riversource
Captain
- Registriert
- Juli 2012
- Beiträge
- 3.236
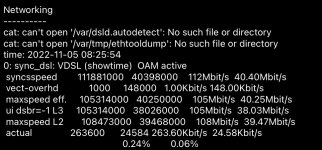
Ich fürchte, eher nicht. Das wäre das erste Mal, dass sie es nicht in einen eigenen daemon packen. Prädestiniert wäre der dsld (der sich nicht nur auf DSL Boxen ums gesamte Verbindungsmanagement und Routing kümmert). Der dsld hat u.a. folgende Kommandozeilenparameter:pufferueberlauf schrieb:under der Annahme, dass FritzOS das Shaping nit Linux-Bordmitteln realisiert?
Code:
-q STRING - specify tc fair queueing scheduler to use for egress shaping ("sfq"|"sfb"|"fq_codel"). ("sfq")
-t STRING - specify tc fair queueing scheduler to use for ingress shaping ("sfq"|"sfb"|"fq_codel"). ("fq_codel")