Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
CPU-Benchmark auf CB: SuperPi/MaxxPi2 ?
- Ersteller michi12
- Erstellt am
- Registriert
- März 2008
- Beiträge
- 1.030
Ok, ich Poste mal das Ergebnis, hardtech hat es mir per PM geschickt.
Nun wäre die Frage zu klären, wieso Intel bei gleichen Takt (3Ghz) um ca. 5sec. schneller ist bei 1M (E4300 vs. 5000+BE von aspro).
Liegt es an dem Programm, oder meint ihr, dass die Core-Architektur wirklich soviel effektiver ist ?
Bin gespannt auf eure Meinungen & weitere Ergebnisse !
Code:
hier die ergebnisse mit einem E4300 @ 3000 @ 333 FSB
1M 00:03,456,296,3Nun wäre die Frage zu klären, wieso Intel bei gleichen Takt (3Ghz) um ca. 5sec. schneller ist bei 1M (E4300 vs. 5000+BE von aspro).
Liegt es an dem Programm, oder meint ihr, dass die Core-Architektur wirklich soviel effektiver ist ?
Bin gespannt auf eure Meinungen & weitere Ergebnisse !
Zuletzt bearbeitet:
I
Ion
Gast
Illusionist | 1M | 00h 00m 02s 205ms 906µs | 464,2 K/sec. | Intel | E8600 | 4518 MHz | Luft | XP SP3
Illusionist | 4M | 00h 00m 14s 520ms 826µs | 282,1 K/sec. | Intel | E8600 | 4518 MHz | Luft | XP SP3
Illusionist | 32M | 00h 03m 09s 504ms 010µs | 172,9 K/sec. | Intel | E8600 | 4518 MHz | Luft | XP SP3
Illusionist | 4M | 00h 00m 14s 520ms 826µs | 282,1 K/sec. | Intel | E8600 | 4518 MHz | Luft | XP SP3
Illusionist | 32M | 00h 03m 09s 504ms 010µs | 172,9 K/sec. | Intel | E8600 | 4518 MHz | Luft | XP SP3
silent-efficiency
Banned
- Registriert
- Aug. 2004
- Beiträge
- 5.253
Volker schrieb:Da jetzt bald wieder ein neues Testsystem aufgesetzt wird, steh ich wieder vor einer riesigen Auswahl an Tools. Nur ob die dann mit einem Nehalem oder Deneb auch funktionieren ist eine ganz andere Frage,...
Ich hoffe, es gibt auch Dual-Cores im neuen Testparcour, also auch E8600 bis E8400....
@Topic
sieht doch bisher recht gut aus, als Ersatz herzuhalten..
Zuletzt bearbeitet:
- Registriert
- März 2008
- Beiträge
- 1.030
silent-efficiency schrieb:Ich hoffe, es gibt auch Dual-Cores im neuen Testparcour, also auch E8600 bis E8400....
silent-efficiency, es wird ein neues Testsystem auf Nehalem-Basis aufgesetzt, da wird es ganz sicher keine E8600 geben, weil der Sockel ja ein ganz anderer sein wird (LGA1366, nicht LGA775)
@Topic:
Was meint ihr dazu ?Nun wäre die Frage zu klären, wieso Intel bei gleichen Takt (3Ghz) um ca. 5sec. schneller ist bei 1M (E4300 vs. 5000+BE von aspro).
Liegt es an dem Programm, oder meint ihr, dass die Core-Architektur wirklich soviel effektiver ist ?
Bin gespannt auf eure Meinungen & weitere Ergebnisse !
