Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Raid0 defekt
- Ersteller Scatha
- Erstellt am
Gibt es einen kompletten log mit den defekten Sektoradressen, welche nicht kopiert werden konnten?
Den werden wir später brauchen, sonst wird die Rekonstruktion zu einem Glücksspiel....
Soweit ich sehe, wurde das nun mit dd_rescue statt ddrescue (das letzte in der FAQ) gemacht. Sollte egal sein, nur glaube ich, das das letztere durch öftere Versuche ev. erfolgreicher kopiert.
Den werden wir später brauchen, sonst wird die Rekonstruktion zu einem Glücksspiel....
Soweit ich sehe, wurde das nun mit dd_rescue statt ddrescue (das letzte in der FAQ) gemacht. Sollte egal sein, nur glaube ich, das das letztere durch öftere Versuche ev. erfolgreicher kopiert.
Zuletzt bearbeitet:
das logfile hab ich natürlich nicht
die version von knoppix hatte kein ddrescue, daher mit dd_rescue
ich guck mal ob ich irgendwo eine version herkriege mit ddrescue, dann werd ich die platte nochmal klonen + logfile.
Nachtrag: wo wird das logfile gespeichert bei dem befehl ddrescue -B -n /dev/sdx /dev/sdy rescued.log ?
die version von knoppix hatte kein ddrescue, daher mit dd_rescue
ich guck mal ob ich irgendwo eine version herkriege mit ddrescue, dann werd ich die platte nochmal klonen + logfile.
Nachtrag: wo wird das logfile gespeichert bei dem befehl ddrescue -B -n /dev/sdx /dev/sdy rescued.log ?
Zuletzt bearbeitet:
Wie ich jetzt sehe, hat dd_rescue mit einer Blocksize von 1KiB, also je 2 Sektoren gearbeitet. Damit sind auch von den 456 fehlerhaften Sektoren möglicherweise etwas mehr als nötig ausgenullt übertragen worden
Ich hoff ja nur, dass sda die 500er war; hast Du das gecheckt? Nicht, dass Du das auf die intakte 200er kopiert hast, sonst wär jetzt der Ofen aus...
nachdem die Knoppix-CD ein r/o Medium ist, wäre ein formatierter USB-Stick dazu geeignet
wie im http://www.shockfamily.net/cedric/knoppix/ beschrieben, muss der Stick erst in den Properties vom ReadOnly entbunden werden.
Der Pfad dorthin kann auch wie in den Beispielen angegeben ermittelt werden - heißt dann /sdx/yyy/rescued.log oder /ubx/yyy/rescued.log, was dann im ddrescue als Parameter anzugeben ist.
Wenn es dir Spaß macht, kannst Du auch direkt ein Verzeichnis auf Deiner IDE-Systemplatte
/hda/..../Eigene Dateien/.../... angeben
Ich hoff ja nur, dass sda die 500er war; hast Du das gecheckt? Nicht, dass Du das auf die intakte 200er kopiert hast, sonst wär jetzt der Ofen aus...
nachdem die Knoppix-CD ein r/o Medium ist, wäre ein formatierter USB-Stick dazu geeignet
wie im http://www.shockfamily.net/cedric/knoppix/ beschrieben, muss der Stick erst in den Properties vom ReadOnly entbunden werden.
Der Pfad dorthin kann auch wie in den Beispielen angegeben ermittelt werden - heißt dann /sdx/yyy/rescued.log oder /ubx/yyy/rescued.log, was dann im ddrescue als Parameter anzugeben ist.
Wenn es dir Spaß macht, kannst Du auch direkt ein Verzeichnis auf Deiner IDE-Systemplatte
/hda/..../Eigene Dateien/.../... angeben
Zuletzt bearbeitet:
Hatte die andere 200er Platte vorher abgestöpselt 
Hab jetzt eine LiveCD von systemrescuecd, dort ist ddrescue drauf, krieg das da aber irgendwie mit dem USB Stick nicht hin. ich probier mal weiter.
der befehl würde dann lauten wenn der USB Stick /dev/sdd wäre,
ddrescue -B -n /dev/sdb /dev/sda /dev/sdd/rescued.log ?
Nachtrag: /dev/sdd/rescued.log wollte er nicht nehmen. hab jetzt
ddrescue -B -n /dev/sdb /dev/sda rescued.log genommen.
hoffe ich find das nachher wieder.
