Kowa schrieb:
Kopier mal ein Backup, mit 20-30GB auf die Evo.
https://www.computerbase.de/artikel...ramm-dauertransferrate-schreiben-h2benchw-316
Die Budget-SSDs gehen da sehr schnell in die Knie.
Die 850 Evo ist aber keine Budget SSD und wenn man viele GB am Stück schnell darauf schreiben können möchte, sollte man die 850 Evo mit 500GB und mehr nehmen, die können auch bei vollem Pseudo-SLC Schreibcache noch mit 500MB/s schreiben, was meines Wissens sonst keine SATA SSD mit TLC NANDs schafft. Die BX200 ist dagegen absolut das Negativbeispiel und die anderen liegen irgendwo dazwischen.
Kowa schrieb:
In großen Firmen dauern die Beschaffungsprozesse oft Jahre um am Ende das billigste HDD-Storage zum höchsten Preis zu kaufen.
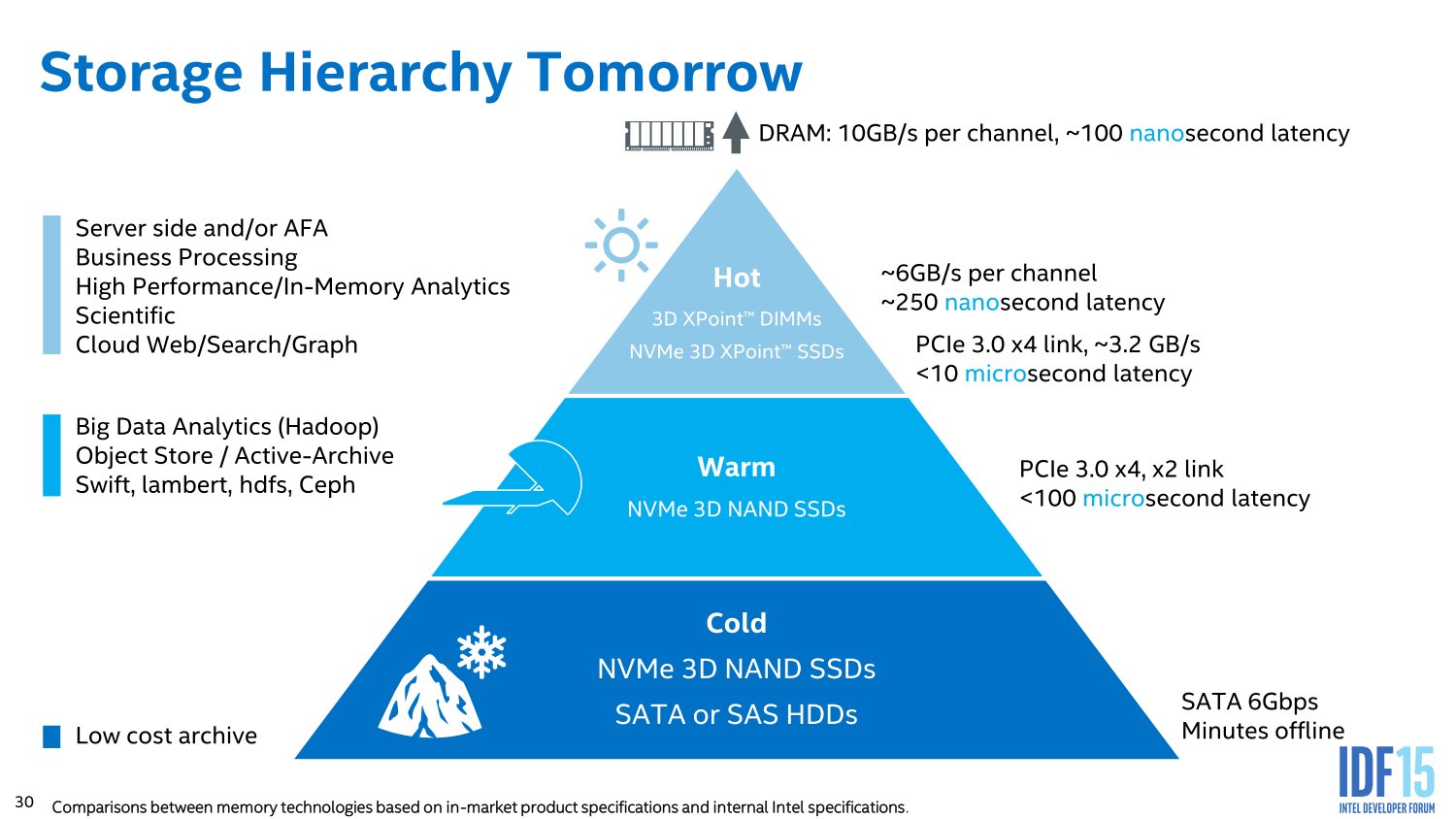
Das hängt sehr von der Firma und der Nutzung des Systems ab, bei geschäftskritischen Anwendungen ist man meist sehr darauf bedacht auf bewährte Technologie zu setzen, bei Forschung und Entwicklung gilt das weniger und man nimmt dort auch gerne mal neue Technologie wenn sie Vorteile oder gar die Lösung von Problemen verspricht, die anderes überhaupt nicht lösbar wären. 3D X-Point zielt eher auf letztere Anwendungen wie eben Bigdata und da sind bestimmte Anwendungen nur machbar, wenn man genug Daten schnell genug analysiert bekommt.
Kowa schrieb:
Ich sehe den Einsatz eher bei kleineren Firmen, oder bei Studenten, engagierten IT-Spezis, die im privaten eine Hochleistungsdatenbank aufbauen um für ein Projekt Vorarbeiten zu leisten, ohne Kohle für die fetten Server auf den Tisch legen zu können.
