Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Raid0 defekt
- Ersteller Scatha
- Erstellt am
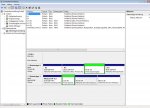
Moment, da stimmt was nicht - die Partitions sind alle RAW das müsste NTFS sein
nicht weitermachen
5. Feststellen, welche Dateien kaputtet sind
Lade Dir das Tool DiskView herunter, entzippen und Diskview.exe aufrufen. (tut leid, was Besseres find ich in meiner Freewarekiste gerade nicht)
Unten selektierst Du den Laufwerksbuchstabendes Bootsystemes der ersten Partiton auf dem RAID0, welcher in der Datenträgerverwaltung für die zweite Partiton mit 192GB 78GB angezeigt wird. Refresh-Button
Wenn wir Glück haben, ist nichts an der Metastruktur des NTFS zerstört, sonst stürzt das Tool ab und ich muss nachdenken.
Das Popup über nicht zu öffenbare Dateien solltest Du groß genug machen, um die kompletten Pfadnamen zu sehen und als Bild abspeichern.
Danach solange Zoom+, bis die Kästchen 1-2 mm groß sind, so dass du sie bequem mit dem Mauszeiger einzeln selektieren kannst
Danach die Breite solange anpassen, bis das linkeste Kästchen der zweiten Reihe den Cluster 100 zeigt (bei Doppelklick drauf kommt ein Popup, welches die Clusternummer verrät
Dann kannst Du Dich auf die spannende Suche nach den richtigen Kästchen mit Doppelklicks zum weiteren Zeitvertreib machen. :-D
Insidertipp: Wenn ein popup erscheint und Du die Maus nicht bewegst, kannst Du bei einem Fehlversuch mit „Enter“ das popup schließen, ohne den Mauszeiger zu bewegen.
Dummerweise beginnt die Partition nicht an einer 4K-Boundary, daher sind die gesuchten 8 Kästchen mit 4K auf zwei NTFS-Cluster aufgeteilt, die zu verschiedenen Dateien gehören können. jetzt schon, es reicht, wenn Du ein Kästchen gefunden hast, welches zwischen diesen Start-und Endwerten liegt
Wenn Du also die Start-und Endwerte
5772661- 5772668
59156349-59156356
59591029-59591036
59909901-59909908
59925909-59925916
60212445-60212452
der 6 Fehler lokalisiert hast, speicher die popup-Fenster mit Alt+Druck (in richtiger Breite, damit man den gesamten Dateipfad lesen kann) zur Dokumentation ab.
Wenn kein einziger System-Block darunter ist, reicht zur Korrektur ein Verschieben der Dateien in einen Ordner Deiner Wahl. Wenn das Systemdateien sind, muss man sehen, wo man eine Kopie davon herkriegt (vom anderen System vielleicht?) und sie an die ursprüngliche Location bringen
Sind es Deine eigenen Daten, gibt es vielleicht ein Backup
Mit viel Glück kann der Bereich auch nicht belegt sein, dann ist nichts zu tun...
Die Plattenreihenfolge stimmt, auch die Seriennummer der 200er
Die Stripesize konnte ich nicht kontrollieren - ist die wirklich 128K?
nicht weitermachen
5. Feststellen, welche Dateien kaputtet sind
Lade Dir das Tool DiskView herunter, entzippen und Diskview.exe aufrufen. (tut leid, was Besseres find ich in meiner Freewarekiste gerade nicht)
Unten selektierst Du den Laufwerksbuchstaben
Wenn wir Glück haben, ist nichts an der Metastruktur des NTFS zerstört, sonst stürzt das Tool ab und ich muss nachdenken.
Das Popup über nicht zu öffenbare Dateien solltest Du groß genug machen, um die kompletten Pfadnamen zu sehen und als Bild abspeichern.
Danach solange Zoom+, bis die Kästchen 1-2 mm groß sind, so dass du sie bequem mit dem Mauszeiger einzeln selektieren kannst
Danach die Breite solange anpassen, bis das linkeste Kästchen der zweiten Reihe den Cluster 100 zeigt (bei Doppelklick drauf kommt ein Popup, welches die Clusternummer verrät
Dann kannst Du Dich auf die spannende Suche nach den richtigen Kästchen mit Doppelklicks zum weiteren Zeitvertreib machen. :-D
Insidertipp: Wenn ein popup erscheint und Du die Maus nicht bewegst, kannst Du bei einem Fehlversuch mit „Enter“ das popup schließen, ohne den Mauszeiger zu bewegen.