Hab jetzt eine LiveCD von systemrescuecd, dort ist ddrescue drauf, krieg das da aber irgendwie mit dem USB Stick nicht hin. ich probier mal weiter.
der befehl würde dann lauten wenn der USB Stick /dev/sdd wäre,
ddrescue -B -n /dev/sdb /dev/sda /dev/sdd/rescued.log ?
Nachtrag: /dev/sdd/rescued.log wollte er nicht nehmen. hab jetzt
ddrescue -B -n /dev/sdb /dev/sda rescued.log genommen.
hoffe ich find das nachher wieder.
Zuletzt bearbeitet:
ja; Es ist unbedingt notwendig, dass der logfile geschrieben werden kann (Stick muss R/W Properties haben) sonst ist der ganze Aufwand umsonst.
ddrescue speichert nämlich für die weiteren Aufrufe die noch nicht erfolgreich kopierten Sektoren dort ab; ohne Logfile würde er jedesmal die Platte komplett neu zu kopieren versuchen
In der systemrescuecd-Beschreibung wird auch vorgebetet, wie man eine NTFS-Partition schreibend verwenden kann - deine Systemplatte auf /dev/hda (die erste IDE)
und einen mountpoint auf ein Verzeichnis setzt
z.B. ntfs-3g /dev/hda1 /mnt/windows
damit sprichst du das Rootverzeichnis der ersten Partition der ersten IDE-Platte (im Windows die Systemplatte C:\ ) dann im ddrescue als /mnt/windows/rescued.log an, um die datei auf C:\rescued.log zu erzeugen
Nachtrag zu "hoffe ich find das nachher wieder. "
eher nicht. wenn er draufkommt, dass er dort keine Schreibrechte hat, lässt er es; Folgen siehe oben
ddrescue speichert nämlich für die weiteren Aufrufe die noch nicht erfolgreich kopierten Sektoren dort ab; ohne Logfile würde er jedesmal die Platte komplett neu zu kopieren versuchen
In der systemrescuecd-Beschreibung wird auch vorgebetet, wie man eine NTFS-Partition schreibend verwenden kann - deine Systemplatte auf /dev/hda (die erste IDE)
und einen mountpoint auf ein Verzeichnis setzt
z.B. ntfs-3g /dev/hda1 /mnt/windows
damit sprichst du das Rootverzeichnis der ersten Partition der ersten IDE-Platte (im Windows die Systemplatte C:\ ) dann im ddrescue als /mnt/windows/rescued.log an, um die datei auf C:\rescued.log zu erzeugen
Nachtrag zu "hoffe ich find das nachher wieder. "
eher nicht. wenn er draufkommt, dass er dort keine Schreibrechte hat, lässt er es; Folgen siehe oben
Zuletzt bearbeitet:
Manchmal geschehen ja doch Wunder - wenn man bedenkt, dass ich von Linux keinen blassen Schimmer hab' und es vonah es klappt, danke nochmal für die "DAU" - Erklärung
Zuletzt bearbeitet:
das klonen dauert noch bis 20:30, bis dahin könnte ich mich ja schon ein bisschen über den nächsten Schritt informieren.
4. Sichern des ersten Stripe der intakten und der defekten RAID-Platte
Welche Tools benötigt man dafür?
4. Sichern des ersten Stripe der intakten und der defekten RAID-Platte
Welche Tools benötigt man dafür?
