Ohne Gehäuse
Cadet 4th Year
- Registriert
- März 2010
- Beiträge
- 74
Hi,
In diesem Thread moechte ich euch meinen CPU Benchmark vorstellen. Er ist single-threaded. In dem Benchmark muss die CPU die Umlaufbahn von 1000000 Steine um einen Planeten im Weltall berechnen. Da viele Zahlen zufaellig generiert werden variiert die Zeit die der Benchmark braucht um fertig zu werden. Ich plane eine Highscoreliste in diesem Thread und auf meiner Webseite zu veroeffentlichen.
Hier koennt ihr den Benchmark herunterladen:
2shared - download CPU Benchmark (Single-threaded).zip
Bitte postet eure Resultate in diesem Format:

Viel Spass mit dem Benchmark,
thysol
Highscore Liste:

Dieser neue Benchmark braucht laenger zum durchlaufen, damit wird die Genauigkeit erhoeht. Die Genauigkeit habe ich auch mit Tweaks im Code stark erhoeht. Hier koennt ihr den Benchmark herunterladen:
2shared - download CPU Benchmark (Single-threaded) v1.1.zip
Bitte postet wieder in diesem Format:

Highscore Liste:

Hier ist mein neuer multi-threaded CPU Benchmark. Diesmal muss die CPU die Umlaufbahn von 100000000 Steine um einen Planeten berechnen, das ist 100 mal mehr als vorher. Daher braucht der Benchmark jetzt laenger um durchgefuehrt zu werden. Hier koennt ihr euch den Benchmark herunterladen:
2shared - download CPU Benchmark (Multi-threaded).zip
Hier ist mein Resultat, postet bitte wieder in diesem Format:

Highscore Liste:

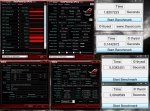
Ich habe jetzt auch einen GPU benchmark mit dem selben Algorithm programmiert. Hier gibt es allerdings einiges zu beachten:
1. Den Benchmark mindestens 2 mal durchlaufen lassen denn im ersten Durchlauf muss OpenCL initialisiert werden. Die daraufolgenden Durchlaeufe sollten aber alle nahezu gleich sein.
2. Der Benchmark kann bei sehr langsamen Grafikkarten zu einem Systemabsturz fuehren! Benutzung des Benchmarks auf eigene Gefahr!
3. Ihr muesste den Benchmark aus dem originalen Ordner heraus ausfuehren. Die Datei, Cloo.dll muss im selben Ordner liegen wie die .exe.
Hier ist der Download Link:
2shared - download GPU benchmark v1.0.zip
Bitte postet eure Resultate in diesem Format:

Highscore Liste:

In diesem Thread moechte ich euch meinen CPU Benchmark vorstellen. Er ist single-threaded. In dem Benchmark muss die CPU die Umlaufbahn von 1000000 Steine um einen Planeten im Weltall berechnen. Da viele Zahlen zufaellig generiert werden variiert die Zeit die der Benchmark braucht um fertig zu werden. Ich plane eine Highscoreliste in diesem Thread und auf meiner Webseite zu veroeffentlichen.
Hier koennt ihr den Benchmark herunterladen:
2shared - download CPU Benchmark (Single-threaded).zip
Bitte postet eure Resultate in diesem Format:
Viel Spass mit dem Benchmark,
thysol
Highscore Liste:
CPU Benchmark (single-threaded) v1.1
Dieser neue Benchmark braucht laenger zum durchlaufen, damit wird die Genauigkeit erhoeht. Die Genauigkeit habe ich auch mit Tweaks im Code stark erhoeht. Hier koennt ihr den Benchmark herunterladen:
2shared - download CPU Benchmark (Single-threaded) v1.1.zip
Bitte postet wieder in diesem Format:
Highscore Liste:
CPU Benchmark (multi-threaded)
Hier ist mein neuer multi-threaded CPU Benchmark. Diesmal muss die CPU die Umlaufbahn von 100000000 Steine um einen Planeten berechnen, das ist 100 mal mehr als vorher. Daher braucht der Benchmark jetzt laenger um durchgefuehrt zu werden. Hier koennt ihr euch den Benchmark herunterladen:
2shared - download CPU Benchmark (Multi-threaded).zip
Hier ist mein Resultat, postet bitte wieder in diesem Format:
Highscore Liste:
GPU Benchmark v1.0
Ich habe jetzt auch einen GPU benchmark mit dem selben Algorithm programmiert. Hier gibt es allerdings einiges zu beachten:
1. Den Benchmark mindestens 2 mal durchlaufen lassen denn im ersten Durchlauf muss OpenCL initialisiert werden. Die daraufolgenden Durchlaeufe sollten aber alle nahezu gleich sein.
2. Der Benchmark kann bei sehr langsamen Grafikkarten zu einem Systemabsturz fuehren! Benutzung des Benchmarks auf eigene Gefahr!
3. Ihr muesste den Benchmark aus dem originalen Ordner heraus ausfuehren. Die Datei, Cloo.dll muss im selben Ordner liegen wie die .exe.
Hier ist der Download Link:
2shared - download GPU benchmark v1.0.zip
Bitte postet eure Resultate in diesem Format:
Highscore Liste:
Zuletzt bearbeitet: