Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
NewsSmart Access Memory: Ryzen 3000 und Vorgängern fehlt es an Hardware-Support
In diesen Artikeln werden zwar verschiedene Memory-Remappings beschrieben, aber sie haben nichts mit den von dir beschriebenen MMIO-Registern zu tun, und die von dir postulierte 32-bit Limitation wird auch an keiner Stelle erwaehnt.
MIO configuration: configuration space is a region of memory space.
The base address and size of this range is specified by Core::X86::Msr::MmioCfgBaseAddr. The size is controlled by the number of configuration-space bus numbers supported by the system. Accesses to this range are converted configuration space as follows:
Sebastian Aaltonen hält sich bisher noch zurück. Hatte ihn mit der Adress-Mapping-Theorie konfrontiert. Aber immherhin er hat die Benchmarks von @0x8100 geliked.
Am Ende liegt's eventuell doch nur am Texture Tiling. Das ganze wird immer komplizierter. Das ist mir für die Zukunft eine Lehre, solche Dinge nicht zu leichtfertig einzuordnen. Hat mir auf Twitter ne Menge Gegenwind und Kritik eingebracht. ^^
Edit: Im Discord (Zoo of Caralhos) gibt's noch einen Beitrag zu dem Thema.
I don't see where PDEP/PEXT has anything to do with resizable BARs, or SAM. This is a pretty extraordinary claim that requires specifics and proof, like a perf profile showing PDEP/PEXT in a performance critical code path with SAM on. TPU and other sites picking this up is disappointing. PDEP/PEXT is absolutely not a PCIe physical-layer feature
About https://twitter.com/CapFrameX/status/1335615908350455809 (Benchmarks von @0x8100) - that code will suffer from slow PEXT on Zen 2 regardless of whether SAM is enabled. And SAM will offer the same benefits it does on Zen 3, by allowing all of GPU VRAM to be mapped into physical address space.
Ok, ja, das scheint auch konsistent mit den Informationen aus dem Infosec-Artikel zu sein. Die unbeantworteten Fragen bzgl. der Adress-Mapping-Theorie waeren dann halt immernoch "warum gerade so", und "warum so haeufig dass es Performance-relevant ist" (weshalb ich sie auch, wie ja schon erwaehnt, fuer sehr wahrscheinlich als unzutreffend erachte).
ZeroStrat schrieb:
Das ist mir für die Zukunft eine Lehre, solche Dinge nicht zu leichtfertig einzuordnen.
Tja, lustiger Weise habe ich dann (wahrscheinlich) die entsprechende komplementaere Erfahrung gemacht
Denn, sowohl in diesem Thread als auch im Reddit-Thread (https://www.reddit.com/r/Amd/comments/k6cbk7/zen_zen_and_zen_2_cannot_support_sam_due_to_the/) gab es eine relativ grosse Uebereinstimmung, dass diese Funktionen fundamental wichtig fuer SAM sind, anstatt nur (anscheinend) fuer eine etwas bequemere Implementation (also z.B. vs. Texture-encoding/tiling auf der GPU (Edit: Siehe auch den Tweet), oder parallel/asynced auf der CPU, etc...). Und die entsprechenden Argumentationen fuer diese (wahrscheinlich) falsche Sicht waren in allen Faellen zwar durchaus konsistent, aber auch auffaellig unvollstaendig, in dem Sinne dass alternative Optionen in viel zu hohem Masse ausgeblendet wurden! Und genau aus diesem Grund bin ich auch davon ausgegangen, dass hier mal wieder viele Leute auf einen Zug aufspringen, der oberflaechlich durchaus korrekt aussieht, bei genauerer Betrachtung aber eben (wahrscheinlich) falsch ist.
Es wuerde mich zwar immernoch nicht komplett ueberraschen, falls PDEP/PEXT doch wirklich wichtig sind, aber ich sehe es nun wirklich als sehr unwahrscheinlich an.
Ja ok, aber "Negativbeweise", im Sinne von "so und so kann es auf keinen Fall funktionieren" sind auch ersteinmal prinzipiell sehr schwierig bis unmoeglich
Da sieht die Konvention dann so aus, die existierenden einzelnen Theorien bzgl. Plausibilitaet zu untersuchen, und wenn keine einzige Sinn ergibt, dann gibt es halt nur die unbefriedigende Antwort "wir wissen es nicht". Bzw., im konkreten Fall waere die "Default-Theorie" dann wohl, dass der Inhalt des urspruenglich Tweets bzgl. der Wichtigkeit von PDEP/PEXT einfach falsch war.
Ich habe von Anfang an gesagt, dass es ein Verdacht ist, aber nicht, dass es so sein muss. Mir ist es relativ egal, ob ich da jetzt richtig oder falsch liege, mich interessiert da eher: Warum aktiviert AMD SAM nur für Zen 3. Gibt es technische Hintergründe? Und wie arbeitet MMIO-Prozessor intern für die >4GB Option.
