption at the same complexity and frequency.
According to TSMC slides, N7+ vs. N7 can also provide +10% performance at iso-power.
Iso-power - A comparison that is done at a fixed power level (e.g., 1W/core)
Zudem sind 7nm nicht 7nm sondern ist mittlerweile noch mehr Marketing (hat ursprünglich Mal die kleinste Struktur gemeint)
Und die Dichte vom Prozess ist meistens unter NDA.
Anhänge
- Registriert
- Mai 2008
- Beiträge
- 5.583
Oder bei Intel tauchen noch mehr Probleme auf. Dann werden TSMC und Samsung ihren Vorsprung halten oder ausbauen. Dann wird es für Intel noch enger.DavidG schrieb:Da wird Intel dann die Zeit bekommen, den Rückstand wieder aufzuholen. Dann wird es für AMD wieder ganz eng.
Topflappen
Lt. Commander Pro
- Registriert
- März 2011
- Beiträge
- 1.790
Ich bin eh noch auf 22nm unterwegs, alles halb so wild.
Ja, will ich auch!Shaav schrieb:Vor Jahren gab es mal einen Vergleich in Form einer Tabelle der verschiedenen Fertigungsverfahren von TSMC, SAMSUNG, INTEL und GlobalFounddries. Ich meine auf heise.de habe ich den gesehen. In diesem Vergleich stand, was sich hinter dieser Marketingbezeichnung eigentlich verbirgt, nämlich die tatsächliche Strukturbreite der einzelnen Komponenten des Transistors. ("Gate", "Pitch" oder so)
Ich fände es super, wenn es von ComputerBase einen aktuellen Artikel zu dem Thema gäbe. Hoffentlich ist das nicht zu speziell 😅
Also CB, haut die Heatspreader runter, schmirgelt das Silizium auf und messt mit eurem Elektronenmikroskop die Strukturbreiten. Wir haben bald 2021, da kann man sowas schon von euch verlangen!
Erinnere ich mich auch dran, nur kann ich sie nicht mehr finden.Shaav schrieb:Vor Jahren gab es mal einen Vergleich in Form einer Tabelle der verschiedenen Fertigungsverfahren
Hier mal ein Vergleich zwischen TSMC 7nm und Intels aktuellen 14nm:
Die Strukturen sind ähnlich groß, nur hat es TSMC geschafft die Transistoren enger bei einander zu platzieren.
Intels 10 nm soll dann wohl vergleichbar mit TSMCs 7 nm sein. Intel wird AMD mit Sunny Cove also nächstes Jahr eventuell in etwa das Wasser reichen können. Eine Führung ist aber zumindest vor dem 7nm Prozess 2023 unwahrscheinlich.
https://hexus.net/tech/news/cpu/145645-intel-14nm-amdtsmc-7nm-transistors-micro-compared/
Gipsy Danger
Ensign Pro
- Registriert
- Okt. 2007
- Beiträge
- 246
Ich eier noch auf 22nm rum also , nicht der rede wert 
T
Teralios
Gast
Kommt etwas darauf an. Entsprechende Elektronen-Mikroskope gehen im 5 stelligen Bereich los und bei den echt geilen von Zeiss stehen gerne auch mal 8 Ziffer vor dem Komma auf dem Zettel. Das ist hier aber nicht von Relevanz.ofenheiz schrieb:Das geht aber nur mit Equipment für Hunderttausende bis Millionen von Euro, was das Budget von Computerbase deutlich übersteigt.
Keine Redaktion, nicht mal viele Firmen, sind dazu gezwungen, wenn sie entsprechende Aufnahmen machen möchten, sich dieses Equipment zu kaufen. Die TU-Berlin ist für die CB ein Steinwurf entfernt und bei denen kann mehr sehr wohl auch Zeit mit entsprechenden Geräten mieten, was nur noch ein Bruchteil dessen kostet, was diese Geräte kosten. Und entsprechende Zeitslots gibt es öfter als man denkt. Klar, wir sprechen dann immer noch gerne mal von 4 stelligen Summen, da ja auch das Personal gebucht wird.
