TheCrazyIvan schrieb:
@Bigeagle
Sehr interessante Beobachtung. Laut Website der Bibliothek, die ich verwende, sollte Ivy Bridge eigentlich unterstützt werden:
https://openhardwaremonitor.org/documentation/
Vielleicht schaust Du Dir das Ganze noch einmal an, während Du den OpenHardwareMonitor sowie HWInfo parallel laufen lässt.
Ich gehe davon aus dass die wie hwinfo64 auch nur die Werte ausliest die die CPU bereitstellt. Da dürfte sich, bugs außen vor, nichts ändern wenn man die library wechselt mit der die Daten ausgelesen werden.
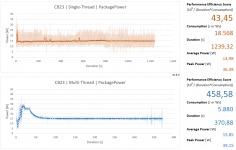
Dazu stimmen die Werte ja an sich, ist nicht so als würde da etwas nicht so funktionieren wie es meines wissens nach soll. Nur ist das was rauskommt eben nicht das was viele denken das es ist. Es kann aber sein dass bei neueren Generationen tatsächlich Strom und Spannung gemessen werden, oder Änderungen an Spannung und Takt mit in die Schätzung einfließen. Wenn die CPU exakt mit stock settings ohne Turbo läuft kommen die Werte ja hin.
TheCrazyIvan schrieb:
In meinen Augen besteht das Problem dieses Ansatz darin, dass das Sampling teilweise sehr unterschiedlich ausfällt - also auch innerhalb eines Runs differiert das bei meiner Maschine teilweise sehr stark. Das einmalige Messen der "Messdauer" würde da IMHO nicht viel bringen. Auf die 10ms bin ich wie gesagt empirisch gekommen - zumindest bei meiner Maschine hat das Weglassen der Begrenzung nach unten nicht zu einer signifikanten Steigerung der Sample-Anzahl geführt.
Deshalb ja die Idee zu messen, aber nicht einmalig, sondern innerhalb der Schleife. Die Zeit abrufen sollte nicht zu teuer sein. Kurzer Test in Python bei mir sagt dass time.time() (welches sekunden seit epoch als float zurückgibt) etwas mehr als 10 Mio. mal pro Sekunde durchläuft.
Es soll ja dafür sorgen dass der genaue Takt der Messungen eingehalten wird wenn möglich, unabhängig davon ob einzelne Messungen mal länger dauern, oder allgemein auf der gerade zu testenden Maschine langsam sind.
Vielleicht machts ein Beispiel einfacher.
Angenommene Benchmarkzeit jeweils 60 Sekunden.
Fall 1: Messung dauert 1 ms, danach 10 ms sleep. Die erste Messung findet bei 0 ms statt, die zweite bei 11, die dritte bei 22 usw. Es finden 5454 Messungen statt.
Fall 2: Messung dauert 1 ms, danach 9 ms sleep, zweite Messung dauert 5 ms, danach nur 5 ms sleep, dritte Messung 2 ms, danach 8 ms sleep. Es finden 6000, bzw 5999 Messungen statt, je nachdem ob die letzte noch gemacht wird da der Benchmark ja exakt zu beginn beendet ist
")
Zusätzlich würde ich mitzählen und angeben wie viele Messungen ausgefallen sind weil sie ihr Zeitfenster nicht geschafft haben. Das hilft ggf. bei der Fehlersuche wenn komische Ergebnisse rauskommen und zeigt dass das Interval zu kurz war, bzw der PC zu langsam.
Ich finde in der Doku leider nichts eindeutiges zur Art wie die Werte ermittelt werden. Aber ggf. könnte man per low-level zugriff genauere Werte bekommen, denn die geben tatsächlich Energie an und nicht Leistung.
Kapitel 14.10, Seite 45 MSR_PKG_ENERGY_STATUS
Bei ungefähr 60 Sekunden Wraptime braucht man sich auch keinen Stress mit dem Sampling machen.
Leider stehe ich gerade total auf dem Schlauch bei der Frage wie viel denn nun safe in das Register passt. 15,3 µJ als Standardeinheit, 32 bit unsigned Int. Irgendwie kommt da nichts sinnvolles in Verbindung mit den 60 Sekunden raus. Außer Intel hat tatsächlich über 500 W einkalkuliert.
Eigentlich würde das die ganze Messung erheblich vereinfachen (Messung am Start, Ende und mindestens einmal pro Minute mittendrin und am Ende addieren) und würde Fehler durchs Sampling vermeiden.
Für AMD weiß ich auf die Schnelle nix. Da kann jemand anders suchen ^^
P.S.:
Die übergeordnete Seite zu den Intel Architecture Dokus