Tim-O schrieb:
Bis auf die 992 UltraDMA-CRC-Fehler und hohe Lesefehlerrate.
Bei den anderen Platten ist beides auf 0, weswegen ich von einem schleichenden Tod ausgehe
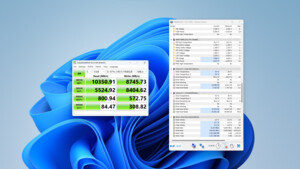
Die UltraDMA CRC Fehler (also Kommunikaitonsfehler zwischen dem SATA Host Controller und dem Controller der Platte) werden in aller Regel über die Lebenszeit des Laufwerks gezählt, der Zählerstand fällt also nie. Daher reicht es, wenn der nach dem Beheben des Problems eben nicht mehr steigt, denn dann kommen ja keine weiteren Fehler hinzu, es gibt dann also keine neuen Kommunkationsfehler. Was die Lesefehler angeht, so hängt dies von der Platte ab, bei Seagate HDDs sind die Rohwerte der Attribute Seek Error Rate, Raw Read Error Rate und Hardware ECC Recovered nicht einfache Zählerstände der Fehler, sondern enthalten die Fehlerzähler nur in den 2 höchsten Bytes (die linken 4 Stellen
bei hexadezimaler Anzeige der Rohwert in CrystalDiskInfo) und die rechten 8 Stellen (4 Byte) sind der Zähler der Vorgänge. Bei einigen wenigen SSDs ist wohl auch so ähnlich, zumindest habe ich bei einige mit Sandforce schon mal so gesehen und ich meine irgendwo bei irgendeiner von Kingston war es auch so dokumentiert. Poste man den Screenshot mit den ganzen Werten, dann sollte man erkennen wie es um die Platte steht.
Fred_EM schrieb:
Je mehr Bits ich pro Speicherzelle realisiere, desto unsicherer/fehleranfälliger/korrekturbedürftiger wird das Ganze.
Das mag auf der Ebene einzelner Zellen ja auch stimmen, aber man liest ja nie einzelne Zellen direkt aus, sondern hat in einer SSD, einem Stick oder eine Speicherkarte immer noch einen Controller und der hat immer eine ECC, denn Bitfehler sind bei Flash wie auch bei HDDs einfach normal und die höhere Wahrscheinlichkeit eines solchen Bitfehlers kann man dann mit einer entsprechend stärkeren ECC auch kompensieren, so dass die SSD selbst am Ende eben keine höhere Fehlerrate aufweist. Außerdem kommen Bitfehler bei NANDs erst ab einem bestimmten Alter und sind anderes als bei HDDs eben nicht linear über die Nutzungsdauer verteilt.
rockwell1080 schrieb:
aber die Crucial Software sagt sie wäre gut!
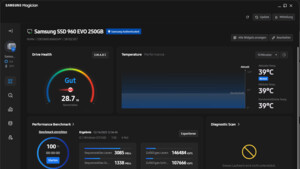
Das ist ja auch kein Wunder, die SW der Herstelle ist für deren Garantie relevant und da spart es eben Kosten, wenn man ein Auge zudrückt. Die hat ja auch NAND Reserven, wie E4 verrät sind noch 1085 Reserveblöcke verfügbar, obwohl also schon 168 ausgefallen sind, entsprechen sind, wie der Aktuelle Wert von Attribut 05 verrät, noch etwa 85% der Reserven verfügbar und der Grenzwert von 10 besagt, dass Crucial er erst als kritisch einschätzt wenn nur noch 10% der Reserve verfügbar sind.
Wie kritisch das ist, hängt davon ab wie schnell weitere Blöcke ausfallen, unangenehm ist es aber trotzdem, zumal es eben mit Datenkorruption verbunden ist. Bei Crucial SSDs haben ich sowas aber auch schon vorher mal gesehen, die sind eben meist billiger aber offenbar bzgl. der FW und der Qualitätskontroller der NANDs nicht so gut wie es Samsung ist, denn bei deren SSDs, die noch weiter verbreitet sein dürften, kann ich mich nicht an solche Fälle erinnern. Dabei hat die sogar RAIN, also eine Art RAID 5 über die NAND Blöcke und damit dürfte dies eigentlich nicht passieren, denn auch der Ausfall eines Blocks sollte eigentlich keinen Datenverlust zur Folge haben. Offenbar ist da zuweilen mehr als ein Block des RAIN Verbundes betroffen gewesen, daher weshalb eben nur ein Teil der Fehler durch RAIN korrigiert werden konnten.
rockwell1080 schrieb:
Laut chkdsk befinden sich 2428KB auf defekten Sektoren. Bei einer Überprüfung vor einer Woche waren es aber 16KB weniger...
Waren denn vor einer Woche auch schon 168 Blöcke ausgefallen? Wenn ein NAND Block ausfällt, kann dies natürlich viele Sektoren betreffen.
rockwell1080 schrieb:
Und an diesen Daten scheitert wohl dann Acronis.
Die SSD dürfte dann einen Lesefehler melden und dann brechen die meisten Backup- und auch Klone Tools ab, sofern nicht entsprechende Einstellungen vorhanden und aktiviert sind.