Anbei meine Ergebnisse von einem Dell 7506 mit i7-1165G7 im Modus Ultra-Leistung. Ich habe einmal mit Turbo gemessen und einmal ohne. Bei der Messung ohne Turbo läuft die CPU im Basistakt stabil mit 2,8 Ghz. Das ist viel effizienter wie man sehen kann, der aggressive Turbo drückt die Effizienz doch ziemlich nach unten. Die letzten paar hundert Mhz werden teuer erkauft.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Leserartikel Performance Efficiency Suite (PES)
- Ersteller TheCrazyIvan
- Erstellt am
- Registriert
- Dez. 2019
- Beiträge
- 130
UPDATE
- Version 0.7.2 Pre-Release:
- keine funktionalen Änderungen
- Intel Jasper Lake Support
- Intel Rocket Lake Support - Tester gesucht!
- Download und Changes hier: PES GitHub Repo: Release v0.7.2-Pre-Release
- Rankings aktualisiert, siehe Post #2 @ 3DC
- Interessante Newcomer: Die Jasper Lakes von Tralalak @ 3DC und y33H@ @ 3DC (AKA Marc Sauter @ golem.de). Sie verfügen über Tremont-Kerne - bekannt aus Intels erstem BIG.little Prozessor Lakefield und direkte Vorgänger von Alder Lakes Gracemont-Kernen.
Freiheraus
Lt. Commander
- Registriert
- Nov. 2017
- Beiträge
- 1.282
Intel Core i5-11500
ASRock B560M-ITX/ac
2 x 8GB Crucial Ballistix Sport LT DDR4-3000 @ 2933 G1
Samsung SSD 960 EVO 500GB
Alle Stromsparmechanismen aktiv (CPU C7 State, Package C State, PCIE ASPM, PCH PCIE ASPM, DMI ASPM, PCH DMI ASPM) & Energiesparplan: Ausbalanciert
Core i5-11500 @ Stock
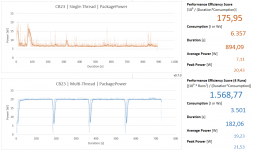
HInweis: Das Board kann aufgrund der mäßigen VRM das PL2 (154 Watt) nicht voll ausfahren und landet daher bei max. 114W, danach fällt die Package Power recht schnell auf 65 Watt (PL1). Eigentlich sehr gute Bedingungen aus Sweetspot/Effizienz-Sicht. Normalerweise wäre die CPU ineffizienter wenn PL2 bis 154 Watt gehen würde.

ASRock B560M-ITX/ac
2 x 8GB Crucial Ballistix Sport LT DDR4-3000 @ 2933 G1
Samsung SSD 960 EVO 500GB
Alle Stromsparmechanismen aktiv (CPU C7 State, Package C State, PCIE ASPM, PCH PCIE ASPM, DMI ASPM, PCH DMI ASPM) & Energiesparplan: Ausbalanciert
Core i5-11500 @ Stock
HInweis: Das Board kann aufgrund der mäßigen VRM das PL2 (154 Watt) nicht voll ausfahren und landet daher bei max. 114W, danach fällt die Package Power recht schnell auf 65 Watt (PL1). Eigentlich sehr gute Bedingungen aus Sweetspot/Effizienz-Sicht. Normalerweise wäre die CPU ineffizienter wenn PL2 bis 154 Watt gehen würde.
Anhänge
- Registriert
- Dez. 2019
- Beiträge
- 130
@Freiheraus
Danke für das Ergebnis und auch den ausführlichen Kontext. Habe Dir das Ganze mal noch in der Excel-Variante aufbereitet.
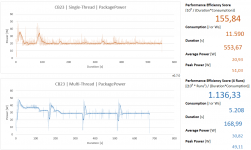
Rocket Lake ist im ST-Lauf aufgrund der monolithischen Bauweise immer noch ziemlich gut dabei - trotz 14nm++++. Ich würde auch fast behaupten, dass da noch mehr geht - der Kurvenverlauf sieht alles andere als sauber aus. Zen3 ist da auf jeden Fall in Reichweite.