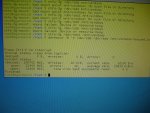
# Rescue Logfile. Created by GNU ddrescue version 1.11
# current_pos current_status
0x53A034E00 +
# pos size status
0x00000000 0x53A034000 +
0x53A034000 0x00000200 -
0x53A034200 0x00000C00 /
0x53A034E00 0x00000200 -
0x53A035000 0x32E920000 +
0x868955000 0x00000200 -
0x868955200 0x00000C00 /
0x868955E00 0x00000200 -
0x868956000 0x06A1E000 +
0x86F374000 0x00000200 -
0x86F374200 0x00000C00 /
0x86F374E00 0x00000200 -
0x86F375000 0x02DEE000 +
0x872163000 0x00000200 -
0x872163200 0x00000C00 /
0x872163E00 0x00000200 -
0x872164000 0x0179D000 +
0x873901000 0x00000200 -
0x873901200 0x00000C00 /
0x873901E00 0x00000200 -
0x873902000 0x00845000 +
0x874147000 0x00000200 -
0x874147200 0x00000C00 /
0x874147E00 0x00000200 -
0x874148000 0x003F0000 +
0x874538000 0x00000200 -
0x874538200 0x00000C00 /
0x874538E00 0x00000200 -
0x874539000 0x045E8000 +
0x878B21000 0x00000200 -
0x878B21200 0x00000C00 /
0x878B21E00 0x00000200 -
0x878B22000 0x902BA000 +
0x908DDC000 0x00000200 -
0x908DDC200 0x00000C00 /
0x908DDCE00 0x00000200 -
0x908DDD000 0x258B058000 +
0x2E93E35000 0x00000200 -
0x2E93E35200 0x00000C00 /
0x2E93E35E00 0x00000200 -
Anhänge
Zuletzt bearbeitet:
(Bild + Log eingefügt)
Fein. Jetzt hast Du den Dreh raus.
Wie man aus dem Logfile (und dem Statusreport von ddrescue erkennt, hat er jetzt die 200GB Platte kopiert und nur an 20 Stellen, die jeweils 4K(je 8 Seltoren) groß sind, wegen der Read Errors am Original noch 20 Lücken am Klon.
In der Hitze des Gefechtes ist Dir entgangen, dass in der Beschreibung auf
http://www.cgsecurity.org/wiki/Beschädigte_Festplatte
noch ein zweiter Durchlauf angeraten wird, um die im ersten Durchlauf rasch durchgeführte Klonung defekte Bereiche zwar markiert, aber nicht weiter behandelt werden.
Deswegen wird ein zweiter Durchlauf für die Feinarbeit danach geraten.
Die Existenz des im ersten Step erzeugten Logfiles ist wichtig, um den zweiten Step nur mehr an den Fehlerstellen durchzuführen.
Ich nehme an, du hast Knoppix wieder beendet, daher musst Du
- Knoppix erneut starten
- Vergewissere Dich z.B. mit gparted dass /dev/sda deine 500GB, sdb die 200GB und sdc die IDE-Systemplatte sind (Manual: hier)
- die IDE-Systemplatte wieder in Schreibzugriff nehmen mit:
ntfs-3g /dev/sdc1 /mnt/windows
- nur wenn das vorige Command fehlerfrei akzeptiert wurde, jetzt den zweite Step von ddrescue durchführen:
ddrescue -B -r 100 /dev/sdb /dev/sda /mnt/windows/rescued.log
Damit werden jetzt nur die im Logfile defekt markierten 20 4K Blöcke 100x zu lesen versucht.
führt das zu keinem Erfolg, dann kannst Du es noch mit
ddrescue -B -c 1 C -d -r 100 /dev/sdb /dev/sda /mnt/windows/rescued.log(korrigiert 11.6.2010)
ddrescue -B -c 1 -C -d -r 100 /dev/sdb /dev/sda /mnt/windows/rescued.log
versuchen. Damit wird versucht, die einzelnen fehlerhaften Sektoren zu lesen. Wenn der erste Versuch nicht allzulange gedauert hat, kannst Du die Wiederholrate auch von 100 auf 1000 oder 10000 setzen.
Damit ist der Schritt des Klonens beendet
Wenn die Anzahl der Fehlstellen durch diese Versuche weniger geworden sind, poste nochmal den endgültigen Inhalt des Logfiles. (Tip: kopieren auf "rescued.log.txt" und als Anhang dem Post hinzufügen) Später werden wir damit die betroffenen Dateien im RAID0 lokalisieren.
Unter deinem Windows-System fährst Du zur Sicherheit mit HDTune einen ErrorScan über unseren erzeugten Klon auf der 500GB Platte - damit wir sichergehen, dass da keine defekten Sektoren drauf sind, bevor wir ihn im RAID verwenden. Wenn alles grün ist, brauchst Du das Bild nicht zu posten.