Weiterhin ist natürlich jedes Bench-Ergebnis willkommen
berres
Lt. Junior Grade
- Registriert
- Mai 2004
- Beiträge
- 295
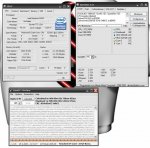
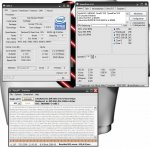
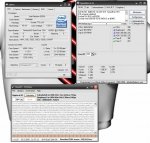
silent-efficiency
Banned
- Registriert
- Aug. 2004
- Beiträge
- 5.253
michi12 schrieb:silent-efficiency, es wird ein neues Testsystem auf Nehalem-Basis aufgesetzt, da wird es ganz sicher keine E8600 geben, weil der Sockel ja ein ganz anderer sein wird (LGA1366, nicht LGA775)")
Ich sprach nicht vom Testsystem sondern vom Testparcour. AMDs CPUs setzen auch auf einen komplett anderen Sockel sammt anderem Board und werden dennoch im selben Testparcour getestet um einen Vergleich zu haben und genau so kann man auch die Dual-Cores auf dem LGA775 im selben Testparcour gegen die Nehalems antreten lassen
michi12 schrieb:Nun wäre die Frage zu klären, wieso Intel bei gleichen Takt (3Ghz) um ca. 5sec. schneller ist bei 1M (E4300 vs. 5000+BE von aspro).
Liegt es an dem Programm, oder meint ihr, dass die Core-Architektur wirklich soviel effektiver ist ?
Bin gespannt auf eure Meinungen & weitere Ergebnisse !
Klar ist die Core-Architektur effektiver als die alten X2. Daran gibt es keine Zweifel.
Zuletzt bearbeitet:
Tamahagane
Vice Admiral
- Registriert
- Jan. 2008
- Beiträge
- 6.626
Ok, sitze gerade vor meinem Notebook, daher auch mal etwas lahmere Ergebnisse 
Ball_Lightning | 1M | 00h 00m 06s 389ms 171µs | 160,3 K/sec. | Intel | T5500| 1660 MHz | Luft | Vista Home Premium
Ball_Lightning | 4M | 00h 00m 36s 466ms 603µs | 121,3 K/sec. | Intel | T5500| 1660 MHz | Luft | Vista Home Premium
Auf 32M verzichte ich lieber, würde etwas zu lang dauern Ich würde aber zu gern das Ergebnis von meinen Opteronen sehen... leider komm ich erst Ende der nächsten Woche wieder an den Rechner.
Ich würde aber zu gern das Ergebnis von meinen Opteronen sehen... leider komm ich erst Ende der nächsten Woche wieder an den Rechner.
Ball_Lightning | 1M | 00h 00m 06s 389ms 171µs | 160,3 K/sec. | Intel | T5500| 1660 MHz | Luft | Vista Home Premium
Ball_Lightning | 4M | 00h 00m 36s 466ms 603µs | 121,3 K/sec. | Intel | T5500| 1660 MHz | Luft | Vista Home Premium
Auf 32M verzichte ich lieber, würde etwas zu lang dauern
dann hast du's wohl falsch verstandenmichi12 schrieb:So wie ich das verstanden habe, benutzt SuperPi eine veraltete (1995) Technik (X87-FPU), um die Zahl Pi zu berechnen.
Zunächst einmal ist 1995 das Jahr, in dem SuperPI programmiert wurde, nicht das Jahr auf dessen Stand die FPU-Technologie stehengeblieben wäre. Die FPU wurde und wird mit jeder CPU-Generation mit weiterentwickelt. So hat AMD die FPU beim Schritt vom K6 zum K7 deutlich verbessert, ebenso beim Schritt vom K7 zum K8. Ich selbst hatte zwar nie einen K6, weiß aber noch sehr gut, dass 1997/98 AMD-CPUs den Ruf hatten, in der FPU-Leistung dem Pentium1 - und erst recht dem Pentium II - unterlegen zu sein, was AMD beim K6-2 dann mit 3DNow! zu kompensieren versuchte, wozu aber speziell angepasste Software erforderlich war. Die FPU-Leistung des K7 dagegen konnte dann mit der des Pentium III mithalten. Mit dem K7 war AMD Intel FPU-mäßig erstmals ebenbürtig. Beim K8 wurde dann die Pro-MHz-Leistung verbessert, und damit auch die der FPU.
