Während ein Kaby-Lake-Kern ungefähr 12,2 mm² klein ist, wächst dieser mit Skylake-SP auf etwa 17 mm² an.
Weshalb die Skylake-SP auch eigentlich keine Skylake sind, da die Kerne sich deutlich von denen der Mainstream Skylake CPUs unterscheiden. Das war aber schon immer so, trotz gleicher Namen war die Architekturen nie wirklich gleich.
Die Zen-Kerne bei Ryzen & Co, so wie sie auch bei Threadripper und Naples alias Epyc zum Einsatz kommen werden, sind lediglich 11,0 mm² klein.
Was aber auch an dem Funktionsumfang liegen dürfte, man schaue sich nur die AVX2 Performance an und sollte auch nicht vergessen, dass nur Skylake-SP auch AVX512 bietet. Dazu kommen Technologien wie TSX um den Performanceverlust bei Synchronisierungen zwischen den Threads der SW und damit den Kernen der CPU, auch möglichst gering zu halten.
kdvd schrieb:
Mich würde ja mal die Bandbreite von AMDs Infinity Fabric für Ryzen interessieren und wieviel davon am Ende noch beim sagen wir mal 16. bzw 32. Kern ankommt.
Das wird eben davon abhängen wie sehr die Threads der SW voneinander abhängen und damit die Kerne miteinander kommunizieren müssen. Wenn das viel ist, hat schon RYZEN ein Performanceproblem, man kann das per SW Optimierung auch nur in Grenzen mindern, weil man sich sonst eben auf die maximal 4 Kerne eines CCX beschränken muss. Bei 16 und 32 Kerner wird es dann statistisch schlechter aussehen, sind bei 8 Kernen noch 50% aller Kerne auf dem gleichen CCX, so sind es bei 16 Kernen und 2 Dies nur noch 25% und beim 32 Kerner nur 12,5%, die Wahrscheinlich das sich der andere Kern mit dem ein Kern kommunizieren muss auf dem gleichen CCX liegt, nimmt also massiv ab.
Dazu kommt, dass die Latenz zwischen den CCX auf unterschiedlichen Die auch noch mal höher als die zwischen den beiden CCX eines Dies sein dürfte. AMDs Vielkerner dürften nur dort stark abschneiden wie jeder Kern viel auf seinem eigenen Teil der Daten rumrechnen muss, ganz wie es ist wenn man GPUs Berechnungen anstellen lässt.
Atent123 schrieb:
Das Infinity Fabric innerhalb des Zeppelin DIEs hat 25 GB/s Bandbreite bei 2100mhz Ram.
Das Infinty Fabric das die DIEs verbindet 60 GB/s (wurde auf dem AMD financial Day gesagt.)
2100MHz RAM, das wäre dann DDR4-4200, aber so hoch geht der RAM Controller von RYZEN gar nicht und dies sind auch noch gar nicht spezifiziert, derzeit kennt die JEDEC nur DDR4 bis 3200. DDRR4-2100 gibt es auch nicht, nur 2133, also mit 1066MHz. Außerdem nutzt es nichts wenn die externe Fabric schneller ist als die intern, da wäre dann die interne der Flaschenhals, aber ich vermute diese 60GB/s werden durch drei geteilt und binden dann bei EPYIC jeweils einen der drei anderen Dies an, bei ThreadRipper würden dann eine oder maximal zwei dieser Verbindungen genutzt werden um die beiden Dies zu verbinden, die kosten ja auch Leistung und erzeugen damit Wärme.
Das Problem ist aber weniger die Bandbreite, die könnte auch ein Problem werden wenn z.B. die Kerne ständig auf RAM zugreifen müssen welches am RAM Controller eines anderen Dies hängt, sondern eher die Latenz das Anbindung. Die dürften natürlich zusätzlich ansteigen, wenn die Bandbreite auch massiv genutzt wird.
ampre schrieb:
Eben nicht! Kühlen kannst du die 4 kleinen Dies bestimmt besser als ein großes Die schon alleine weil zwischen den 4 kleinen Dies einfach Platz zum Kühlen liegt.
Aber oben sitzt doch wieder nur ein Kühler, damit wäre es als wenn man einen ganz große Topf nicht auf eine ganz große Herdplatte stellt, sondern auf alle vier Platten eines normalen Herdes. Ob das besser ist, weiß ich nicht.
ampre schrieb:
Die Latenz ist nur abhängig wie die Schnitstelle zwischen den 4 Dies aufgebaut ist und die kann bei 4 kleinen Dies größer sein als bei einem großen Die da dem großen Die die Fläche fehlt um große Schnittstellen einzubringen.