Die Vorgangsweise (angepasst auf die 500GB Ersatzplatte) sieht so aus:
1. Klonen der defekten 200GB RAID auf die vorderen 200GB der 500GB
2. Sichern des ersten Stripe der intakten und der defekten RAID-Platte
3. Neudefinitionn des RAID0 mit der intakten 200GB und der 500GB
4. Restore des RAID0-MBR
5. Feststellen welche Files von den fehlerhaften Sektoren betroffen sind
danach kann festgestellt werden, ob das System fehlerfrei bootbar sein wird
wenn ja
6a. Löschen der defekten Dateien, ev. Ersetzen durch fehlerfreie Inhalte (von Install-CD, Sicherungen)
7a. Booten von RAID0, ev. chkdsk, System ist wieder verfügbar
8a. Du kannst damit weiterarbeiten, oder das System als non-RAID auf die 1TB übertragen, oder auch die fehlerfreie 200GB durch eine neue 500GB ersetzen und den RAID0 auf 1TB ausweiten - je nach Geschmack
wenn nein
6b. Sichern der wichtigen Dateien vom RAID0 auf die 1TB (im Falle von zerstörtem NTFS-Filesystem per Datenrettungstools, sonst per Filecopy)
7b. je nach Bedarf Neuinstallation des Systems in einer der Varianten von 8a
Punkt 1. ist nach obiger Vorgangsweise erledigt
Weiter mit
2. Sichern des ersten Stripe der intakten und der defekten RAID-Platte
2.1. Lies dir aus diesem Post die Punkte 1-6 unter "Vorgangsweise" durch und installier Dir die beiden Tools. In diesem Thread sind viele erläuterte Aktionen, wir machen es hier ähnlich.
2.2. Aufruf HxD
- im Menü Extras/Open Disk/physical disk x (x um 1 größer als die Datenträgernummer in der Datenträgerverwaltung für die 500GB Platte) selektieren. Das Häkchen bei „open as read only“ keinesfalls entfernen!
- Rechts oben steht im Fenster "Sector ... of maxlba" maxlba sollte für die 500er den Wert 976773167 zeigen.
- Im Menü Edit/Select Block eingeben:
Start: 0
End: 1FFFF
/hex/OK
- den markieren inhalt mit Strg+C in die Zwischenablage;
- im Menü File/New; den Inhalt mit Strg+V übertragen;- Das popup-Fenster mit "change file size?" mit OK quittieren; kein Häkchen bei "do not ask again" setzen! (ist bei Änderungen auf Platten das letzte Netz, bevor Unsinn passiert)
- im Menü File/Save as... einen Zielordner selektieren; als Filename HDD1.0.256.bin eingeben
- HxD beenden, die Datei zippen und als Anhang posten
--- weiter Anweisungen stelle ich mit edit hier dazu (refresh im Browser nicht vergessen)
Wie man aus dem Logfile (und dem Statusreport von ddrescue erkennt, hat er jetzt die 200GB Platte kopiert und nur an 20 Stellen, die jeweils 4K(je 8 Seltoren) groß sind, wegen der Read Errors am Original noch 20 Lücken am Klon.
In der Hitze des Gefechtes ist Dir entgangen, dass in der Beschreibung auf
http://www.cgsecurity.org/wiki/Beschädigte_Festplatte
noch ein zweiter Durchlauf angeraten wird, um die im ersten Durchlauf rasch durchgeführte Klonung defekte Bereiche zwar markiert, aber nicht weiter behandelt werden.
Deswegen wird ein zweiter Durchlauf für die Feinarbeit danach geraten.
Die Existenz des im ersten Step erzeugten Logfiles ist wichtig, um den zweiten Step nur mehr an den Fehlerstellen durchzuführen.
Ich nehme an, du hast Knoppix wieder beendet, daher musst Du
- Knoppix erneut starten
- Vergewissere Dich z.B. mit gparted dass /dev/sda deine 500GB, sdb die 200GB und sdc die IDE-Systemplatte sind (Manual: hier)
- die IDE-Systemplatte wieder in Schreibzugriff nehmen mit:
ntfs-3g /dev/sdc1 /mnt/windows
- nur wenn das vorige Command fehlerfrei akzeptiert wurde, jetzt den zweite Step von ddrescue durchführen:
ddrescue -B -r 100 /dev/sdb /dev/sda /mnt/windows/rescued.log
Damit werden jetzt nur die im Logfile defekt markierten 20 4K Blöcke 100x zu lesen versucht.
führt das zu keinem Erfolg, dann kannst Du es noch mit
ddrescue -B -c 1 -C -d -r 100 /dev/sdb /dev/sda /mnt/windows/rescued.log
versuchen. Damit wird versucht, die einzelnen fehlerhaften Sektoren zu lesen. Wenn der erste Versuch nicht allzulange gedauert hat, kannst Du die Wiederholrate auch von 100 auf 1000 oder 10000 setzen.
