Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
NewsUpgrade für AI-Chatbot: GPT-4o* und neue Funktionen für kostenlose ChatGPT-Version
Wie beim Spring Event angekündigt, können nun auch Nutzer der freien ChatGPT-Version die Zusatzfunktionen sowie das aktuelle Modell verwenden. Zu den Funktionen zählen das Web-Browsing – und somit der Zugang zu aktuellen Informationen –, Datenanalyse, Vision, der Daten- und Dokumenten-Upload sowie die GPTs.
also web durchsuchen ist echt krass. Ich kann super einfach mir Themen erklären lassen mit Quellen, und muss nicht google fragen und mich stundenlang einlesen
Ich habe 100 Seiten Arbeiten mit 100 Punkten Schemata bewerten lassen und auf nachfrage konnte es mir detalliert erläutern wie es auf die Punkteverteilung beim grading kommt. Schon beeindruckend.
Während ich mir ja durchaus mehrmals die Woche Grundgerüste für die unterschiedlichsten Probleme in verschiedenen Sprachen erzeugen lasse, habe ich solche eigentlich simplen Aufgaben bisher noch nicht korrekt gelöst bekommen - kann aber auch daran liegen, dass ich 'ne Niete im Erklären bin oder es hier immer noch keine Intelligenz gibt 😶
Oder - GPT A lässt GBT B die Arbeit schreiben, durch GPT C bewerten ... und falls es in diesem Kreislauf noch einen Menschen gibt, hört der nur "Alles nach Plan"
Also ich habs in der Kostenlosen Variante beim Thema Programmieren getestet. Hab in dem Chat ca. 4 Antworten von 4o bekommen. Dann ist er auf 3.5 gewechselt. Ich konnte keinen Unterschied feststellen
3.5 will mir erzählen, dass sich Schlamm auf Moritz reimt und die Wörter phonetisch total ähnlich sind. 4o macht das nicht. 4o arbeitet auch viel mehr mit Zwischenüberschriften und deutlicher Gliederung bei längeren Texten, dafür bemerke ich da irgendwie ab und zu Rechtschreibfehler.
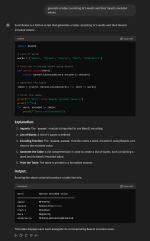
bei mir kam das im anhang raus. der code ist richtig, der output nicht. dafür müsste chatgpt den code auch ausführen und ich glaube, dass das openai lieber nicht möchte. da könnte man sonst seeehr viel schindluder mit treiben
"Apfel" müsste nach RFC 4648 eigentlich "IFYGMZLM" sein. "apple" wiederum "MFYHA3DF".
Eigentlich sollte man meinen, dass das eine ziemlich "einfache" Aufgabe ist, ein bekanntes und gut beschriebenes Kodierungsverfahren auf zufällig ausgewählte Wörter anzuwenden. Aber bereits ein so simples Beispiel zeigt einige Grenzen der populären LLMs auf. Auch spannend sehen Implementierungen für z.B. Java aus, die man bekommt, wenn man den RFC als Grundlage verwenden lässt. In den meisten Fällen sieht es nach schlechtem Copy & Paste der Apache Commons Codec Bibliothek aus. Am Ende funktioniert zwar das Grundgerüst, doch die Ergebnisse und hier on top auch noch die Implementierung, muss man komplett Schritt für Schritt überprüfen.
Ob ich dann ein solches Tool einsetzen möchte, um damit Analysen von Datenmengen durchführen zu lassen, Auswertungen anzufertigen .. eher nicht, wenn ich am Ende für die Prüfung so viel Arbeit reinstecken muss, wie eine eigene Beabeitung benötigt hätte.
@0x8100 Das wäre ja aber das Minimum. Kompilieren und den echten Code benutzen. Wenn das System intelligent wäre, könnte es ja erkennen ob ein Algorithmus schädlich ist und nicht ausgeführt werden soll(te) oder ob es etwas harmloses wie ein bisschen Base32 Kodierung ist.