Die Latenz wird größer sein, da kann man von ausgehen, aber wieso sollte dem großen Die Platz für eine große Schnittstelle fehlen? Das große Die bei Intel ist u.a. auch deshalb groß, weil es so viele Schnittstellen bietet.
Krautmaster schrieb:
Intel könnte genauso gut 2x 18 Kerner auf einem Interposer oÄ platzieren. An dem von AMD dafür verwendeten Fabrik scheitert das nicht.
Das wird auch kommen, da muss man kein große Hellseher sein, denn wieso hat Intel wohl sonst
EMIB (Embedded Multi-Die Interconnect Bridge) präsentiert:
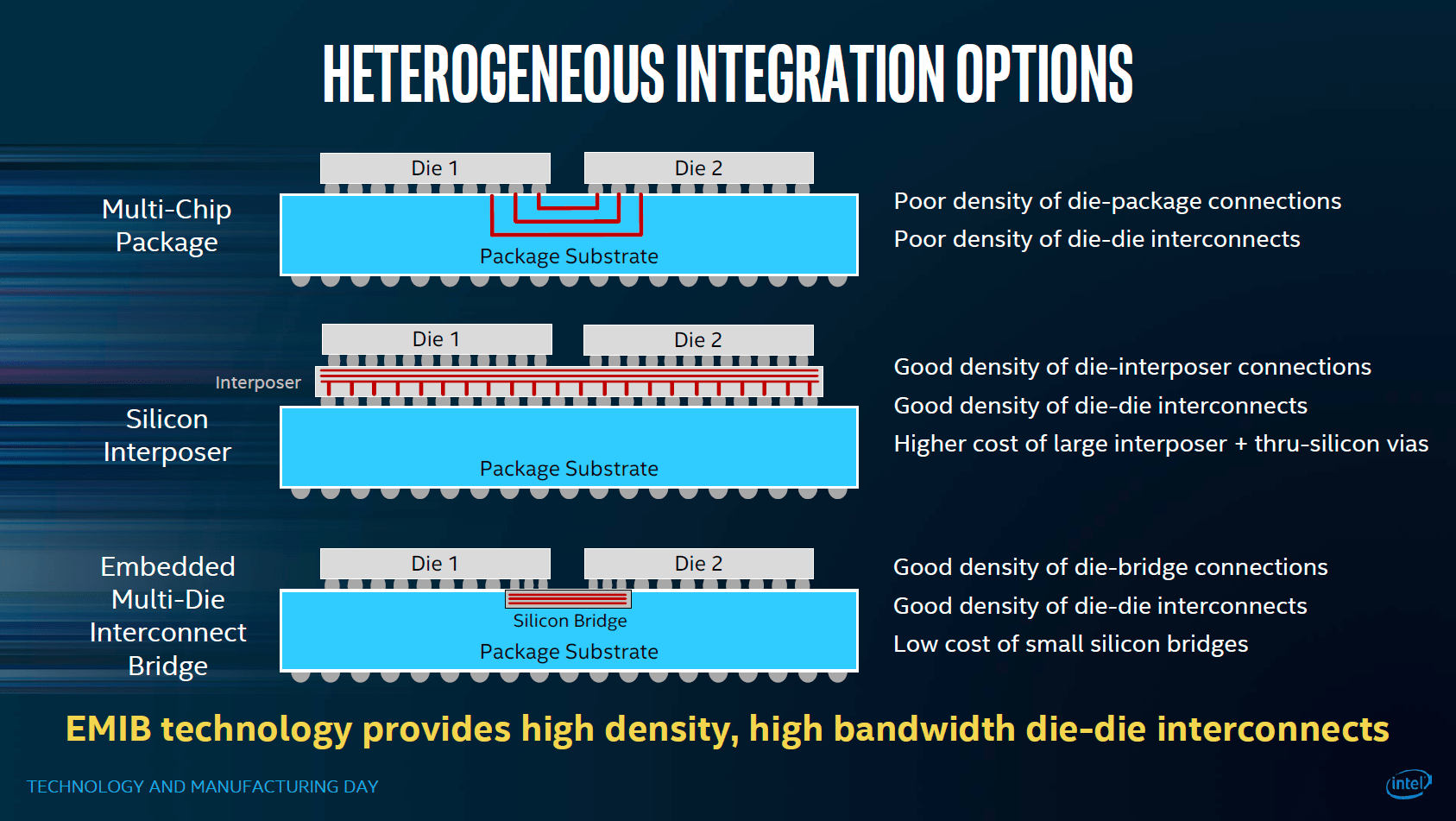
AMDs dürfte keinen Interposer bei EPYC einsetzen, sonst wären die Dies viel dichter zusammengerückt, denn Interposer sind auch Halbleiter bzw. werden wie Halbleiter gefertigt, nur werden dort kleine Logikschaltungen sondern nur Verbindungen aufgebracht. Die Kosten steigen aber genauso mit der Größe und daher werden sie ab einer bestimmten Größe eben sehr teuer und irgendwann unwirtschaftlich. Der Ansatz von Intel diese nur an den Kanten unter einen Teil des Dies zu legen statt alle Dies auf einem Interposer platzieren zu müssen, ist daher sehr kostensenkend und ermöglicht eben weitaus größere MCP als bisher.