Wenn Du also die Start-und Endwerte
59156349-59156356
59591029-59591036
59909901-59909908
59925909-59925916
60212445-60212452
Code:
0x53A034000 0x00001000 - 0x(29D01*2+[COLOR="Red"]0[/COLOR])*100+a0= 87687840-[COLOR="red"]2048[/COLOR]= [COLOR="red"]87685792- 87685799[/COLOR]
0x868955000 0x00001000 - 0x(4344A*2+[COLOR="red"]0[/COLOR])*100+a8= 141071528-[COLOR="red"]204[/COLOR]8= [COLOR="red"]141069480-141069487 [/COLOR]
0x86F374000 0x00001000 - 0x(4379B*2+[COLOR="red"]0[/COLOR])*100+A0= 141506208-[COLOR="red"]2048[/COLOR]= [COLOR="red"]141504160-141504167[/COLOR]
0x874147000 0x00001000 - 0x(43A0A*2+[COLOR="red"]0[/COLOR])*100+38= 141825080-[COLOR="red"]2048[/COLOR]= [COLOR="red"]141823032-141823039[/COLOR]
0x874538000 0x00001000 - 0x(43A29*2+[COLOR="red"]0[/COLOR])*100+C0= 141841088-[COLOR="red"]2048[/COLOR]= [COLOR="red"]141839040-141839047[/COLOR]
0x878B21000 0x00001000 - 0x(43C59*2+[COLOR="red"]0[/COLOR])*100+08= 142127624-[COLOR="red"]2048[/COLOR]= [COLOR="red"]142125576-142125583[/COLOR]
0x2E93E35000 0x00001000 - part of RAID Metadatader 6 Fehler lokalisiert hast, speicher die popup-Fenster mit Alt+Druck (in richtiger Breite, damit man den gesamten Dateipfad lesen kann) zur Dokumentation ab.
Wenn kein einziger System-Block darunter ist, reicht zur Korrektur ein Verschieben der Dateien in einen Ordner Deiner Wahl. Wenn das Systemdateien sind, muss man sehen, wo man eine Kopie davon herkriegt (vom anderen System vielleicht?) und sie an die ursprüngliche Location bringen
Sind es Deine eigenen Daten, gibt es vielleicht ein Backup
Mit viel Glück kann der Bereich auch nicht belegt sein, dann ist nichts zu tun...
Ergänzung ()
Die Plattenreihenfolge stimmt, auch die Seriennummer der 200er
Die Stripesize konnte ich nicht kontrollieren - ist die wirklich 128K?
Zuletzt bearbeitet:
(Änderung der Plattenreihenfolge (siehe Post #50))
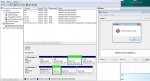
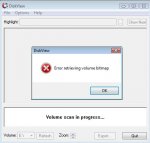
Da ist irgendwas im RAID durcheinandergekommen - er findet sichtlich die NTFS-Header nicht, was aber nicht durch die fehlerhaften Sektoren zustandekommen kann.
Brechen wir für heute ab, weitere Experimente von Deiner Seite dzt sinnlos, besser nichts anrühren. Ich muss Schlachtplan zur Fehleranalyse ausarbeiten, und poste den morgen...
Du kannst ja inzwischen mit dem Diskview auf der Reservesystem- c: zielen üben
Brechen wir für heute ab, weitere Experimente von Deiner Seite dzt sinnlos, besser nichts anrühren. Ich muss Schlachtplan zur Fehleranalyse ausarbeiten, und poste den morgen...
Du kannst ja inzwischen mit dem Diskview auf der Reservesystem- c: zielen üben
besteht denn noch hoffnung?
also wichtig wären halt nur ein paar fotos und dokumente. den verlust der dokumente hätte
ich in 2-3 tagen aufgeholt, müsste ich halt ein paar nachtschichten einlegen. ärgerlich wäre
es wegen den fotos, weil meine abschlussarbeit über lebensmittel geht und die fotos kann ich
nicht mehr nachmachen weil die lebensmittel längst verrotet sind.
bis morgen")
also wichtig wären halt nur ein paar fotos und dokumente. den verlust der dokumente hätte
ich in 2-3 tagen aufgeholt, müsste ich halt ein paar nachtschichten einlegen. ärgerlich wäre
es wegen den fotos, weil meine abschlussarbeit über lebensmittel geht und die fotos kann ich
nicht mehr nachmachen weil die lebensmittel längst verrotet sind.
bis morgen
Zuletzt bearbeitet:
kann nur eine Kleinigkeit sein - das war doch auch ein XP, waren die Partitons vielleicht verschlüsselt?
wenn nicht, werden wir morgen herausfinden was da falsch lief. Bisher wurden die Daten ja nicht verändert und sind alle noch da, halt nur irgendwie durcheinandergekommen.