Damit ist der Schritt des Klonens beendet
Wenn die Anzahl der Fehlstellen durch diese Versuche weniger geworden sind, poste nochmal den endgültigen Inhalt des Logfiles. (Tip: kopieren auf "rescued.log.txt" und als Anhang dem Post hinzufügen) Später werden wir damit die betroffenen Dateien im RAID0 lokalisieren.
Unter deinem Windows-System fährst Du zur Sicherheit mit HDTune einen ErrorScan über unseren erzeugten Klon auf der 500GB Platte - damit wir sichergehen, dass da keine defekten Sektoren drauf sind, bevor wir ihn im RAID verwenden. Wenn alles grün ist, brauchst Du das Bild nicht zu posten.
Die Vorgangsweise (angepasst auf die 500GB Ersatzplatte) sieht so aus:
1. Klonen der defekten 200GB RAID auf die vorderen 200GB der 500GB
2. Sichern des ersten Stripe der intakten und der defekten RAID-Platte
3. Neudefinitionn des RAID0 mit der intakten 200GB und der 500GB
4. Restore des RAID0-MBR
5. Feststellen welche Files von den fehlerhaften Sektoren betroffen sind
danach kann festgestellt werden, ob das System fehlerfrei bootbar sein wird
wenn ja
6a. Löschen der defekten Dateien, ev. Ersetzen durch fehlerfreie Inhalte (von Install-CD, Sicherungen)
7a. Booten von RAID0, ev. chkdsk, System ist wieder verfügbar
8a. Du kannst damit weiterarbeiten, oder das System als non-RAID auf die 1TB übertragen, oder auch die fehlerfreie 200GB durch eine neue 500GB ersetzen und den RAID0 auf 1TB ausweiten - je nach Geschmack
wenn nein
6b. Sichern der wichtigen Dateien vom RAID0 auf die 1TB (im Falle von zerstörtem NTFS-Filesystem per Datenrettungstools, sonst per Filecopy)
7b. je nach Bedarf Neuinstallation des Systems in einer der Varianten von 8a
Punkt 1. ist nach obiger Vorgangsweise erledigt
Weiter mit
2. Sichern des ersten Stripe der intakten und der defekten RAID-Platte
2.1. Lies dir aus diesem Post die Punkte 1-6 unter "Vorgangsweise" durch und installier Dir die beiden Tools. In diesem Thread sind viele erläuterte Aktionen, wir machen es hier ähnlich.
2.2. Aufruf HxD
- im Menü Extras/Open Disk/physical disk x (x um 1 größer als die Datenträgernummer in der Datenträgerverwaltung für die 500GB Platte) selektieren. Das Häkchen bei „open as read only“ keinesfalls entfernen!
- Rechts oben steht im Fenster "Sector ... of maxlba" maxlba sollte für die 500er den Wert 976773167 zeigen.
- Im Menü Edit/Select Block eingeben:
Start: 0
End: 1FFFF
/hex/OK
- den markieren inhalt mit Strg+C in die Zwischenablage;
- im Menü File/New; den Inhalt mit Strg+V übertragen;- Das popup-Fenster mit "change file size?" mit OK quittieren; kein Häkchen bei "do not ask again" setzen! (ist bei Änderungen auf Platten das letzte Netz, bevor Unsinn passiert)
- im Menü File/Save as... einen Zielordner selektieren; als Filename HDD1.0.256.bin eingeben
- HxD beenden, die Datei zippen und als Anhang posten
--- weiter Anweisungen stelle ich mit edit hier dazu (refresh im Browser nicht vergessen)
Zuletzt bearbeitet:
(fehlerhaftes Command)
Der zählt jetzt bis 100 hoch und hört dann von selbst auf
Wie lange dauert ein Retry-Durchgang?
Wie ich sehe, hat sich die Anzahl der Fehlstellen von 10(20 war Unsinn) inzwischen schon auf 7 verringert.
Umso weniger verbleibende Fehler, desto schneller ein Durchgang.