Krautmaster schrieb:
Bei Mesh geht es ja in erster Line darum mehr als 4 oder auch 8 Kerne in einem Die zu verbinden.
Ja, aber ich könnte mir vorstellen das dies gar nicht alles ist. Denn mann sollte sich von diesem Bild nicht täuschen lassen:
Viel interessanter wird es doch, wenn man damit auch die großen CPUs aus Modulen kleiner Dies zusammenbauen kann, ohne aber große Nachteile bei der Latenz zu bekommen. Die Mesh könnte man einfach verlängern und über diesen EMIB (also teilweise Interposer dann verbinden, so dass ein viel größere Gitter entsteht. Bei Ringbussen müssten man entweder wie beim Doppelring auf jedem Die eigene Ringe bauen und diese Verbindungsstellen über den EMIB zum anderen Die anbinden, was dort zu Engpässen und schon auf einem Die zu 5 Takten zusätzlicher Latenz führt, beim Mesh hat man dagegen viel mehr Verbindungsstellen und damit mehr Bandbreite.
Auch Intel wird sich nicht ewig die Entwicklung von Dies mit vielen Hundert mm² Fläche für den eher kleinen Kreis der Serverkunden leisten können, die dann auch noch nach ein bis zwei Jahren abgelöst werden müssen. Schon gar nicht nachdem AMD nun mit seiner aggressiven Preispolitik auf die Margen drückt. Aber Intel muss aufpassen seine Stärke nicht zu verlieren und die liegt eben in der geringen Latenz der Kommunikation zwischen den Kernen.
Nachdem Intel EMIB und Mesh verwendet, liegt es also auf der Hand wie Intel zukünftig seine großen CPUs wohl realisieren dürfte, denn je mehr die Fertigungsstrukturen der Chips schrumpfen, umso stärker explodieren die Kosten der Chipentwicklung und die gehen für so ein großes Die wie den 28 Kern Skylake-SP mit seinen 698mm² wahrscheinlich schon in die Milliarden.
Krautmaster schrieb:
Ergo wird AMD auch schauen müssen wie sie gut mehr als 8 Kerne auf einer Die realisieren.
Sie könnten einfach 4 CCX auf einem Die unterbringen, die Architektur ist ja genau darauf ausgelegt so skaliert zu werden.
Krautmaster schrieb:
Damit dürfte sich Intel die letzten 5 Jahre auseinander gesetzt haben.
Das Problem der explodieren Kosten der Chipentwicklung bei schrumpfenden Fertigungsprozess haben alle Chiphersteller und auch NVidia wird eine Lösung brauchen um irgendwann keine 600mm² Dies mehr zu brauchen und trotzdem große, leistungsstarke GPUs zu produzieren. Auch dort wird AMD wohl auf MCP setzen und große GPUs aus Modulen mit Dies kleinere GPUs zusammensetzen, den Einsatz der Fabric auch für GPUs hat AMD ja schon angekündigt. AMD ist da auch Pionier, weil deren Marktanteil einfach kleiner ist, die anderen können die Kosten der Entwicklung so großer Dies bisher noch über ihre weitaus größeren Stückzahlen wieder einspielen. Dies wäre aber so oder so irgendwann zuende, da die Stückzahlen ja kaum steigen und man die Preise eben nicht ewig weiter anheben kann.
AMD mit seiner Preispolitik beschleunigt diese Entwicklung nur noch zusätzlich, weil damit die Preise und Absatzprognosen zusätzlich unter Druck geraten. AMD selbst kann sich bei seinem derzeit minimalen Marktanteil bei Server-CPUs das Risiko gar nicht erlauben ein 32 Kern Die zu entwickeln und hätte vielleicht gar nicht das Geld und die Menpower dafür, die hatten also keine andere Wahl als solche CPUs als MCM zu gestalten.