Im MT sieht es dann erwartungsgemäß eher braun aus. Hier wird er vom R5 5600X mit ebenfalls 65w und 6 Kernen doch ziemlich deutlich distanziert.
Schön, endlich mal einen Rocket Lake im Vergleich zu haben")
Danke für das Ergebnis und auch den ausführlichen Kontext. Habe Dir das Ganze mal noch in der Excel-Variante aufbereitet.
Rocket Lake ist im ST-Lauf aufgrund der monolithischen Bauweise immer noch ziemlich gut dabei - trotz 14nm++++. Ich würde auch fast behaupten, dass da noch mehr geht - der Kurvenverlauf sieht alles andere als sauber aus. Zen3 ist da auf jeden Fall in Reichweite.
Im MT sieht es dann erwartungsgemäß eher braun aus. Hier wird er vom R5 5600X mit ebenfalls 65w und 6 Kernen doch ziemlich deutlich distanziert.
Schön, endlich mal einen Rocket Lake im Vergleich zu haben
Anhänge
Freiheraus
Lt. Commander
- Registriert
- Nov. 2017
- Beiträge
- 1.282
@TheCrazyIvan
Ich werde den Rocket Lake nochmal durchlaufen lassen und das Inet kappen, in der Hoffnung dass der Single-Core Verlauf mit weniger Schwankungen von statten geht. Wenn ich Zeit finde, schnalle ich auch noch einen Noctua-120mm-Towerkühler drauf, momentan ist bloß ein Box-Kühler montiert. Dann sollte der ST besser werden, MT aber eher schlechter, da der ineffiziente Turbo aufgrund der niedrigeren Temps wahrscheinlich länger gehalten wird.
Edit: Weißt du warum bei 0.72 die Diagramme mit Libre Calc so zusammengestaucht sind? Mit 0.70 sahen die noch normal aus.
-------------------------------------
Hier auch mal meine Ryzen 7 5800X Werte analog zum Ryzen 5 5600X in drei TDP-Stufen, @ Stock ist als Log-Datei angehängt.
AMD Ryzen 7 5800X
GIGABYTE B550I AORUS Pro AX
2 x 32GB Micron DDR4-3200 ECC CL22 1.2V
Samsung SSD 980 PRO 1TB
Alle Stromsparmechanismen aktiv (ASPM@L1, C6, Global C-State) & Energiesparplan: Ausbalanciert
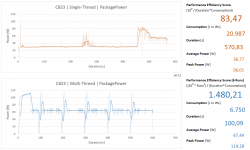
5800X @ Stock 105W TDP (PPT=142 Watt -> wird jedoch nicht erreicht unter CB23)

5800X @ ECO 65W TDP (PPT=87 Watt)

5800X @ 45W TDP (PPT=61 Watt)

Ich werde den Rocket Lake nochmal durchlaufen lassen und das Inet kappen, in der Hoffnung dass der Single-Core Verlauf mit weniger Schwankungen von statten geht. Wenn ich Zeit finde, schnalle ich auch noch einen Noctua-120mm-Towerkühler drauf, momentan ist bloß ein Box-Kühler montiert. Dann sollte der ST besser werden, MT aber eher schlechter, da der ineffiziente Turbo aufgrund der niedrigeren Temps wahrscheinlich länger gehalten wird.
Edit: Weißt du warum bei 0.72 die Diagramme mit Libre Calc so zusammengestaucht sind? Mit 0.70 sahen die noch normal aus.
-------------------------------------
Hier auch mal meine Ryzen 7 5800X Werte analog zum Ryzen 5 5600X in drei TDP-Stufen, @ Stock ist als Log-Datei angehängt.