Zum zweiten ist es zwar richtig, dass seit einigen Jahren der Trend dahingeht, FP-Berechnungen von der FPU auf die SSE-Einheit auszulagern. Das machen aber keineswegs alle Programme so wie der Flash Player, zumal es auch nicht immer sinnvoll ist, da SSE und MMX auf Parallelisierung aufbauen, die nicht bei allen Arten von Berechnungen möglich ist. Leute, die selbst programmieren, haben zudem noch immer das Problem, dass die Compiler-Unterstützung für SSE bislang sehr schlecht aussieht. Sofern man nicht gerade einen Intel-Compiler benutzt, bleibt da nur der Zugang über Inline-Assembler. Von daher ist die FPU-Leistung noch immer ein wichtiges Feature.
Ich persönlich würde es am sinnvollsten halten, einen Benchmark für drei Leistungsdaten anzubieten: ALU-Integer-Leistung, FPU-Leistung, SSE/MMX-Leistung.
Indes frage ich mich auch, woher dein Informant eigentlich die Information hat, dass SuperPI die FPU benutzt. Ich habe nämlich selbst schon einmal versucht herauszufinden, welcher Teil der CPU da benutzt wird, und bin daran gescheitert, dass die SuperPI-Programmierer das ziemlich unter Verschluss halten. Irgendwo habe ich dann mal aufgeschnappt, es würde die ALU, also die Integer-Einheit genutzt. Das wäre auch keineswegs so abwegig: die IEEE-754 Norm für Gleitkommazahlen bietet im double precision Format ja gerade mal 16 Dezimalstellen an - für 1 Million Stellen von PI also völlig ungeeignet. SuperPI muss also irgendeine Art von Langzahlarithmetik verwenden, und eine solche kann man ebensogut auf Integer-Zahlen aufbauen.
gerade das könnte sich als fatal erweisen, weil man dann die Ergebnisse unterschiedlicher MaxxPi2-Versionen ggf. nicht mehr vergleichen kann. Für einen brauchbaren Benchmark ist ein fester, unveränderlicher Standard vonnöten.michi12 schrieb:Außerdem wird MaxxPi2 weiterentwickelt/verbessert (siehe Webseite).
Naitsabes
Lt. Commander
- Registriert
- Sep. 2007
- Beiträge
- 1.332
AMD Athlon x2 4200+ (Windsor) @ 2.2Ghz; OS = Vista x86
1M | 00h 00m 10s 296ms 416µs | 99,5 K/s
2M | 00h 00m 22s 416ms 556µs | 91,4 K/s
4M | 00h 00m 53s 955ms 708µs | 75,9 K/s
8M | 00h 01m 54s 574ms 316µs | 71,5 K/s
16M | 00h 04m 28s 449ms 994µs | 61 K/s
32M | 00h 09m 38s 842ms 776µs | 56,6 k/s
Theoretische berechenete geratene Werte:
64M | 00h 18m 77s 658ms 552µs | ~ 50 K/s
128M | 00h 37m 553s 171ms 040µs | ~ 44,3 K/s
Edit:
Bei bedarf könnte ich auch mit niedrigeren Frequenzen Benchen, mehr Takt geht leider nicht, da meine Cpu für 2.2Ghz bereits 1,325V braucht und ich daher bezweifle, dass ich über 2.4Ghz komme -.-
1M | 00h 00m 10s 296ms 416µs | 99,5 K/s
2M | 00h 00m 22s 416ms 556µs | 91,4 K/s
4M | 00h 00m 53s 955ms 708µs | 75,9 K/s
8M | 00h 01m 54s 574ms 316µs | 71,5 K/s
16M | 00h 04m 28s 449ms 994µs | 61 K/s
32M | 00h 09m 38s 842ms 776µs | 56,6 k/s
Theoretische berechenete geratene Werte:
64M | 00h 18m 77s 658ms 552µs | ~ 50 K/s
128M | 00h 37m 553s 171ms 040µs | ~ 44,3 K/s
Edit:
Bei bedarf könnte ich auch mit niedrigeren Frequenzen Benchen, mehr Takt geht leider nicht, da meine Cpu für 2.2Ghz bereits 1,325V braucht und ich daher bezweifle, dass ich über 2.4Ghz komme -.-
Anhänge
Zuletzt bearbeitet:
JohnPreston
Lieutenant
- Registriert
- Sep. 2008
- Beiträge
- 736

[o.0]
Lt. Commander
- Registriert
- Apr. 2008
- Beiträge
- 1.059
[o.0] | 4M | 30s 987ms 828μs | 132,2 K/sec | Intel | E6400 | 2133Mhz | LuKü | Win XP
Ich hoffe Everest geht auch, hab CPUz grade nich drauf
Ich hoffe Everest geht auch, hab CPUz grade nich drauf
hi,
maxxpi nutzt mmx/sse(2) intensiv, dies ist cpu (core) unabhängig zu sehen.