Ist mir bis jetzt noch nicht passiert - höchst interessant!
ich mag es pervers - wenn man sich schon erleichtert zurücklehnen will, ein neuer Adrenalinschub
Bis wann brauchst Du spätesten Zugriff auf die ersehnten Dateien?
wenn nicht, werden wir morgen herausfinden was da falsch lief. Bisher wurden die Daten ja nicht verändert und sind alle noch da, halt nur irgendwie durcheinandergekommen.
Ist mir bis jetzt noch nicht passiert - höchst interessant!
ich mag es pervers - wenn man sich schon erleichtert zurücklehnen will, ein neuer Adrenalinschub
Bis wann brauchst Du spätesten Zugriff auf die ersehnten Dateien?
Zuletzt bearbeitet:
also es war mal xp drauf, bin dann aber auf vista umgestiegen. verschlüsselt war die größte
partition auch mal mit truecrypt, hab ich dann aber einfach mit ner formation wieder
rückgängig gemacht. die systempartition wollte ich auch mal verschlüsseln da dies die neue
truecrypt version unterstützt. zum glück hab ich die finger davon gelassen, sonst hätten wir
jetzt glaub ein größeres problem
8.9 ist abgabetermin, bissl zeit ist noch. von den dokumenten hab ich gelegentlich backups gemacht, der verlust wäre also tragbar.
hab seit 15 jahren mit pc´s zu tun, und noch nie ist mir eine platte flöten gegangen. da wird
man halt leichtsinnig mit backups. aber nach der geschichte wird sich das ändern, das kannst
du mir glauben. gerade in der heutigen zeit kosten die platten ja kaum noch was.
wenn ich mal zurückdenke als ich noch 700 DM für eine 4gb IBM ausgegeben habe...
partition auch mal mit truecrypt, hab ich dann aber einfach mit ner formation wieder
rückgängig gemacht. die systempartition wollte ich auch mal verschlüsseln da dies die neue
truecrypt version unterstützt. zum glück hab ich die finger davon gelassen, sonst hätten wir
jetzt glaub ein größeres problem
8.9 ist abgabetermin, bissl zeit ist noch. von den dokumenten hab ich gelegentlich backups gemacht, der verlust wäre also tragbar.
hab seit 15 jahren mit pc´s zu tun, und noch nie ist mir eine platte flöten gegangen. da wird
man halt leichtsinnig mit backups. aber nach der geschichte wird sich das ändern, das kannst
du mir glauben. gerade in der heutigen zeit kosten die platten ja kaum noch was.
wenn ich mal zurückdenke als ich noch 700 DM für eine 4gb IBM ausgegeben habe...
Es gibt einen Lichtblick.
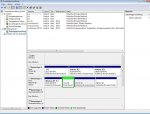
Logisch betrachtet gibt es anhand der von Dir in den ersten Posts gelieferten Snapshops vom RAID-Bootmanager und MatrixManager keinen Hinweis auf die Reihenfolge der Memberplatten. Dort war nur die alte Stripesize von 128K dokumentiert
Im Bootmanager werden sie in der Reihenfolge der Ports angelistet, ganz rechts was laut Überschrift Type/Status(Vol ID) sein sollte ist bei der intakten Platte (0) - Nachschau in Dokumentation alter Fälle hat ergeben, dass auch bei 5 Memberdisks bei allen dort (0) steht und nicht die Rehenfolge. Im Matrixmanager-Screenshot ist nur eine Memberplatte an Port0 und eine non-RAID an Port1 gelistet.
Die tatsächliche ursprüngliche Reihenfolge lässt sich mit Bestimmtheit also nur aus den alten RAID-Metadaten erheben, auf der intakten 200er hab ich verabsäumt, die Anweisung zum Auslesen zu geben - jetzt ist durch Auflösen/Neudefinition die Info überschrieben.
Auf der fehlerhaften 200er ist sie drauf, aber genau an dem Bereich angeblich ein unbehebbarer Read-Error, deswegen wurde das nicht auf die 500er übertragen, wo die alten RAID-Metadaten in der Höhe von 200GB nicht überschrieben worden wären, da die neuen ans Ende der 500GB geschrieben wurden.
Gestern war nicht mein Tag - sonst wäre mir aufgefallen und hätte mich warnen sollen, dass auch auf der fehlerhaften Platte vorne ein MBR drauf war, der von einer RAID0-Konfiguration von 2x200GB stammen muß. Der sieht so aus:
Da gibt es nur 3 primäre Partitions - am anderen MBR war noch eine Extended Partiton dabei. Kannst Du sagen, ob es die (mit mehreren logischen drin, sonst würde es keinen Sinn machen) in der letzten funktionierenden Konfiguration gab oder die Aufteilung zuletzt so wie hier aussah?