AMD Ryzen 7 5800X
GIGABYTE B550I AORUS Pro AX
2 x 32GB Micron DDR4-3200 ECC CL22 1.2V
Samsung SSD 980 PRO 1TB
Alle Stromsparmechanismen aktiv (ASPM@L1, C6, Global C-State) & Energiesparplan: Ausbalanciert
5800X @ Stock 105W TDP (PPT=142 Watt -> wird jedoch nicht erreicht unter CB23)
5800X @ ECO 65W TDP (PPT=87 Watt)
5800X @ 45W TDP (PPT=61 Watt)
Anhänge
Zuletzt bearbeitet:
EDIT: Hat sich erledigt, changelog gelesen 
@TheCrazyIvan
Bei mir läuft der ST CB ganz normal durch, es wird auch eine csv mit den Logs erstellt. Beim MT funktioniert dann aber irgendwas nicht. Der Benchmark wird wie in einer Schleife immer wieder ausgeführt bis ich das Script beende, es wird auch keine log Datei erstellt. Helfe gerne weiter, wenn du weitere Angaben etc. benötigst.
System:
i5-11400f
Asrock B560m-Steel Legend
32GB Ballistix 3000@3600 G1
Windows 10 21H1
Hier das Ergebnis:
i5-11400f undervolted -80mv offset
Asrock B560m-Steel Legend
32GB Ballistix 3000@3600C15 G1
Powerlimits alle offen bzw auf dem Maximum des Boards(170w)
Könnte wohl den Verbrauch noch minimal verringern, indem ich das Undervolting erhöhe und VCCSA/IO verringere, teste ich später evtl. nochmal.

Update:
Habe noch etwas optimiert. Offset -95mv,Vccsa/IO Mem 1,200v. Läuft stabil zumindest nach kurzem Test mit TM5, Linpack. Logs im Anhang aktualisiert.

@TheCrazyIvan
Bei mir läuft der ST CB ganz normal durch, es wird auch eine csv mit den Logs erstellt. Beim MT funktioniert dann aber irgendwas nicht. Der Benchmark wird wie in einer Schleife immer wieder ausgeführt bis ich das Script beende, es wird auch keine log Datei erstellt. Helfe gerne weiter, wenn du weitere Angaben etc. benötigst.
System:
i5-11400f
Asrock B560m-Steel Legend
32GB Ballistix 3000@3600 G1
Windows 10 21H1
Ergänzung ()
Hier das Ergebnis:
i5-11400f undervolted -80mv offset
Asrock B560m-Steel Legend
32GB Ballistix 3000@3600C15 G1
Powerlimits alle offen bzw auf dem Maximum des Boards(170w)
Könnte wohl den Verbrauch noch minimal verringern, indem ich das Undervolting erhöhe und VCCSA/IO verringere, teste ich später evtl. nochmal.
Update:
Habe noch etwas optimiert. Offset -95mv,Vccsa/IO Mem 1,200v. Läuft stabil zumindest nach kurzem Test mit TM5, Linpack. Logs im Anhang aktualisiert.
Anhänge
Zuletzt bearbeitet:
- Registriert
- Dez. 2019
- Beiträge
- 130
UPDATE
Apropos AlderLake. Angesichts der massiven Veränderungen der kleinenGoldmont Gracemont-Kerne gegenüber Tremont in JasperLake sollte man in die Zahlen zu letzterem wirklich nicht allzu viel hineininterpretieren.
- Aktuelles Release, Download und Changes: PES GitHub Repo: Releases
- Rankings aktualisiert, siehe Post #2 @ 3DC
- Interessante Newcomer:
Mittlerweile drei Rocket Lake Samples
Apropos AlderLake. Angesichts der massiven Veränderungen der kleinen
Zuletzt bearbeitet:
- Registriert
- Dez. 2019
- Beiträge
- 130
Nee Du, dazu bin ich noch nicht gekommen. Ich gebe Dir auf jeden Fall Bescheid, sobald ich soweit bin.JeanLegi schrieb:Moin,
sollte dann auch der Fehler vom letzten mal behoben sein, welchen ich mit dem 5900HX hatte? Wenn ja würde ich es gleich mal testen
- Registriert
- Jan. 2018
- Beiträge
- 19.390
Ich werde mal versuchen, den Test auf einem Pentium E2140 mit 1,6 GHz (2,66 GHz OC) zu machen.TheCrazyIvan schrieb:Ich würde mich extrem über Ergebnisübermittlungen Eurerseits freuen.