Die sind noch nicht so weit, sondern haben, wie fast alle, nur ihre Pläne vorgestellt und was sie machten möchten. Bis Samsung, Intel und TSMC wirklich GAA einsetzten, wird noch etwas die Spree und Havel lang fließen.Doenerbong schrieb:GAA ist auch echt eine beeindruckende Technik. Wahrscheinlich die größte Neuerung seit der Einführung des FinFETs. Ich wundere mich sowieso, wie Samsung schon so weit sein kann. Das wird bei Intel erst in 3nm implementiert werden (also an einem unbekannten Datum).
Ja, es gibt eine untere Grenze, in den meisten Fällen - bei Silizium - 3 Atome: PNP oder NPN. Liegt bei Silizium, je nach Zahl die du nimmst, bei 110 - 210pm und damit bei 330 - 630pm, die man mindestens braucht.Hylou schrieb:Welche ist denn die Größe bei der zu erwarten ist, dass wir an eine physikalische Grenze stoßen?
Irgendwann wirds doch nicht mehr kleiner gehen.. Oder?
latiose88 schrieb:Danach wird es mit pitometer weiter gehen.
Nicht wirklich, da es eine harte physikalische Grenze gibt, die man nicht aushebeln kann. Deswegen wird ja auch an entsprechenden Alternativen geforscht. Wirklich kleiner als 3 Silizium-Atome geht nicht und mit 3 Silizium-Atomen bewegen wir uns schon bei 0,5 nm in der Länge und 0,1 bis 0,2 nm in der Breite.
Erst von fundamentalen physikalischen Gesetzten schreiben und dann ist es plötzlich Magie … Klar, mit Tricks und Magie lassen sich fundamentale physikalische Gesetzte brechen. … Also echt, von sowas bekomme ich Kopfschmerzen.BudeII schrieb:Trotzdem hat man es mit vielen Tricks und auch etwas Magie geschafft das im großtechnischen Maßstab zu etablieren, kommt aber bei den aktuell üblichen Strukturgrößen endgültig an die mit optischen Verfahren erreichbare Grenze. Die Wafer der nächsten Chipgenerationen werden mittels Röntgenstrahlung belichtet werden, dann muss man aber Magnetfelder anstelle von Linsen nutzen - nicht wirklich einfach.
Diese »fundamentalen physikalischen« Gesetzte haben weiterhin ihre Wirkung und werden auch nicht mit etwas Magie umgangen, sondern man bewegt sich genau in diesem Rahmen der Gesetze und die Tricks, die hier verwendet werden, sind prinzipiell auch nicht gerade so weltbewegend: Statt alles mit einem Belichtungsschritt zu machen, wird es in Teilschritte aufgebrochen.
Und beim Rest: Na da wird aber ein wenig Röntgen-Lithografie sowie Elektronen/Ionen-Lithografie vermischt.
Für die, die es Interessiert: https://de.wikipedia.org/wiki/Röntgenlithografie
https://de.wikipedia.org/wiki/Elektronenstrahllithografie
Gibt ja noch Samsung, und Intel wird nicht völlig abgehängt.andi_sco schrieb:Nur, das intel den eigenen Zeitplan mal wieder nach hinten schieben musste
Forum-Fraggle
Commodore
- Registriert
- Okt. 2006
- Beiträge
- 4.281
Das hat aber andere Gründe. Insbesondere die Sprachsteuerung ginge lokal.Ozmog schrieb:Unterwegs sind nur noch Client-Systeme, in einigen Fällen wird ja schon Ausgelagert, die modernen Sprachassistenten als Beispiel funktionieren Lokal nicht. Sprachsteuerung ohne Cloud sind eher Rudimentär auf eine beschränkte Anzahl von Befehlen
Ähnliche Themen
- Antworten
- 15
- Aufrufe
- 3.530
A