Ein weiterer Hinweis auf die falsche Plattenreihenfolge ist auch, dass derzeit keine der 4 Partitions ansprechbar ist, und die Extended keine logischen Partitions enthält.
(Einen Beweis in Form eines Screenshots, dass die Stripesize jetzt auch wieder 128K ist, hast Du zwar nicht reingestellt- das glaub ich Dir einfach mal. Den Zweifel heb ich mir als letzten Ausweg auf, denn das könnte auch dieses Symptom hervorrufen)
Bevor wir jetzt die Reihenfolge der Memberplatten umdrehen, und es damit versuchen, holen wir uns mit einem HxD-Streifzug über den Stripe-verdrehten RAID0-Array Gewissheit.
- HxD aufrufen
- im Menü Extras/open disk/physical disk 1 - Das readonly-Häkchen NICHT entfernen!
- in der Überschriftszeile muss "Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F" stehen - wenn nicht, nachfragen
- Im Menü Edit/Select Block eingeben:
Start: 100000
End: 1001FF
/hex/OK
- den markieren Inhalt mit Menü Edit(Copy as.../Editor view in die Zwischenablage;
- im Menü File/New; der Cursor steht unter Überschriftsspalte 00, klick mit der Maus in das gepunktete Kästchen rechts in der Offset-Zeile 00000000
- den Inhalt mit Strg+V übertragen - bei popup "Change length?" OK
- im Menü File/Save as... den Ordner wählen und als Dateiname "RAID0.2048.1.txt" eingeben /Save
- dann den Reiter "physical disk 1" anklicken, um den Array zu zeigen
- Im Menü Edit/Select Block eingeben:
Start: 120000
End: 1201FF
/hex/OK
- den markieren Inhalt mit Menü Edit(Copy as.../Editor view in die Zwischenablage;
- im Menü File/New; der Cursor steht unter Überschriftsspalte 00, klick mit der Maus in das gepunktete Kästchen rechts in der Offset-Zeile 00000000
- den Inhalt mit Strg+V übertragen - bei popup "Change length?" OK
- im Menü File/Save as... den Ordner wählen und als Dateiname "RAID0.2304.1.txt" eingeben /Save
- HxD beenden.
Diese beiden .txt Files in den Post-Anhang stellen
In beiden MBR-Angaben beginnt die erste primäre Partition auf Sektor 2048, was bei einer Stripesize von 128K(=256 Sektoren) dem ersten Sektor auf dem Stripe 8 (von 0 gezählt) entspricht. Bei derzeit verkehrten Memberplatten würde er aber am Stripe 9(256 Sektoren höher, auf Sektor 2304) stehen.
Anhand des an einer dieser beiden Positionen liegenden NTFS-Bootheader Inhaltes ist da drin auch die Partitiongröße ersichtlich - entweder 81911808 oder 163840000, und an der anderen Position der ältere Bootheader wahrscheinlich mit neueren Daten überschrieben.
Sollte der ältere wider Erwarten nicht überschrieben sein, müssen wir weitersuchen, um die Theorie vertauschter Memberplatten zur Gewissheit werden zu lassen...
Logisch betrachtet gibt es anhand der von Dir in den ersten Posts gelieferten Snapshops vom RAID-Bootmanager und MatrixManager keinen Hinweis auf die Reihenfolge der Memberplatten. Dort war nur die alte Stripesize von 128K dokumentiert
Im Bootmanager werden sie in der Reihenfolge der Ports angelistet, ganz rechts was laut Überschrift Type/Status(Vol ID) sein sollte ist bei der intakten Platte (0) - Nachschau in Dokumentation alter Fälle hat ergeben, dass auch bei 5 Memberdisks bei allen dort (0) steht und nicht die Rehenfolge. Im Matrixmanager-Screenshot ist nur eine Memberplatte an Port0 und eine non-RAID an Port1 gelistet.
Die tatsächliche ursprüngliche Reihenfolge lässt sich mit Bestimmtheit also nur aus den alten RAID-Metadaten erheben, auf der intakten 200er hab ich verabsäumt, die Anweisung zum Auslesen zu geben - jetzt ist durch Auflösen/Neudefinition die Info überschrieben.
Auf der fehlerhaften 200er ist sie drauf, aber genau an dem Bereich angeblich ein unbehebbarer Read-Error, deswegen wurde das nicht auf die 500er übertragen, wo die alten RAID-Metadaten in der Höhe von 200GB nicht überschrieben worden wären, da die neuen ans Ende der 500GB geschrieben wurden.