Bin da doch etwas neugierig.
- Registriert
- Jan. 2018
- Beiträge
- 19.390
@TheCrazyIvan : Pentium E2140 @ 2,66 GHz, 80GB HDD, ASRock G31M-GS, 2GB DDR2-667 RAM
Captain, wir kavitieren
Captain, wir kavitieren
Anhänge
- Registriert
- Jan. 2018
- Beiträge
- 19.390
War es jetzt eigentlich möglich, das unter Windows XP mit Cinebench R10 laufen zu lassen?
Habe es gerade wieder auf einem alten Pentium laufen, der, laut ASRock eigener Software, im Single Core test bei 2,66 GHz ca. 7W benötigt (Power Saving Function: ON).
Habe es gerade wieder auf einem alten Pentium laufen, der, laut ASRock eigener Software, im Single Core test bei 2,66 GHz ca. 7W benötigt (Power Saving Function: ON).
- Registriert
- Dez. 2019
- Beiträge
- 130
@andi_sco
Leider scheint bei Deinem Conroe (Also der E2140) keine Package Power ausgelesen werden zu können. Genau so ergeht es mir leider auch mit meinem eigenen Phenom II X4 955 aus 2009. Die hatten damals halt noch keine (nach außen geführten) Sensoren dafür.
Windows XP wird mit hoher Wahrscheinlichkeit aufgrund der Anforderungen an die .NET-Version und Powershell-Version nicht funktionieren. Und CB10 hat einen ganz anderen Workload, sodass Ergebnisse damit nicht vergleichbar wären.
Leider scheint bei Deinem Conroe (Also der E2140) keine Package Power ausgelesen werden zu können. Genau so ergeht es mir leider auch mit meinem eigenen Phenom II X4 955 aus 2009. Die hatten damals halt noch keine (nach außen geführten) Sensoren dafür.
Windows XP wird mit hoher Wahrscheinlichkeit aufgrund der Anforderungen an die .NET-Version und Powershell-Version nicht funktionieren. Und CB10 hat einen ganz anderen Workload, sodass Ergebnisse damit nicht vergleichbar wären.
- Registriert
- Dez. 2019
- Beiträge
- 130
Starte mal den OpenHardwareMonitor und schicke nen Screenshot. Und zusätzlich einen Screenie von CPU-Z, dann kann ich mal schauen...andi_sco schrieb:
https://openhardwaremonitor.org/
HasseLadebalken
Banned
- Registriert
- Sep. 2015
- Beiträge
- 537
@TheCrazyIvan
Ist die Affinity darüber nun mittlerweile auch mal angepasst für den ST ?
Hier auch mal ein Zitat vom Curve Optimizer warum man die Affinity für ST strikt setzen muss
https://github.com/sp00n/corecycler
Das Scheduling verwurschelt sonst den ST
Sprich 1 Thread läuft nicht konstant auf demselben Kern und auch nicht nur auf diesem.
Das lässt sich sehr leicht beobachten wie der ST von Cinebench sich auf mehrere Kerne und SMT_Threads zu den Cores aufteilt.
ST im Alltag wäre ja beispielsweise Audacity nur auf Kern 2 (bzw Core 3, da Core 2 ja Kern1 ist, SMT, bei einem Ryzen 2000er)
Bei den Ryzen 2000er weiss man auch das Core 1 der 2. Thread (SMT) zum 1. Kern ist, so kann man mit HWInfo (Beobachten und feststellen) und Process Lasso (Eingreifen) von Bitsum das SMT ja quasi abschalten für gewisse Prozesse.
Beispielsweise CSGO, SMT deaktivieren, ist Core 2., 4...... (bzw core 1 und 3) dann abgeschalten, wenn man dann noch Kern 1 (Core 0) abschaltet, ist es im Ulletical FPS Benchmark reproduzierbar so das das Gesamtsystem mehr Frames produzieren kann ohne FPS-Limit, ohne VSync, am Ende des Benchmarks sieht man halt das man mehr FPS Average (avg.) hat, nachdem man das getan hat.