Die Device versucht hunderte Umdrehungen lang zu lesen, bevor sie einen Fehler meldet; das System probiert es zwecks recovery vielleicht auch noch ein paar mal, dann wird vom Programm zu nächsten Datenloch im Log gegangen. So kommen für einen Durchgang schon einige Minuten zusammen
Wie lange dauert ein Retry-Durchgang?
Wie ich sehe, hat sich die Anzahl der Fehlstellen von 10(20 war Unsinn) inzwischen schon auf 7 verringert.
Umso weniger verbleibende Fehler, desto schneller ein Durchgang.
Die Device versucht hunderte Umdrehungen lang zu lesen, bevor sie einen Fehler meldet; das System probiert es zwecks recovery vielleicht auch noch ein paar mal, dann wird vom Programm zu nächsten Datenloch im Log gegangen. So kommen für einen Durchgang schon einige Minuten zusammen
Zuletzt bearbeitet:
hab jetzt abgebrochen nachdem sich 2 stunden nichts mehr getan hatte.
hdTune läuft jetzt grade durch und ich werd mich danach an HxD und Getdataback versuchen.
bei mir steht 976771055, ich mach trotzdem mal weiter, ist hoffentlich nicht von bedetung
Nachtrag: Die HDD.1.0.256.rar ist jetzt von der 500gb platte, also der klon der defekten. Soll ich das gleiche nochmal mit der anderen raidplatte machen?
hdTune läuft jetzt grade durch und ich werd mich danach an HxD und Getdataback versuchen.
2.2. Aufruf HxD
- im Menü Extras/Open Disk/physical disk x (x um 1 größer als die Datenträgernummer in der Datenträgerverwaltung für die 500GB Platte) selektieren. Das Häkchen bei „open as read only“ keinesfalls entfernen!
- Rechts oben steht im Fenster "Sector ... of maxlba" maxlba sollte für die 500er den Wert 976773167 zeigen.
- Im Menü Edit/Select Block eingeben:
bei mir steht 976771055, ich mach trotzdem mal weiter, ist hoffentlich nicht von bedetung
Nachtrag: Die HDD.1.0.256.rar ist jetzt von der 500gb platte, also der klon der defekten. Soll ich das gleiche nochmal mit der anderen raidplatte machen?
Anhänge
Zuletzt bearbeitet:
Kommt auf die Hierarchie der Daten an. Wenn ein $MFT-Block betroffen ist, kann das umständlich werden, bei normalen Dateien eher nebensächlich...
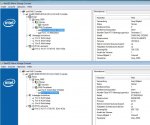
2.3 Jetzt schließt Du die intakte RAID-Platte von Port0 an einen lila jMicron-Port und wiederholst Step 2.2 mit dieser 200GB Platte mit der Seriennummer ...2870 und speicherst das als Datei "HDD0.0.256.bin".
3. Neudefinitionn des RAID0 mit der intakten 200GB und der 500GB
du schließt jetzt die Platte mit der Seriennummer ...2870 jetzt wieder an Port 0
die 500GB Platte kommt an Port1
dann löst du den RAID0 auf und definierst ihn neu mit diesen beiden Platten in dieser Reihenfolge, Stripesize 128K, gesamten Bereich als Typ Stripe = RAID0
2.3 Jetzt schließt Du die intakte RAID-Platte von Port0 an einen lila jMicron-Port und wiederholst Step 2.2 mit dieser 200GB Platte mit der Seriennummer ...2870 und speicherst das als Datei "HDD0.0.256.bin".
3. Neudefinitionn des RAID0 mit der intakten 200GB und der 500GB
du schließt jetzt die Platte mit der Seriennummer ...2870 jetzt wieder an Port 0
die 500GB Platte kommt an Port1
dann löst du den RAID0 auf und definierst ihn neu mit diesen beiden Platten in dieser Reihenfolge, Stripesize 128K, gesamten Bereich als Typ Stripe = RAID0
dann löst du den RAID0 auf und definierst ihn neu mit diesen beiden Platten in dieser Reihenfolge, Stripesize 128K, gesamten Bereich als Typ Stripe = RAID0
auflösen? also beim booten im raidmenü einfach einen raid definieren?