Krautmaster schrieb:
CPU zu CPU bzw Die zu Die Kommunikation dürfte dem gegenüber relativ einfach zu realisieren sein.
Es gibt meistens einfache Wege, die haben aber Nachteile und bessere Wege, die sind dann aber aufwendiger. Das ganze Thema der Kommunikation zwischen viele Kernen ist ja überhaupt erst mit RYZEN in den Fokus der Medien gerückt, war aber schon immer ein zunehmendes Problem je mehr die Anzahl der Kerne gestiegen ist.
Krautmaster schrieb:
Wie hoch die Yield ist kann man wohl noch an der Marge festmachen. Wie groß ist ein 30-50€ Pentium / Celeron? Wäre die Yield so schlecht müsste man wohl generell höhere Preise fahren.
Es ist ja auch immer eine Mischkalkulation bei AMD basieren alle RYZEN auf dem gleichen Die, die kosten im Prinzip alles gleich viel in der Fertigung. Aber wenn auf einem CCX ein Kern defekt ist, könnte er nicht mehr als 8 Kerner verkauft werden, man kann ihn aber als 6 Kerner verwerten, welche Kosten setzt man nun für so ein Die an?
Das steht im Artikel ja auch etwas unglücklich:
während native Dies mit einer Größe über 600 mm² deutlich schwieriger zu fertigen sind und entsprechend schnell die Ausbeute an voll funktionsfähigen Chips gedrückt wird.
Die Chips müssen ja nicht alle voll funktionsfähig sein um verwendet werden zu können, wäre dem so, würden die Kosten aller Halbleiter massiv höher liegen als sie es tun. Die Designs der Chip sehen ja gerade eine Verwertung von Dies auch dann vor, wenn bestimmte Fehler aufgetreten sind und dies ist ja schon sehr lange so.
Krautmaster schrieb:
Viel eher wird Intel das Mesh Design auf bis >100Kerne pro Die ausgelegt haben, denn davon sind wir weniger weit weg als man glauben mag.
Die Xeon Phi dürften in 10mm² in die Größenordnung von so etwa 100 Kernen kommen.
Krautmaster schrieb:
ja natürlich. Deswegen die Gretchenfrage - ab wie viel Kernen funktioniert der AMD Infinity Fabric nicht mehr?
Darauf gibt es keine pauschale Antwort, denn es hängt halt vom Programm ab, eben davon wie viel Kommunikation zwischen den Kernen auf unterschiedlichen CCX nötig ist. Als AMD sich für die Infinity Fabric entschieden hat, hat man sich darüber aber mit Sicherheit Gedanken gemacht, Simulationen durchgerechnet und ist zu dem Ergebnis gekommen, dass diese noch für einige Generationen reichen dürfte, sonst hätte man kaum diese Technik eingeführt.
Krautmaster schrieb:
Wir wissen doch bisher nur dass bei AMD innerhalb eines CCX die Kommunikation latenzärmer ist als im Ringbus bei Intel. Über 2 CCX hinweg aber schon deutlich "langsamer".
Eben,
innerhalb eines CCX liegt die Latenz auf dem Niveau der Intels Mainstream 4 Kerner. Spannend wird zu sehen, wie die Latenz bei Mesh aussehen wird. Die Weg sind ja hier deutlich kürzer als bei den Ringbussen, wo z.B. jeder Kern nur zwei Nachbarn direkt erreichen konnte, beim Mesh haben die inneren Kerne jeweils 4 Nachbarn. Beim alten 28 Kern Die mit Doppelring konnte die Latenz zwischen den entferntesten Kernen meine ich 14 Takte betragen, beim neuen der eine 6x5 Matrix haben dürfte, wäre es nur noch 9. Die durchschnittliche Latenz dürfte also deutlich gefallen sein.
Krautmaster schrieb:
Bei 4 CCX auf einem Die, 8 Kerne pro CCX oder oder 8 Die zusammen Auf einem Substrat dürfte das kaum schneller werden.