Gestern war nicht mein Tag - sonst wäre mir aufgefallen und hätte mich warnen sollen, dass auch auf der fehlerhaften Platte vorne ein MBR drauf war, der von einer RAID0-Konfiguration von 2x200GB stammen muß. Der sieht so aus:
Code:
Analyzing: C:\Documents and Settings\Ernst\My Documents\_Ernst\Gigabyte Schmarrn\Scatha RAID0\mbr1.txt
===== MBR INFORMATION ===== at LBA=0
000001FE 55AA Boot signature='55AA'... valid
. ... Partition Table entry 1 ...
000001C2 07 Partition Type: NTFS
000001BE 00 Boot indicator: inactive
000001BF 202100 Start CC-HH-SS: 0-033-33
000001C3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001C6 00080000 Start (LBA): 2048 0-32-32
000001CA 0000C409 Size (Blocks): 163840000 10198-144-58 80000MB 78.13GB
. ... Partition Table entry 2 ...
000001D2 07 Partition Type: NTFS
000001CE 80 Boot indicator: *** ACTIVE ***
000001CF FEFFFF Start CC-HH-SS: 1023-255-63 (not CHS addressable)
000001D3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001D6 0008C409 Start (LBA): 163842048 10198-177-27
000001DA 0000350C Size (Blocks): 204800000 12748-53-41 100000MB 97.66GB
. ... Partition Table entry 3 ...
000001E2 07 Partition Type: NTFS
000001DE 00 Boot indicator: inactive
000001DF FEFFFF Start CC-HH-SS: 1023-255-63 (not CHS addressable)
000001E3 FEFFFF End CC-HH-SS: 1023-255-63 (not CHS addressable)
000001E6 0008F915 Start (LBA): 368642048 22946-231-5
000001EA 00A09A18 Size (Blocks): 412786688 25694-199-41 201556MB 196.83GB
. ... Partition Table entry 4 ...
000001F2 00 Partition Type: unused partition entryDa gibt es nur 3 primäre Partitions - am anderen MBR war noch eine Extended Partiton dabei. Kannst Du sagen, ob es die (mit mehreren logischen drin, sonst würde es keinen Sinn machen) in der letzten funktionierenden Konfiguration gab oder die Aufteilung zuletzt so wie hier aussah?
Ein weiterer Hinweis auf die falsche Plattenreihenfolge ist auch, dass derzeit keine der 4 Partitions ansprechbar ist, und die Extended keine logischen Partitions enthält.
(Einen Beweis in Form eines Screenshots, dass die Stripesize jetzt auch wieder 128K ist, hast Du zwar nicht reingestellt- das glaub ich Dir einfach mal.
Bevor wir jetzt die Reihenfolge der Memberplatten umdrehen, und es damit versuchen, holen wir uns mit einem HxD-Streifzug über den Stripe-verdrehten RAID0-Array Gewissheit.
- HxD aufrufen
- im Menü Extras/open disk/physical disk 1 - Das readonly-Häkchen NICHT entfernen!
- in der Überschriftszeile muss "Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F" stehen - wenn nicht, nachfragen
- Im Menü Edit/Select Block eingeben:
Start: 100000
End: 1001FF
/hex/OK
- den markieren Inhalt mit Menü Edit(Copy as.../Editor view in die Zwischenablage;
- im Menü File/New; der Cursor steht unter Überschriftsspalte 00, klick mit der Maus in das gepunktete Kästchen rechts in der Offset-Zeile 00000000
- den Inhalt mit Strg+V übertragen - bei popup "Change length?" OK
- im Menü File/Save as... den Ordner wählen und als Dateiname "RAID0.2048.1.txt" eingeben /Save
- dann den Reiter "physical disk 1" anklicken, um den Array zu zeigen
- Im Menü Edit/Select Block eingeben:
Start: 120000
End: 1201FF
/hex/OK
- den markieren Inhalt mit Menü Edit(Copy as.../Editor view in die Zwischenablage;
- im Menü File/New; der Cursor steht unter Überschriftsspalte 00, klick mit der Maus in das gepunktete Kästchen rechts in der Offset-Zeile 00000000
- den Inhalt mit Strg+V übertragen - bei popup "Change length?" OK
- im Menü File/Save as... den Ordner wählen und als Dateiname "RAID0.2304.1.txt" eingeben /Save
- HxD beenden.