Anhänge
Ja, im Boot-RAID Menü mit Strg+I
das bestehende Raid-Array, dass er ja noch anzeigt, auflösen und dann neu definieren
jetzt aber mit der intakten 200er und dem Klon auf der 400er
Wie sieht es am RAID0 aus?
hier die MBR-Analyse
nach ein bisschen Herumrechnerei auch die Fehlerstellen, die alle in der aktiven Systempartition liegen:
nach notwendiger Änderung der Plattenreihenfolge und anderer Partitionaufteilung ist die Berechnung falsch, statt StartLBA 81915435 gehört jetzt 2048 abgezogen, alle Fehler liegen in der ersten Partition
das bestehende Raid-Array, dass er ja noch anzeigt, auflösen und dann neu definieren
jetzt aber mit der intakten 200er und dem Klon auf der 400er
Wie sieht es am RAID0 aus?
hier die MBR-Analyse
Code:
Analyzing: C:\Documents and Settings\Ernst\My Documents\_Ernst\Gigabyte Schmarrn\Scatha RAID0\mbr.txt
===== MBR INFORMATION ===== at LBA=0
000001FE 55AA Boot signature='55AA'... valid
. ... Partition Table entry 1 ...
000001C2 07 Partition Type: NTFS
000001BE 00 Boot indicator: inactive
000001BF 202100 Start CC-HH-SS: 0-033-33
000001C3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001C6 00080000 Start (LBA): 2048 0-32-32
000001CA 00E0E104 Size (Blocks): 81911808 5098-197-27 39996MB 39.06GB
. ... Partition Table entry 2 ...
000001D2 07 Partition Type: NTFS
000001CE 80 Boot indicator: *** ACTIVE ***
000001CF FEFFFF Start CC-HH-SS: 1023-255-63 (not CHS addressable)
000001D3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001D6 2BEEE104 Start (LBA): 81915435 5099-0-0
000001DA 30DD0918 Size (Blocks): 403299632 25104-61-29 196923MB 192.31GB
. ... Partition Table entry 3 ...
000001E2 0F Partition Type: Extended Partition, Ext. INT 13
000001DE 00 Boot indicator: inactive
000001DF FEFFFF Start CC-HH-SS: 1023-255-63 (not CHS addressable)
000001E3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001E6 00D0EB1C Start (LBA): 485216256 30203-80-21
000001EA 00308D0B Size (Blocks): 193802240 12063-161-2 94630MB 92.41GB
. ... Partition Table entry 4 ...
000001F2 07 Partition Type: NTFS
000001EE 00 Boot indicator: inactive
000001EF FEFFFF Start CC-HH-SS: 1023-255-63 (not CHS addressable)
000001F3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001F6 5B037928 Start (LBA): 679019355 42267-0-0
000001FA 27B81A06 Size (Blocks): 102414375 6375-0-0 50007MB 48.83GBnach ein bisschen Herumrechnerei auch die Fehlerstellen, die alle in der aktiven Systempartition liegen:
Code:
# pos size status stripe Raid0LBA-StartLBA=rel Partition LBA
0x53A034000 0x00001000 - 0x(29D01*2+1)*100+a0= 87688096-81915435= 5772661- 5772668
0x868955000 0x00001000 - 0x(4344A*2+1)*100+a8= 141071784-81915435= 59156349-59156356
0x86F374000 0x00001000 - 0x(4379B*2+1)*100+A0= 141506464-81915435= 59591029-59591036
0x874147000 0x00001000 - 0x(43A0A*2+1)*100+38= 141825336-81915435= 59909901-59909908
0x874538000 0x00001000 - 0x(43A29*2+1)*100+C0= 141841344-81915435= 59925909-59925916
0x878B21000 0x00001000 - 0x(43C59*2+1)*100+08= 142127880-81915435= 60212445-60212452
0x2E93E35000 0x00001000 - part of RAID Metadatanach notwendiger Änderung der Plattenreihenfolge und anderer Partitionaufteilung ist die Berechnung falsch, statt StartLBA 81915435 gehört jetzt 2048 abgezogen, alle Fehler liegen in der ersten Partition
Zuletzt bearbeitet:
(Änderung der Plattenreihenfolge (siehe Post #50))
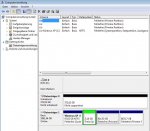
Ein wenig Nervenkitzel muss schon dabei sein - sonst wär's ja langweilig.
