@xexex
Inwiefern Unsinn? Wenn Du es so gelesen hast, dass die Patches automatisch eingespielt werden, mea culpa. Ich arbeite in einem Unternehmen in dem Industriespionage ein sehr, sehr großes Thema ist. Da wird serverseitig alles gepatcht, unabhängig ob das Exploit nur theoretisch besteht.
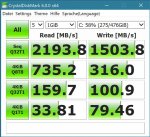
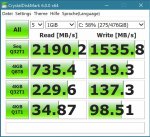
Ebenso haben wir bei uns im WAN ca. ~7000 User angeschlossen, keine 500. Das sind schlicht andere Größenordnungen und leider ja - die Server fahren momentan eine höhere Auslastung als sie eigentlich sollten - Nachschub ist bestellt. Wenn nun aber teils 10 bis 20% Leistungsverlust in Peaks eintreten, tritt genau das auf, was Piktogramm oben beschreibt. Weiterhin haben wir die Teilbereiche Wareneinkauf, Materialdisposition, Lagerhaltung, Buchhaltung, sowie Logistik.
Jeder dieser Fachbereiche verwendet eigene Hauptsoftware.
Das Problem an den verschiedenen Software's ist, das nahezu jede von denen mit unterschiedlichen Timeout/Latenzwerten arbeitet. Während Programm A also noch stabil läuft, kann es durchaus vorkommen, dass Programm B einen Timeout an Citrix / VM meldet und sich selbst abschießt.
Stein des Anstoßes der Diskussion hier waren, warum CB Werte veröffentlicht, die für den Privatanwender fast keine Relevanz haben. In gewissen Firmenumgebungen aber durchaus. Da CB selbst auch ebenfalls häufig aus dem professionellem Umfeld berichtet, ist dieser Wert völligst daseinsberechtigt.
Die irrelevanz dieser Werte, kann man daher für sich selbst beurteilen. Aber doch bitte nicht führ hochkomplexe IT-Landschaften die man nicht mal kennt.
Wenn Du mir sagst was noch weiterhin Unsinn ist, dann gehe ich darauf gerne ein, bzw. erkläre meine Sichtweise. Du weißt aus anderen Threads, dass ich mich durchaus sachlich und normal unterhalten kann. Wo mir die Hutschnur platzt ist, wenn Leute ohne Grund anfangen auf einem persönlichen Level zu argumentieren. Wenn mein letzter Beitrag vllt. etwas zu provizierend war, entschuldige ich mich an der Stelle.
Wenn aber jemand dann noch abschließend sagt, an Supporthotlines sitzen sowieso nur "Hiwis", dann disqualifiziert man sich meines Erachtens nach völligst. Da geht mir dann einfach die persönliche Einstellung desjenigen ganz gewaltig gegen den Strich. Dafür werde ich mich sicher nicht entschuldigen.
Herabwertung der Menschen, die für kleines Geld den beschissensten Job machen. Großes Kino.
Piktogramm schrieb:
@Begu
Sehr viele Server werden gegen Spitzenlasten ausgelegt (1-10% der Betriebszeit) und selbst da strebt man oftmals eher so maximal 50% Systemauslastung an. Im Mittel haben die Kisten also sehr viel "Leistung über". Typischerweise versucht man auch Auslastungszustände über 80% zu vermeiden, da daraus hohe und vor allem inkonsistente Latenzen ergeben. Schlicht weil sich zunehmend Ressourcenzugriffe gegenseitig blockieren.
Andersherum: Server die im Mittel bei 10% Systemauslastung oder weniger herumdümpeln sind recht häufig. Was der Ansatz von diesem Amazon AWS und Microsoft Azure Cloudzeug ist.
Wir dümpeln bei Spitzenlast zwischen 14 und 16 Uhr momentan schon irgendwo zwischen 50% und 70%, ganz einfach weil die Netzwerke zum Teil überlastet sind, respektive der ISP die Bandbreite nicht schnell genug erhöhen kann. Da stauen sich dann leider im Flaschenhals Lasten auf. Und deswegen ist jeder weitere Bereich, der nun in der Zwischenzeit noch leistungstechnisch einbrechen könnte, mehr als nur relevant.
Begu schrieb:
Wieso beziehst Du dich nur auf IOPS? Und was sollen deine allgemein gültigen Aussagen? Das hilft dem Einzelfall auch nicht weiter. Und wie du schön selbst festgestellt hast, "Auf der anderen Seite sind IT Umgebungen zu komplex um sie hier mal eben von einem CB Redakteur auch nur ansatzweise abzudecken"
Um es kurz zu machen, unser Storage Server für Messdaten kotzt regelmäßig im strahl, trotz lwl und NVMe. Die updates nicht zu installieren ist...nein. Die Updates verbessern die Situation aber auch eher nicht.
Full ack.