Diese beiden .txt Files in den Post-Anhang stellen
In beiden MBR-Angaben beginnt die erste primäre Partition auf Sektor 2048, was bei einer Stripesize von 128K(=256 Sektoren) dem ersten Sektor auf dem Stripe 8 (von 0 gezählt) entspricht. Bei derzeit verkehrten Memberplatten würde er aber am Stripe 9(256 Sektoren höher, auf Sektor 2304) stehen.
Anhand des an einer dieser beiden Positionen liegenden NTFS-Bootheader Inhaltes ist da drin auch die Partitiongröße ersichtlich - entweder 81911808 oder 163840000, und an der anderen Position der ältere Bootheader wahrscheinlich mit neueren Daten überschrieben.
Sollte der ältere wider Erwarten nicht überschrieben sein, müssen wir weitersuchen, um die Theorie vertauschter Memberplatten zur Gewissheit werden zu lassen...
Zuletzt bearbeitet:
Da gibt es nur 3 primäre Partitions - am anderen MBR war noch eine Extended Partiton dabei. Kannst Du sagen, ob es die (mit mehreren logischen drin, sonst würde es keinen Sinn machen) in der letzten funktionierenden Konfiguration gab oder die Aufteilung zuletzt so wie hier aussah?
die aufteilung sah so aus, meine ich mich dran zu erinnern.
Anhänge
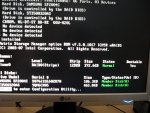
Zuletzt bearbeitet:
Auf Sektor 2048 steht Datenmüll
auf Sektor 2304 hingegen das, was auf Sektor 2048 stehen sollte...
laut NTFS-Bootrec ist die erste Partition 163840000 Sektoren groß
Tja, da haben wir die Platten falsch zusammengespannt.
Also RAID auflösen, 500GB auf Port 0, 200GB auf Port 1, RAID neu definieren
und dann den MBR neu draufschreiben (Step 4 wiederholen - Änderung beachten)
Da musst Du irgendwann mal nach dem ursprünglichen Anlegen des RAIDs die Kabeln runtergenommen und verkehrt wieder angesteckt haben. Stört nicht im Normalbetrieb solange der RAID intakt bleibt, im Fehlerbehebungsfall aber ...
...
Jetzt ist natürlich auch die schöne Tabelle für Step 5 falsch, muss ich erst korrigieren...
auf Sektor 2304 hingegen das, was auf Sektor 2048 stehen sollte...
laut NTFS-Bootrec ist die erste Partition 163840000 Sektoren groß
Code:
===== NTFS INFORMATION ===== at LBA=[COLOR="Red"]2304[/COLOR] [Array Mode, RAID0, 2 Members]
. at stripe: 9 Original at vol B
. at sector 2304
00001201FE 55AA Boot signature='55AA'... valid
0000120000 EB5290 jump around... OK
0000120003 4E54465320202020 NTFS ID... OK
000012000B 0002 Bytes per sector: 512
000012000D 08 Sectors per cluster: 8 ==> Clustersize=4K
000012000E 0000 reserved sectors: 0
0000120010 000000 always zero...OK
0000120013 0000 not used...OK
0000120015 F8 <Media descriptor>
0000120016 0000 always zero...OK
0000120018 3F00 Sectors per track: 63
000012001A FF00 # heads: 255
000012001C 00080000 # hidden sectors: [COLOR="red"]2048[/COLOR] *** MISPLACED *** +256
0000120020 00000000 <not used by NTFS>
0000120024 80008000 <not used by NTFS>
0000120028 FFFFC30900000000 Total Sectors: [COLOR="Red"]163839999[/COLOR]
0000120030 00000C0000000000 Cluster# of $MFT: 786432
0000120038 FF3F9C0000000000 Cluster# of $MFTmirr: 10239999
0000120040 F6000000 Clusters/File Record Segment: 246
0000120044 01000000 Clusters/Index Block: 1
0000120048 B958B1FAA0B1FA3A Volume Serial #
0000120050 00000000 checksumTja, da haben wir die Platten falsch zusammengespannt.
Also RAID auflösen, 500GB auf Port 0, 200GB auf Port 1, RAID neu definieren
und dann den MBR neu draufschreiben (Step 4 wiederholen - Änderung beachten)
Da musst Du irgendwann mal nach dem ursprünglichen Anlegen des RAIDs die Kabeln runtergenommen und verkehrt wieder angesteckt haben. Stört nicht im Normalbetrieb solange der RAID intakt bleibt, im Fehlerbehebungsfall aber
Jetzt ist natürlich auch die schöne Tabelle für Step 5 falsch, muss ich erst korrigieren...