Was bei vielen älteren Spielen so ist, sicherlich kommt ein Overhead, Kernel oder sowas sich dann mit der Software die da auch laufen soll auf dem Kern in die Quere, wenn es eben nicht optimiert ist.
CSGO ist eing gutes Beispiel dafür deshalb weil das nicht grossartig auf mehr Kerne als 4 skaliert, immernoch, obwohl das seit zig Jahren ständig Updates bekommt.
Dadurch das das Game, den 1. Kern dann erst ab dem 2. Kern die restlichen Kerne benutzt und der wirklich erste Kern quasi nurnoch für den Overhead, Kernel oder sonstwas zuständig ist, haben wir so dadurch dann wohl die Performance mehr hinten raus dadurch.
Viel Mathematik lässt sich wohl auch nur auf dem allerersten Kern berechnen, dann ist es halt schlecht wenn sich das mit sonstiger Mathematik in die Quere kommt, wenn die es nicht müsste, weil wir ja ausreichend Kerne/Ressourcen zur Verfügung haben.
Ohne die Sache mit der "Affinity" kann man da also garkeine Stabilitätstest mit Cinebench machen.
Wenn das nun die Messungen hier weiterhin beeinflusst messen wir instabile OC's und sicherlich verfälscht das auch die Effizienzergebnisse.
Das Scheduling von Windows ist also gut wenn die Sachen optimiert sind, sind diese es nicht und das ist Cinebench im ST_Test/Bench mal so überhaupt nicht von Haus aus...nunja...
Gruss HL
Ist die Affinity darüber nun mittlerweile auch mal angepasst für den ST ?
Hier auch mal ein Zitat vom Curve Optimizer warum man die Affinity für ST strikt setzen muss
Quelle, Corecycler, Github:Die bisherigen Stabilitätstests mit PBO und dem Curve Optimizer waren entweder nicht zuverlässig (Cinebench,
Windows Repair) oder mit sehr viel Arbeit verbunden (manuell die Affinity über den Task Manager setzen, warten, neu
setzen, etc) oder gleich beides.
https://github.com/sp00n/corecycler
Das Scheduling verwurschelt sonst den ST
Sprich 1 Thread läuft nicht konstant auf demselben Kern und auch nicht nur auf diesem.
Das lässt sich sehr leicht beobachten wie der ST von Cinebench sich auf mehrere Kerne und SMT_Threads zu den Cores aufteilt.
ST im Alltag wäre ja beispielsweise Audacity nur auf Kern 2 (bzw Core 3, da Core 2 ja Kern1 ist, SMT, bei einem Ryzen 2000er)
Bei den Ryzen 2000er weiss man auch das Core 1 der 2. Thread (SMT) zum 1. Kern ist, so kann man mit HWInfo (Beobachten und feststellen) und Process Lasso (Eingreifen) von Bitsum das SMT ja quasi abschalten für gewisse Prozesse.
Beispielsweise CSGO, SMT deaktivieren, ist Core 2., 4...... (bzw core 1 und 3) dann abgeschalten, wenn man dann noch Kern 1 (Core 0) abschaltet, ist es im Ulletical FPS Benchmark reproduzierbar so das das Gesamtsystem mehr Frames produzieren kann ohne FPS-Limit, ohne VSync, am Ende des Benchmarks sieht man halt das man mehr FPS Average (avg.) hat, nachdem man das getan hat.
Was bei vielen älteren Spielen so ist, sicherlich kommt ein Overhead, Kernel oder sowas sich dann mit der Software die da auch laufen soll auf dem Kern in die Quere, wenn es eben nicht optimiert ist.
CSGO ist eing gutes Beispiel dafür deshalb weil das nicht grossartig auf mehr Kerne als 4 skaliert, immernoch, obwohl das seit zig Jahren ständig Updates bekommt.
Dadurch das das Game, den 1. Kern dann erst ab dem 2. Kern die restlichen Kerne benutzt und der wirklich erste Kern quasi nurnoch für den Overhead, Kernel oder sonstwas zuständig ist, haben wir so dadurch dann wohl die Performance mehr hinten raus dadurch.
