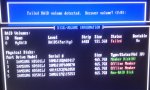
Zwei der Platten schwächeln ein wenig, mit schlecht lesbaren Sektoren.
Sowas wirft zwar den Onboard-Controller beim rebuild aus der Bahn, ist aber kein Problem, das wieder ohne Datenverlust zum Laufen zu kriegen.
Als erstes werden wir nach den Fehlstellen fahnden und die ausrotten.
Dazu mach das so wie hier beschrieben ist auf allen drei 500GB Raid Platten
Die textfiles benennst Du scandelay 1/2/3 .txt
Sowas wirft zwar den Onboard-Controller beim rebuild aus der Bahn, ist aber kein Problem, das wieder ohne Datenverlust zum Laufen zu kriegen.
Als erstes werden wir nach den Fehlstellen fahnden und die ausrotten.
Dazu mach das so wie hier beschrieben ist auf allen drei 500GB Raid Platten
Die textfiles benennst Du scandelay 1/2/3 .txt