Zuletzt bearbeitet:
wohooo, die daten sind wieder da
und jeder sagte mir das bei nem defekten raid0 die daten für immer futsch sind, aber die kannten dich anscheinend nicht
freitag abend war ich schon den tränen nah, und jetzt ist alles nochmal gut gegangen.
darf man dir eine kleine spende zukommen lassen oder bist du in einem verein tätig dem man spenden könnte?
und jeder sagte mir das bei nem defekten raid0 die daten für immer futsch sind, aber die kannten dich anscheinend nicht
freitag abend war ich schon den tränen nah, und jetzt ist alles nochmal gut gegangen.
darf man dir eine kleine spende zukommen lassen oder bist du in einem verein tätig dem man spenden könnte?
Anhänge

Zuletzt bearbeitet:
Den Step 5 habe ich soeben geändert, mach Dich auf die Suche nach den Dateinamen, die von den kaputten Stellen betroffen sind. Liegen alle in der ersten Partition F:, nicht im aktiven Bootsystem
Meine besten Werte, um eine Stelle zu finden, waren 7 Versuche, die schlechteste weiß ich nicht, hab bei 20 zu zählen aufgehört...
Wenn die Daten noch wo sind, kann man die auch retten, nur wie ist die Frage.
Das war wie immer unentgeltlich, ich hab ja auch mit viel Spass wieder was dabei gelernt, das ich in meine Analyseprogramme einbaue.
Vielleicht wird eines Tages ein Selbstreparaturprogramm daraus, das Ratzfatz alles wieder gut macht...
Meine besten Werte, um eine Stelle zu finden, waren 7 Versuche, die schlechteste weiß ich nicht, hab bei 20 zu zählen aufgehört...
Wenn die Daten noch wo sind, kann man die auch retten, nur wie ist die Frage.
Das war wie immer unentgeltlich, ich hab ja auch mit viel Spass wieder was dabei gelernt, das ich in meine Analyseprogramme einbaue.
Vielleicht wird eines Tages ein Selbstreparaturprogramm daraus, das Ratzfatz alles wieder gut macht...
Zuletzt bearbeitet:
alles klar, dann lass ich mal lieber mein abendbierchen weg wenn ich gleich zielen muss mit diskview
darf man fragen was du vom beruf bist bzw was du studiert hast? oder wurde das ganze wissen hobbymäßig angelernt?
darf man fragen was du vom beruf bist bzw was du studiert hast? oder wurde das ganze wissen hobbymäßig angelernt?
Das andere Tool, wo man nur die Sektornummer eingeben muss, und schon die Info kriegt, hab ich leider irgendwo verschlampt. Mit Bier geht alles besser! Prost!
35 Jahre IT als Systemfreak für scheinbar unlösbare Probleme geben etwas Vorsprung...
35 Jahre IT als Systemfreak für scheinbar unlösbare Probleme geben etwas Vorsprung...
Code:
0x53A034000 0x00001000 - 0x(29D01*2+0)*100+a0= 87687840-2048= [COLOR="Red"]87685792- 87685799[/COLOR]
0x868955000 0x00001000 - 0x(4344A*2+0)*100+a8= 141071528-2048= [COLOR="Red"]141069480-141069487[/COLOR]
0x86F374000 0x00001000 - 0x(4379B*2+0)*100+A0= 141506208-2048= [COLOR="Red"]141504160-141504167[/COLOR]
0x874147000 0x00001000 - 0x(43A0A*2+0)*100+38= 141825080-2048= [COLOR="Red"]141823032-141823039[/COLOR]
0x874538000 0x00001000 - 0x(43A29*2+0)*100+C0= 141841088-2048= [COLOR="Red"]141839040-141839047[/COLOR]
0x878B21000 0x00001000 - 0x(43C59*2+0)*100+08= 142127624-2048= [COLOR="Red"]142125576-142125583[/COLOR]
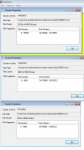
0x2E93E35000 0x00001000 - part of RAID Metadata1.87685792- 87685799 Cluster is unallocated
2.141069480-141069487 Cluster is part of a systemfile
6.142125576-142125583 Cluster is unallocated
Die restliche habe ich im Bild festgehalten
Anhänge
Zuletzt bearbeitet:
6 Fehlstellen, 2 davon nicht zugeordnet, da warens nur noch 4
1 davon ein Systemfile - das könnte böse Folgefehler geben. Welches System ist da drauf auf der ersten Partition?
3 mitten in Movies - Hast du davon Sicherungen?
Jedenfalls kannst Du die wichtigen Dateien vom RAID jetzt auf die 1TB sichern.
Auf keinen Fall ein chkdsk auf die erste Partition oder vom RAID booten einstweilen.