Meinst Du mit 8 Die zusammen Auf einem Substrat Interposer? Bei acht Kernen auf einem CCX hätte man dann aber das Problem innerhalb eines CCX die Kerne zu verwenden, da wird es sehr aufwendig wenn man jeden mit jedem direkt verbinden muss und müssen dann jeder auch noch eine Anbindung an das Gat zur Fabric haben, da gibt es ja pro CCX nur eines, was dann auch schnell zum Nadelöhr würde. Da glaube ich eher weniger dran, 4 CCX pro Die klingt für mich wahrscheinlicher.
Krautmaster schrieb:
Für den kleinen Player am Markt ist der Ansatz von AMD sicher der smartere da man bei der Fremdfertigung mit einer einzigen Maske auskommt. Man nimmt von GF schlicht extrem viele Die ab, die alle tupfen gleich sind.
Genau und eine anderen Lösung um so bald auch wieder in den Markt für Server CPUs zurückkehren zu können, dürfte es für AMD gar nicht gegeben haben, denn wie hätte man viele Hundert Millionen wenn nicht Milliarden in ein Projekt mit ungewissen Erfolgschancen investieren können? Aber wie gesagt ist die Tendenz dazu große Chips als MCM sowieso vorhanden, da die explodieren Kosten der Entwicklung für Chips mit immer kleineren Fertigungsprozessen alle Hersteller dazu zwingen werden diesen Schritt zu gehen, denn die erzielbaren Stückzahlen und Preise werden irgendwann diese Kosten nicht wieder einspielen können. Das große Problem ist dabei nur, wie man diese Dies so verbindet, dass man die Kosten nicht doch hintenrum wieder massiv ansteigen lässt, was bei Interposern eben der Fall ist und dennoch möglichst geringe Nachteile bzgl. Latenz und Bandbreite der Anbindung hinbekommt.
Krautmaster schrieb:
Dass jemand der selbst fertigt ggf da eine andere Strategie fährt sollte klar sein. zB scheint Intel eine neue Maske relativ gesehen wenig zu kosten. Die haut man ja seit Jahren am laufenden Band raus.
Da Intel selbst die Fertigungstechnologie entwickelt und selbst fertigt, könnten sie in der Hinsicht einen Kostenvorteil gegenüber allen haben die auf eine Fremdfertigung angewiesen sind. Aber NVidia fertigt auch noch so große Dies für seine große GPUs, die Kosten der Entwicklung dürften also noch über die Stückzahlen und Preise wieder einzuspielen sein. Die Frage ist eben, wie lange noch, wenn die Kosten bei jedem weiteren Shrink massiv weiter steigen und die Preise durch die Konkurrenz von AMD unter Druck geraten. Es sollte mich nicht wundern, wenn AMD auch seine kommenden großen GPUs als MCM ausgeführt hat.
stoneeh schrieb:
Exakt. Das Design ist bei Intels einfach komplexer. Deswegen mehr Transistoren und im Endeffekt auch mehr Features und Leistung.
Ja, aber eben auch mehr Kosten und damit hängt es eben sehr von der geplanten Anwendung ab, welche der beiden CPUs letztlich besser geeignet ist. EPYC dürfte eine gewaltige Rohleistung haben, dies aber nur umgesetzt bekommen wenn die Ausgabe eben nur wenig Kommunikation zwischen den SW Threads verlangt, genau wie es bei den Demos ist die AMD zeigt.
stoneeh schrieb:
Ein sinnvoller Vergleich wäre gewesen wieviel Platz pro Transistor.
Da dürfte Intel wohl noch im Vorteil sein und erwartet bei 10mm² auch noch gegenüber den 7nm genannten Prozessen andere Fabs wettbewerbsfähig zu sein.
Aldaric87 schrieb:
Da liegst du meines Wissens nach falsch. AMD hat deutlich mehr Transistoren pro mm².
Die Methoden zur Zählung der Transistoren weichen sehr voneinander ab, da wäre ich vorsichtig was die offiziell genanten Zahlen der Hersteller angeht, denn da ist wie bei den Namen der Fertigungsprozesse viel Werbung dabei. Laut den Aussagen unabhängiger Experten sind die Strukturen auf Intel 14nm CPUs kleiner als bei den 14nm Prozessen der anderen und dann ist das Die auch noch größer, wenn Intel nicht ganz viel Platz für Verbindungen verwendet die dann nicht als Transistoren gezählt werden und AMD dafür im Vergleich nur ganz wenig Platz verwendet oder die Flächen einfach durch die Größe von Transistoren teilt und diese dann mitzählt, ist es kaum vorstellbar das AMD wirklich mehr Transistoren auf kleinere Fläche untergebracht hat, obwohl jeder Transistor mehr Platz auf dem Die benötigt.