In der Datenträgerverwaltung haben wir jetzt den RAID0 als Datenträger 0, allerdings unpartitioniert, weil beim Auflösen/Neudefinieren des RAID der Sektor 0 auf beiden Platten gelöscht wurde. Vorsichtshalber, damit alle Daten verloren sind...
aber nicht lange
4. Restore des RAID0-MBR
Das funktioniert jetzt umgekehrt wie in 2.2
- HxD aufrufen
- im Menü Extras/open disk/physical disk 1 - diesmal readonly-Häkchen wegnehmen
- im Menü File/Open selektierst Du die DateiHDD0.0.256.bin /OK nach HDD-Reihenfolge geändert: HDD1.0.256.bin
- Im Menü Edit/Select Block eingeben:
Start: 0
End: 1FF
/hex/OK
- den markieren inhalt mit Strg+C in die Zwischenablage;
- dann klickst du den Reiter "physical disk 1" an
- Im Menü Edit/Select Block eingeben:
Start: 0
End: 1FF
/hex/OK
- den markierten Inhalt mit Strg+V mit dem aus der Zwischenablage überschreiben. Der wird dann rot dargestellt
Es darf kein popup-Fenster mit "change file size?" auftauchen, wenn doch, dann Abbrechen und nicht weitermachen
- im Menü File/Save; damit wird der geänderte MBR auf die Platte geschrieben
- HxD beenden,
Nach einem Neustart (vom System auf der IDE, Bootreihenfolge kontrollieren!) sollte in der Datenträgerverwaltung jetzt am RAID die alte Partitionierung wieder sichtbar sein.
Trara, der RAID ist wieder da! Kein Chkdisk, und auch kein Windows Explorer auf irgendeine der Partitions anleiern!
Weiter gehts nach Deiner Vollzugsmeldung (Seitenwechsel)
nur insofern, als dass das böse virtualDualBios Feature von Gigabyte 2113 Sektoren da oben gestohlen hat, ohne zu fragen- Rechts oben steht im Fenster "Sector ... of maxlba" maxlba sollte für die 500er den Wert 976773167 zeigen.
- Im Menü Edit/Select Block eingeben:
bei mir steht 976771055, ich mach trotzdem mal weiter, ist hoffentlich nicht von bedetung
In der Datenträgerverwaltung haben wir jetzt den RAID0 als Datenträger 0, allerdings unpartitioniert, weil beim Auflösen/Neudefinieren des RAID der Sektor 0 auf beiden Platten gelöscht wurde. Vorsichtshalber, damit alle Daten verloren sind...
aber nicht lange
4. Restore des RAID0-MBR
Das funktioniert jetzt umgekehrt wie in 2.2
- HxD aufrufen
- im Menü Extras/open disk/physical disk 1 - diesmal readonly-Häkchen wegnehmen
- im Menü File/Open selektierst Du die Datei
- Im Menü Edit/Select Block eingeben:
Start: 0
End: 1FF
/hex/OK
- den markieren inhalt mit Strg+C in die Zwischenablage;
- dann klickst du den Reiter "physical disk 1" an
- Im Menü Edit/Select Block eingeben:
Start: 0
End: 1FF
/hex/OK
- den markierten Inhalt mit Strg+V mit dem aus der Zwischenablage überschreiben. Der wird dann rot dargestellt
Es darf kein popup-Fenster mit "change file size?" auftauchen, wenn doch, dann Abbrechen und nicht weitermachen
- im Menü File/Save; damit wird der geänderte MBR auf die Platte geschrieben
- HxD beenden,
Nach einem Neustart (vom System auf der IDE, Bootreihenfolge kontrollieren!) sollte in der Datenträgerverwaltung jetzt am RAID die alte Partitionierung wieder sichtbar sein.
Trara, der RAID ist wieder da! Kein Chkdisk, und auch kein Windows Explorer auf irgendeine der Partitions anleiern!
Weiter gehts nach Deiner Vollzugsmeldung (Seitenwechsel)
Zuletzt bearbeitet:
(geänderte Plattenreihenfolge (siehe Post #50))
Ähnliche Themen
- Antworten
- 20
- Aufrufe
- 1.460
- Antworten
- 53
- Aufrufe
- 1.225
- Antworten
- 16
- Aufrufe
- 770
- Antworten
- 19
- Aufrufe
- 905
- Antworten
- 15
- Aufrufe
- 718


