Chismon schrieb:
RDNA3 lohnt sich auch bei den iGPUs/APUs nicht wirklich, wie es scheint, aber das war aufgrund des eher mageren Leistungszuwacheses bei den Desktop(-Chip)-Karten von RDNA2 zu RDNA3 wohl auch zu erwarten.
Da sich zwischen 680M und der 780M quasi nur der interne ALU-Aufbau sowie der Takt geändert hat. Und ohne die Taktraten in den Spielen hier zu haben, kann man hier nicht so viel sagen, woran es denn hängt.
Auch die Aufteilung der TDP und Bandbreite zwischen CPU und GPU kann hier eine Rolle spielen. Das Steamdeck hat zwar auch nur 128 Bit - also klassisches Dual-Channel - aber aufgeteilt in 4 * 32, was hier auch von Vorteil sein kann.
mkl1 schrieb:
Arrow Lake kommt viel später, das ist noch kein Thema. Aber Meteor Lake-P mitsamt Xe LPG GT2 sollte mit 680M/780M konkurrieren können.
Kommt am Ende auf die genaue Zusammensetzung an und ob Intel den L4 für alle APUs aktiviert oder nur bei bestimmten und wie viel es am Ende auch ist.
Philste schrieb:
WENN Intel es schafft die GPU zu füttern, sei es durch L4 oder sonst was.
Das ist der einzige Knackpunkt und aktuell auch der Punkt, der die 780M hier weit unter den Erwartungen ins Ziel laufen lässt. Der "L4"-Cache wird hier helfen können, das hat man auch bereits bei den ehemaligen Iris Pro gesehen in der Haswell und Broadwell-Generation.
Philste schrieb:
Meteor Lake bringt 33% mehr EUs und Gerüchtehalber 50% mehr Takt.
Und am Ende muss die Bandbreite passen, dass genug Daten ankommen. Sowohl Takt als auch die EU sind hier aktuell eher nebensächlich. Das Interessante ist der "L4".
Philste schrieb:
Plus die Architekturverbesserungen durch den Switch auf Alchemist sollte man da bei gut doppelter Leistung rauskommen und damit auch ~25% über Phoenix.
Die reinen Architekturverbesserungen können hier am Ende genauso wie bei RDNA3 verpuffen, weil die Änderungen für sich notwendig sind, aber eben nicht direkt die Leistung betreffen, sondern an andere Stelle ihre Wirkung haben.
Man sollte an dieser Stelle auch nicht "unterschlagen", dass die 780M und die APU theoretisch mit LPDDR5 7500 betrieben werden können. Bisher sieht man die 780M mit vergleichsweise "schwachem" RAM.
guggi4 schrieb:
Das ist aber auch sehr optimistisch gerechnet, dass selbst iGPUs nicht perfekt skalieren hat man ja bereits öfter gesehen (Vega 8 -> 11, 660M -> 680M, auch bei den Intels)
Die EU/CU sind in dem Fall aber eher weniger das Skalierungsproblem. Genauso der Takt. Probleme kommen hier durch die Speicherbandbreite/Datenversorgung sowie ggf. die TDP und damit die Verteilung auf CPU und GPU.
ETI1120 schrieb:
Und welchen Unterschied macht es für den Compiler ob er nun zusätzliche CUs füttern muss oder Dual Issue füttern muss?
Es macht für den Compiler keinen Unterschied, das habe ich an der Stelle aber auch nicht geschrieben.
Die zusätzlichen CUs werden durch den Treiber und dem dortigen Scheduler gefüttert, die neuen Vec-ALUs wiederum werden vom Compiler gefüttert, in dem wer entsprechend entweder genug Rechenoperationen für die Dual-Issues Ausführung findet und parallelisieren kann, oder genug Daten für einen Wave64 zusammen kommen.
Bei mehr CUs müssen mehr Threads zusammen kommen, bei den umgebauten ALUs mehr Daten pro ALU. Und dass "letzteres" nicht wirklich optimal funktioniert, erkennt man an Ampere nun Ada und eben auch RDNA3. Ampere, Ada und auch RDNA3 schaffen es erst bei hohen Auflösungen pro Task genug Daten zusammen bekommen. AMD kann hier noch Dual-Issues anführen, aber dafür muss halt genug Anweisungen gefunden werden, die parallel ausgeführt werden können.
Und bei so kleinen GPUs wie hier - also die iGPUs - muss man sich um die Anzahl der Tasks wenig sorgen machen, für die Auslastung der mehr an Shader pro CU aber sehr wohl.
ETI1120 schrieb:
Navi 31 hat gegenüber Navi 21 was die CU anbelangt gut skaliert.
Genau, Navi31 hat gut mit der Anzahl der CU skaliert, weil bei modernen Engines genug Threads zusammen kommen. Navi31 benötigt 192 Threads, damit die GPU gut ausgelastet wird, das ist heute möglich.
Mit der Anzahl der Shader hat aber damals weder Ampere noch jetzt mit Ada wirklich gut skaliert und auch RDNA3 nicht und genau das sieht man auch bei der iGPU.
Die Anzahl der CU wäre hier "einfacher", die neuen Vec in RDNA3 sind sehr stark auf den Compiler angewiesen und auch von der Auflösung.
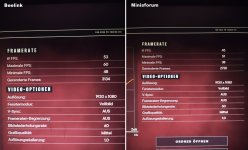
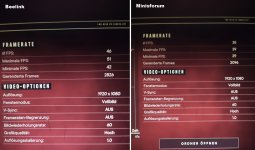
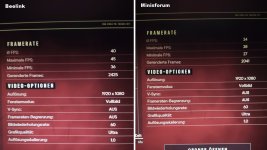
Aber die Probleme bei der 780M scheint eher an andere Stelle zu liegen. Ich bin mal auf die Taktrateng gespannt.