Wie wäre es, wenn Du dann ddrescue mal einen ganzen Tag werkeln lässt?
auch eine Lageänderung (hochkant, verkehrt) könnte vielleicht helfen,
weglassen der Kühlung ebenso, und sie dadurch etwas wärmer wird...
mit den dritten Parametersatz zum Sektor einzeln kopieren - den hast Du gar nicht ausprobiert.
und den Logfile änderst Du so ab:
die beiden intakten RAID-Platten abhängen, die 500er und die defekte 200er an die lila jMicron-Ports, Aufpassen, dass du bei der Parameterangabe nicht versehentlich von der 500er auf die 200er rettest. Das wäre die falsche Richtung.
Danach die 500er an Port0 und die intakte 200er an Port1, und weiterRAIDen (er erkennt den Array von selbst)
Wär ja gelacht, wenn sich die paar Bits nicht doch noch von der Platte kratzen ließen...
1 davon ein Systemfile - das könnte böse Folgefehler geben. Welches System ist da drauf auf der ersten Partition?
3 mitten in Movies - Hast du davon Sicherungen?
Jedenfalls kannst Du die wichtigen Dateien vom RAID jetzt auf die 1TB sichern.
Auf keinen Fall ein chkdsk auf die erste Partition oder vom RAID booten einstweilen.
Wie wäre es, wenn Du dann ddrescue mal einen ganzen Tag werkeln lässt?
auch eine Lageänderung (hochkant, verkehrt) könnte vielleicht helfen,
weglassen der Kühlung ebenso, und sie dadurch etwas wärmer wird...
mit den dritten Parametersatz zum Sektor einzeln kopieren - den hast Du gar nicht ausprobiert.
und den Logfile änderst Du so ab:
Code:
# Rescue Logfile. Created by GNU ddrescue version 1.11
# current_pos current_status
0x868955000 -
# pos size status
0x00000000 0x868955000 +
0x868955000 0x00001000 -
0x868956000 0x06A1E000 +
0x86F374000 0x00001000 -
0x86F375000 0x04DD2000 +
0x874147000 0x00001000 -
0x874148000 0x003F0000 +
0x874538000 0x00001000 -
0x874539000 0x261F8FD000 +die beiden intakten RAID-Platten abhängen, die 500er und die defekte 200er an die lila jMicron-Ports, Aufpassen, dass du bei der Parameterangabe nicht versehentlich von der 500er auf die 200er rettest. Das wäre die falsche Richtung.
Danach die 500er an Port0 und die intakte 200er an Port1, und weiterRAIDen (er erkennt den Array von selbst)
Wär ja gelacht, wenn sich die paar Bits nicht doch noch von der Platte kratzen ließen...
Zuletzt bearbeitet:
Welches System ist da drauf auf der ersten Partition?
da war vista drauf.
3 mitten in Movies - Hast du davon Sicherungen?
ja genau, die sind gesichert
mit den dritten Parametersatz zum Sektor einzeln kopieren
meinst du den hier :
HTML:
ddrescue -B -c 1 C -d -r 100 /dev/sdb /dev/sda /mnt/windows/rescued.logfehlt da vor dem großem C ein bindestrich?
tatsächlich, das sollte -C heißen 
Dann können wir die 3 ja auch weglassen, damit bleibt nur
nur aufpassen, wo die Platten gemounted sind - im Beispiel muss die sdb die 500er und die sda die 200er sein, und der logfile r/w im Zugriff.
wenn was schiefgeht, und der von vorne zu kopieren beginnt (wie man am status sieht), einfach abbrechen.
bei errsize: muss 4KiB stehen, bei errors: 1 - dann hat er den obigen logfile in Arbeit.
Dann können wir die 3 ja auch weglassen, damit bleibt nur
Code:
# Rescue Logfile. Created by GNU ddrescue version 1.11
# current_pos current_status
0x868955000 -
# pos size status
0x00000000 0x868955000 +
0x868955000 0x00001000 -
0x868956000 0x262B4E0000 +nur aufpassen, wo die Platten gemounted sind - im Beispiel muss die sdb die 500er und die sda die 200er sein, und der logfile r/w im Zugriff.
wenn was schiefgeht, und der von vorne zu kopieren beginnt (wie man am status sieht), einfach abbrechen.
bei errsize: muss 4KiB stehen, bei errors: 1 - dann hat er den obigen logfile in Arbeit.
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 20
- Aufrufe
- 1.460
- Antworten
- 53
- Aufrufe
- 1.225
- Antworten
- 16
- Aufrufe
- 770
- Antworten
- 19
- Aufrufe
- 905
- Antworten
- 15
- Aufrufe
- 718


