Hallo,
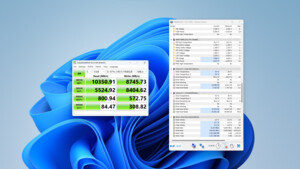
ich habe hier eine externe 2,5"-Platte (Seagate), die nicht korrigierbare Sektoren meldete. Nach einem Vollschreiben mit h2testw sind sie aber weg. Ist die Festplatte also wieder ok oder wie? Meldet Seagate schwebende Sektoren (C5) einfach gleichzeitig auch als nicht korrigierbar (C6)?
BB bleibt bei 0x80, ist bei CDI aber blau.


Laut Log sind die Fehler außerdem bei LBA 0x0fffffff aufgetreten, was irgendwie seltsam ist:
Wird LBA nicht richtig gemeldet, oder ist es gar kein Hardware- sondern einfach ein Software-Fehler?
ich habe hier eine externe 2,5"-Platte (Seagate), die nicht korrigierbare Sektoren meldete. Nach einem Vollschreiben mit h2testw sind sie aber weg. Ist die Festplatte also wieder ok oder wie? Meldet Seagate schwebende Sektoren (C5) einfach gleichzeitig auch als nicht korrigierbar (C6)?
BB bleibt bei 0x80, ist bei CDI aber blau.
Laut Log sind die Fehler außerdem bei LBA 0x0fffffff aufgetreten, was irgendwie seltsam ist:
Code:
SMART Error Log Version: 1
ATA Error Count: 128 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 128 occurred at disk power-on lifetime: 91 hours (3 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 40 ff ff ff 4f 00 00:04:51.523 READ FPDMA QUEUED
ef 03 46 38 36 5a 00 00 00:04:51.510 SET FEATURES [Set transfer mode]
ef 03 0c 38 36 5a 00 00 00:04:51.499 SET FEATURES [Set transfer mode]
ec 08 40 38 36 5a 00 00 00:04:51.497 IDENTIFY DEVICE
00 00 00 00 00 00 00 ff 00:04:47.553 NOP [Abort queued commands]
Error 127 occurred at disk power-on lifetime: 91 hours (3 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 40 ff ff ff 4f 00 00:03:45.503 READ FPDMA QUEUED
60 00 40 ff ff ff 4f 00 00:03:45.501 READ FPDMA QUEUED
e7 08 40 38 36 5a 00 00 00:03:39.614 FLUSH CACHE
61 00 08 28 36 5a 40 00 00:03:34.608 WRITE FPDMA QUEUED
e7 08 40 38 36 5a 00 00 00:03:33.946 FLUSH CACHE
Error 126 occurred at disk power-on lifetime: 79 hours (3 days + 7 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 02:26:32.682 READ FPDMA QUEUED
25 03 08 ff ff ff 4f 00 02:26:29.231 READ DMA EXT
ef 03 46 08 44 ef 00 00 02:26:29.217 SET FEATURES [Set transfer mode]
ef 03 0c 08 44 ef 00 00 02:26:29.207 SET FEATURES [Set transfer mode]
ec 08 40 08 44 ef 00 00 02:26:29.205 IDENTIFY DEVICE
Error 125 occurred at disk power-on lifetime: 79 hours (3 days + 7 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 03 08 ff ff ff 4f 00 02:26:29.231 READ DMA EXT
ef 03 46 08 44 ef 00 00 02:26:29.217 SET FEATURES [Set transfer mode]
ef 03 0c 08 44 ef 00 00 02:26:29.207 SET FEATURES [Set transfer mode]
ec 08 40 08 44 ef 00 00 02:26:29.205 IDENTIFY DEVICE
00 00 00 00 00 00 00 ff 02:26:25.248 NOP [Abort queued commands]
Error 124 occurred at disk power-on lifetime: 79 hours (3 days + 7 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 02:21:40.698 READ FPDMA QUEUED
25 03 08 ff ff ff 4f 00 02:21:37.196 READ DMA EXT
ef 03 46 e8 43 ef 00 00 02:21:37.183 SET FEATURES [Set transfer mode]
ef 03 0c e8 43 ef 00 00 02:21:37.172 SET FEATURES [Set transfer mode]
ec 08 40 e8 43 ef 00 00 02:21:37.170 IDENTIFY DEVICE
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 116 -Wird LBA nicht richtig gemeldet, oder ist es gar kein Hardware- sondern einfach ein Software-Fehler?