von daher werden natürlich auch alle kommenden cpu's *unterstützt...
die PI routine ist schon seit langem *final, an ihr wird nichts mehr verändert.
(jetzt ausgenommen von z.b. bluescreens die aufgrund der PI routine auftreten würden oder ähn. schwerwiegende bugs),
von daher werden alle ergebnisse von jetzt (und auch von vor z.b. 1monat) auch in zukunft vergleichbar sein und
natürlich auch mit allen kommenden versionen in der zukunft")
bitte lest hierzu die FAG.
zur info:
reine cpubenchs (also im cache der cpu), memory usage:
128K = ca. 1.1mb
256K = ca. 2.05mb
512K = ca. 3.8mb
vielleicht noch der 1M = ca.7.4mb
darüber hinaus geht alles in's ram, je höher die zu berechnende
PI konstante, desto mehr gewinnt das ram (und dessen settings)
an bedeutung.
formel:
ich nutze eine von mir modifizierte version
der Gauss-Legendre formel zum berechnen der kreiszahl pi.
für intressierte: http://www.uni-leipzig.de/~sma/pi_einfuehrung/ausblick.html
sse/mmx:
intern wird die berechnung u.a. durch Fast Fourier/Cosine/Sine transformationen unterstützt,
diese basieren alle auf Double/Long variablen, die wiederum in der FPU(NPU) der CPU ablaufen.
hier in dieser MaxxPI-PreView ist die PI routine als Singlecore variante gedacht.
das heisst: es wird max. 1core ausgelastet.
also singelcore cpu's = 100% last, dualcore=50% last, tripple=33% usw. ...
MaxxPI² wird *Multi-core fähig sein (bzw. ist es schon).
momentan verden 1-4cores unterstützt.
siehe hier: www.MaxxPI.com
cu
Volker schrieb:Da jetzt bald wieder ein neues Testsystem aufgesetzt wird, steh ich wieder vor einer riesigen Auswahl an Tools. Nur ob die dann mit einem Nehalem oder Deneb auch funktionieren ist eine ganz andere Frage, und wenn sie funktionieren, ob die Ergebnisse halbwegs realistisch sein können, wenn die Software offiziell noch keinen Support für eben jene CPUs bietet. Da man beispielsweise von Intel die CPus meist Wochen vor dem offiziellen Start bekommt, kann man das der Software auch nicht vorwerfen. Jedoch disqualifiziert sie das leider für den Test, denn für ewiges Nachbenchen haben wir hier bei CB keine Zeit.
maxxpi nutzt mmx/sse(2) intensiv, dies ist cpu (core) unabhängig zu sehen.
von daher werden natürlich auch alle kommenden cpu's *unterstützt...
Sculletto schrieb:...gerade das könnte sich als fatal erweisen, weil man dann die Ergebnisse unterschiedlicher MaxxPi2-Versionen ggf. nicht mehr vergleichen kann. Für einen brauchbaren Benchmark ist ein fester, unveränderlicher Standard vonnöten.
die PI routine ist schon seit langem *final, an ihr wird nichts mehr verändert.