Würde Micron das genauso sehen, würden sie auch ein Modell für Privatkunden bringen.
Kowa schrieb:
Beim anschließenden Backup War es dann meist auch die SSD, die 100% busy ist und nur 250-150MB liefert. Für sowas Nerviges muß ich bis zu 7 Minuten einplanen, in denen ich auf Balken starre.
Keine Ahnung was Du da konkret machst, aber wenn viele kleine Dateien gelesen werden müssen, dann schaffen auch SSDs bei QD1 eben keine 500MB/s, bei 4k sind es eben meist so zwischen 20 und 50MB/s und dabei wird die SSDs trotzdem 100%ig ausgelastet, denn das ist aus Windows Sicht der Fall, wenn ständig mindestens ein Zugriff darauf erfolgt, auch wenn der Controller der SSD sich damit sicher noch nicht ausgelastet fühlt.
Piktogramm schrieb:
XPoint als persistenter Speicher ist für mich Festspeicher
Dann hast Du wohl noch nicht ganz verstanden, was Intel mit dem 3D XPoint machen möchte, gerade wenn es in einem RAM Slot gesteckt wird. Da kommt es dann nämlich nicht so darauf an das die Daten persistent gehalten werden, sondern da nutzt man die Tatsache das diese 3D XPoint im Vergleich zu DRAM eine größere Datendichte hat und damit mehr Kapazität bei gleichzeitig geringeren kosten ermöglicht. Man könnte dann wieder eine RAM Disk darauf anlegen, aber das dürfte wegen das Ziel sein als eben einen Rechner mit TB-weise RAM zu schaffen, auch wenn davon eben nur ein paar GB wirklich DRAM sind und vor allem als Cache für das 3D XPoint dient. Der Vorteil gegenüber der Nutzung als Disk ist eben, dass die Datenstukturen dort dann direkt so wie im RAM vorliegen und die CPU sofort direkt darauf zugreifen kann, was eben nochmals schneller geht als wenn diese von einem Speichermedium geladen und ins RAM geschafft werden müssen, selbst wenn das Speichermedium eine RAM Disk ist.
Piktogramm schrieb:
Diese neuen persistenten Speicher die DRAM ersetzen sollen müssen nicht geringere Latenzen als SSD via PCIe haben, sondern sie müssen zwingend Latenzen auf dem Level klassischen DRAMs haben bzw. am besten noch eine Ecke schneller arbeiten.
3D XPoint hat schlechtere Latenzen als DRAM, aber wenn es als RAM genutzt wird, dann sind diese in jedem Fall besser als wenn die Daten erst über PCIe übertragen werden müssen. Die Latenzen müssen eben nicht schneller als die von DRAM sein, dafür ermöglicht es eben einen viel größeren RAM Ausbau und damit vermeidet man viele Daten auf den Platten zu laden, seinen dies nur HDDs, NAND SSDs oder 3D XPoint SSDs und damit erzielt man für Anwendungen die so viel RAM sinnvoll nutzen können, dann eben trotz der schlechteren Latenzen einen Vorteil.
Piktogramm schrieb:
Anonsten taugt der kram zumindest für Datenbankanbindungen nicht.
Es geht nicht um Anbindung, sondern um Nuzen und gerade bei Datenbanken wird der Vorteil enorm sein, weil man dann InMemory Datenbanken mit einer Größe realisieren kann, an die heute einfach noch nicht zu denken ist. Beschäftige Dich noch mal genauer mit dem 3D XPoint und dem was Intel bisher dazu veröffentlich hat, dann wirst Du es hoffentlich auch besser verstehen.
Piktogramm schrieb:
Auf realen Datenbanken kommt es schon mal vor, dass an einer Abfrage auf die normalisierte Datenbankstruktur eine zweistellige Anzahl an Threads losmarschiert. Parallelität ist daher nicht nur durch mehr Nutzer erreichbar.
Das hängt von der jeweiligen DB ab, von Oracle kenne ich es nur, dass dort pro Connection ein Thread läuft.
Piktogramm schrieb:
Wobei da gern mal alles limitiert. CPU zu lahm, Dram zu lahm, Festspeicher zu lahm und Netzwerk sowieso zu lahm.
Wenn alles limitiert wäre es doch optimal, denn dann hätte man ein komplett ausgewogenes System in dem es keinen echten Flaschenhals gibt und damit die anderen Komponenten im Grunde überdimensioniert sind, also den Idealzustand der optimalen Resourcennutzung aller Komponenten. Nur erreicht man sowas in der Praxis eigentlich nie.
Piktogramm schrieb:
Das wäre abartig komplex.
Eben, deshalb ist die CPU eben immer noch die Central Processing Unit, weil alles andere kaum zu realisieren ist und einen unheimlichen Abstimmungsaufwand erfordern würde. Das wäre nicht nur extrem komplex zu implementieren, es würde auch einen gewaltigen Overhead bei der Kommunikation zwischen den Komponenten erfordern, denn da müsste jeder wissen was der andere tun, sobald er auch was machen will, damit sie sich nichts in Gehege kommen. Das ist schon bei der SW Entwicklung eine Herausforderung die viele überfordert und dabei weiß der Entwickler schon beim Programmieren ob die Daten des einen Threads mit denen der anderen etwas zu tun haben und wenn das der Fall ist, muss er synchronisieren, also ein Thread muss waren bis der andere einen bestimmten Punkt erreicht hat und schon nimmt die Parallelität ab.