Viel Mathematik lässt sich wohl auch nur auf dem allerersten Kern berechnen, dann ist es halt schlecht wenn sich das mit sonstiger Mathematik in die Quere kommt, wenn die es nicht müsste, weil wir ja ausreichend Kerne/Ressourcen zur Verfügung haben.
Ohne die Sache mit der "Affinity" kann man da also garkeine Stabilitätstest mit Cinebench machen.
Wenn das nun die Messungen hier weiterhin beeinflusst messen wir instabile OC's und sicherlich verfälscht das auch die Effizienzergebnisse.
Das Scheduling von Windows ist also gut wenn die Sachen optimiert sind, sind diese es nicht und das ist Cinebench im ST_Test/Bench mal so überhaupt nicht von Haus aus...nunja...
Gruss HL
Zuletzt bearbeitet:
Natürlich muss man die Affinity für den Curve Optimizer bei ST Stabilitätstests setzen. Das ist ja kein spezielles Problem von Cinebench, sondern gilt für jede ST Last, die einen speziellen Core belasten soll. Bei Prime95 gibt es dafür einen Kommandozeilenparameter, wodurch es einfach bequemer ist das für automatisierte Stabilitätstests zu verwenden. Mehr will der Autor damit nicht sagen. Er will damit nicht sagen, dass Cinebench nicht für ST optimiert ist.HasseLadebalken schrieb:Hier auch mal ein Zitat vom Curve Optimizer warum man die Affinity für ST strikt setzen muss
Für Performancetests mit Cinebench muss man die Affinity nicht setzen. Cinebench hat keine Probleme mit SMT und verliert auch nicht nennenswert Performance durch Core Hopping. Ich wüsste auch nicht wie man Cinebench für den ST Benchmark optimieren sollte. Hat man CPPC aktiviert, sollte Windows selbst dafür sorgen, dass die Anwendung auf den besten Cores läuft.
- Registriert
- Dez. 2019
- Beiträge
- 130
@HasseLadebalken
Ich stimme hier @Nolag zu. Wenn man die Stabilität eine konkreten Kernes testen will, muss man den Thread natürlich festtackern. Bei allem anderen ist der Kernwechsel "by design". Natürlich sollte die Windows Version aktuell und entsprechende Treiber installiert sein.
Zwei Gründe:
Im Alltag kommt auch niemand auf die Idee, Threads per Affinity Mask zuzuordnen. Und am Normalverhalten möchte ich mich schon orientieren.
Außerdem gibt es gute Gründe für den Kernwechsel - beispielsweise Hot Spots. Scheduler und CPU tauschen eine Vielzahl von Kenngrößen mit einander aus, um Kosten und Nutzen eines Kernwechsels abzuwägen. Ich bin geneigt, zu glauben, dass die vielen vielen schlauen Menschen bei AMD und MS das schon korrekt implementiert haben (ja, 2017 hat es zu Beginn geholpert, aber das ist nun mittlerweile vier Jahre her).
Ich stimme hier @Nolag zu. Wenn man die Stabilität eine konkreten Kernes testen will, muss man den Thread natürlich festtackern. Bei allem anderen ist der Kernwechsel "by design". Natürlich sollte die Windows Version aktuell und entsprechende Treiber installiert sein.
Zwei Gründe:
Im Alltag kommt auch niemand auf die Idee, Threads per Affinity Mask zuzuordnen. Und am Normalverhalten möchte ich mich schon orientieren.
Außerdem gibt es gute Gründe für den Kernwechsel - beispielsweise Hot Spots. Scheduler und CPU tauschen eine Vielzahl von Kenngrößen mit einander aus, um Kosten und Nutzen eines Kernwechsels abzuwägen. Ich bin geneigt, zu glauben, dass die vielen vielen schlauen Menschen bei AMD und MS das schon korrekt implementiert haben (ja, 2017 hat es zu Beginn geholpert, aber das ist nun mittlerweile vier Jahre her).
Ähnliche Themen
- Antworten
- 44
- Aufrufe
- 10.172