(jetzt ausgenommen von z.b. bluescreens die aufgrund der PI routine auftreten würden oder ähn. schwerwiegende bugs),
von daher werden alle ergebnisse von jetzt (und auch von vor z.b. 1monat) auch in zukunft vergleichbar sein und
natürlich auch mit allen kommenden versionen in der zukunft
bitte lest hierzu die FAG.
zur info:
reine cpubenchs (also im cache der cpu), memory usage:
128K = ca. 1.1mb
256K = ca. 2.05mb
512K = ca. 3.8mb
vielleicht noch der 1M = ca.7.4mb
darüber hinaus geht alles in's ram, je höher die zu berechnende
PI konstante, desto mehr gewinnt das ram (und dessen settings)
an bedeutung.
formel:
ich nutze eine von mir modifizierte version
der Gauss-Legendre formel zum berechnen der kreiszahl pi.
für intressierte: http://www.uni-leipzig.de/~sma/pi_einfuehrung/ausblick.html
sse/mmx:
intern wird die berechnung u.a. durch Fast Fourier/Cosine/Sine transformationen unterstützt,
diese basieren alle auf Double/Long variablen, die wiederum in der FPU(NPU) der CPU ablaufen.
hier in dieser MaxxPI-PreView ist die PI routine als Singlecore variante gedacht.
das heisst: es wird max. 1core ausgelastet.
also singelcore cpu's = 100% last, dualcore=50% last, tripple=33% usw. ...
MaxxPI² wird *Multi-core fähig sein (bzw. ist es schon).
momentan verden 1-4cores unterstützt.
siehe hier: www.MaxxPI.com
cu
Zuletzt bearbeitet:
michi12 schrieb:@alice:
Kann man die Version die multi-cores unterstützt auch irgendwo herunterladen ?
hi,
nein, die akt. beta von maxxpi² ist nicht öffentlich.
jedoch bin ich immer auf der suche nach beta-testern mir exotischer HW,
wie zum bsp. extrem OC (kokü) oder einen AMD Tripple core...
hierzu bitte -> PM zwecks teilname an der betaphase mit angabe der verwendeten
HW
cu
alice
moneymaker4ever
Commodore
- Registriert
- März 2008
- Beiträge
- 4.179
moneymaker4ever | 512K | 1s 528ms 418µs | 335,0 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 1M | 3s 650ms 787µs | 280,5 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 2M | 8s 028ms 153µs | 255,1 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 4M | 20s 182ms 476µs | 202,9 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 8M | 45s 208ms 641µs | 181,2 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 16M | 1m 43s 956ms 257µs | 157,6 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 1M | 3s 650ms 787µs | 280,5 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 2M | 8s 028ms 153µs | 255,1 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 4M | 20s 182ms 476µs | 202,9 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 8M | 45s 208ms 641µs | 181,2 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
moneymaker4ever | 16M | 1m 43s 956ms 257µs | 157,6 K/sec | Intel | E8200 | 2666Mhz | Lukü | XP 32
du nutzt? D.h. du bist der Programmierer von MaxxPi?alice schrieb:formel:
ich nutze eine von mir modifizierte version
der Gauss-Legendre formel zum berechnen der kreiszahl pi.
für intressierte: http://www.uni-leipzig.de/~sma/pi_einfuehrung/ausblick.html
sse/mmx:
intern wird die berechnung u.a. durch Fast Fourier/Cosine/Sine transformationen unterstützt,
diese basieren alle auf Double/Long variablen, die wiederum in der FPU(NPU) der CPU ablaufen.
Den letzten Satz verstehe ich nicht so ganz. Welche Einheit der CPU wird jetzt genutzt, SSE, MMX oder die FPU, oder teils teils? Und was sollen Variablen sein, die ablaufen? Variablen laufen nicht ab, Berechnungen laufen ab, Variablen werden dabei höchstens verändert



