xexex schrieb:
-Komplettzitat entfernt-
Wie es richtig geht, ist
hier nachzulesen.
AMD hat die RX 6800 XT taktmäßig bei weitem nicht ausgereizt, zugunsten des Energieverbrauchs... und ja, sie verbraucht deutlich weniger bei serienbetrieb... Sie ist nichtmal beim Energieverbrauch ausgereizt: Du kannst die RX 6800 XT bei Serientaktung erheblich undervolten!!!!
Du hast also die Wahl, du bist bei AMD mega flexibel.
Wenn du auf Raytracing verzichten kannst, dann ist AMD der klare Winner bei Preis, Leistung, Effizienz!
Es gibt sogar so viel OC Potential: mit OC schlägt eine RX 6800 XT eine 3090 Ti in Rasterizing.
Das ist der helle Wahnsinn.
Die NV Karten bekommst du grade mal ein paar Mickerprozente OC, da sie einfach schon am absoluten Limit ausgeliefert werden. Diese Monsterkühler sind auch ein ZEichen dafür:
NV hat vielleicht Geld bei den CHips gespart, mussste das aber wieder in die komplexere Strpomversorgung und in die Monsterkühler reinverschwenden, da ist in Bilanz nicht viel/nichts gewonnen. Dazu noch der teuere RAM und der insgesamt teuere breitere Memorybusaufbau.
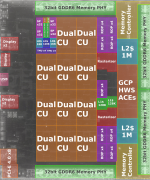
Dann verlgeich mal die Die Size (AMD) 520 mm² vs (NV) 628 mm².
Tjaaaaaaa.... das sieht nicht gut aus. Mehr diesize heißt auch es passen weniger chips auf einen Wafer, sprich die Produktion ist teuerer pro CHip und es kommt hinzu, dass die Wahrscheinlichkeit für Fehler mit jedem mm2 zum quadrat ansteigt.
Nicht nur wegen der diesize, auch durch den Betrieb am Limit gehe ich davon aus, dass auch einiges an der MArge verloren durch die schlechtere CHipausbeute. NV wird sich, denke ich künftig von der LUxusmarge verabschieden müssen, die sie gewohnt sind. Genauso bei INtel.
Ich denke, es war von NV niemals geplant, die 3080 so nah am LImit zu betreiben und dadurch all die zusätzlichen o.g. Kostenfaktoren zu haben.
AMD hat NV dazu gezwungen... nachdem die NV-Chips schon fertig waren.
Mehr geht einfach nicht mit diesen CHips. derzeit.
Ich denke unterm Strich ist die Marge bei AMD Karten besser, obwohl sie billiger sind.
Allerdings, wie gesagt, ich finde es dennoch super gut, dass dank NV gerade mit Samsung ein zweites hoffentlich tragfähiges Bein im HighendGPU-Chipmarkt herangezüchtet wird. ABer auch hier: wenn Samsung besser wird, werden sie auch selbstbewusster und werden safe die Preis anheben, sobald sie erstmal den Fuß in der Türe haben. Ich denke mal, genauso wie die CHips, sind die Preise aus Sicht von Samsung derzeit auch am absoluten Limit kalkuliert... die diesize ist da ein klarer Hinweis drauf... größerer Chip und billigere Fertigung, das lohnt sich nicht auf Dauer so wirklich für Samsung. Die Preise werden nicht so bleiben können: Samsung
wollte einfach diese Fertigung machen, um fast jeden Preis. Markteintritt ist niemals kostenlos. Aber wenn man mal drin ist, dann werden die Preis angehoben.