Ich sagte ja von Anfang an auch, dass ich hier nur Grundlagenwissen habe und darauf aufbauend mir Gedanken mache, es kann so sein, muss aber nicht. Nur bin ich da eben sehr viel weiter, als die meisten anderen hier als auch auf Twitter und Discord, die pauschal erst mal AMD verteufelt haben. Für mich relevant ist der Erkenntnisgewinn, nicht dass ich richtig liege.
Und selbst das mit den MMIO-Registern ist noch nicht mal ganz vom Tisch, auch wenn es nicht auf der Programmebene ist - sprich im Linux-Kernel und Treibern oder Windows Kernel und Treibern - wäre hier interessant, wie die MMIO >4GB bei AMD bei Zen2 und davor gearbeitet hat und nun bei Zen 3. Dafür müsste man aber da den Maschinencode/Hardware-Code von AMD kennen.
Aber selbst wenn ich die MMIO-Register rausnehme und rBAR mit 64Bit so in den regulären Adressraum aufgenommen wird, kommen wir zu einem weiteren Punkt, und den habe ich gestern ja angedeutet und ich habe da nicht umsonst gestern auf die VFIO in Linux verwiesen:
Linux als auch Windows nutzen für Programme heute - alleine wegen der Sicherheit des Systemes - einen virtuellen Adressraum und auch der VRAM wird virtuell noch einmal für das Spiel abgebildet. Die Adressen, mit denen der Entwickler zu tun hat, sind eben nicht die Adressen das System verwaltet und auch hier gilt wieder: Die »Maskierungsfunktion« in der VFIO Linux für den RAM arbeitet sehr wohl mit einer Bit-Maskierungsfunktion und greift auf pdexpext zurück, sofern es möglich ist, ansonsten zu einem Workaround.
Und hier kommt halt der nächste Punkt, und das findet man in der MS-Doku dazu: Im virtuellen VRAM-Space - einmal auch per IOMMU und einmal ein andere, wird nun darauf hingewiesen, dass die VRAM-Adressen nicht mehr »gemixt« werden müssen für die Sicherheit, sondern dass der virtuell Memory-Space das übernimmt. Kurz um: Es wird dennoch ein »Swizzle« durch geführt, nur auf einer anderen Ebene und erneut: Man siehe bitte in die VIFO sowie eben in den Memory-Verwaltung. Und wie bereits angedeutet: Man findet an all diesen Stellen »Swizzle«.
Kurz um: Ich habe mich zwar mit der MMIO getäuscht - kann ich so eingestehen, ich programmiere ja kein OS und trimm das auf Sicherheit, aber eben nicht mit dem Swizzle des Speichers als ganzes und da kommen wir dann halt auch auf etwas anderes zurück:
ZeroStrat schrieb:
Sebastian Aaltonen hält sich bisher noch zurück. Hatte ihn mit der Adress-Mapping-Theorie konfrontiert. Aber immherhin er hat die Benchmarks von @0x8100 geliked.
Er hat doch hier zum Teil auch bereits was dazu geschrieben: » It's true that Zen 3 has full rate pdep/pext, which is very nice indeed. Intel has had this since Haswell. Zen 2 pdep/pext is micro-coded and super slow. This instruction can be used to implement single cycle morton decode/encode, among other things.«
Er bestätigt bereits, dass man es für »encode« und »decode« für viele Sachen gebrauchen kann und hier kommen wir halt zum virtuellen Adressraum: Die Adressen des virtuellen Adressraumes müssen auf den richtigen Adressraum abgebildet werden, man könnte das einfach per ner statischen Map machen, dann geht aber der Sinn der Speicheradressenverwurzelung verloren und wenn man dann auf diese statische Map noch zugriff hat, kann man als Entwickler wieder allerhand böse Sachen machen.
Kurz um: Auch wenn ich mich mit den MMIO Registern verrannt habe - dafür müsste man die Hardware-Codes kennen, wie AMD es da regelt - bleibt immer noch, dass an einer Stelle die Adressen des virtuellen Memoryspace in die Adressen des Hardware-Raums übersetzt werden müssen.
ZeroStrat schrieb:
Interessant ist aber auch, wenn man es streng sieht, kam von den Gegnern der Theorie nie was mit Substanz, keine Links, kein Code, nur Behauptungen...
Ja und Nein, manche Leute haben mit ihrem Einwurf - siehe eben Aaltonen als auch der Jeff Smith - haben sehr wohl mit ihren Einwürfen mich zum Nachdenken gebracht und durch den Einwurf von Smith und dann einer halben Nacht mit der Doku von Windows als auch Linux zum virtuellen Adressraum - weiß ich, dass ich grundlegend nicht falsch liege, aber ich mich mit der MMIO auf etwas Falsches gestürzt habe, weil ich den Wald vor lauter Bäumen nicht gesehen habe, wenn ich mit Memory-Adressen zutun habe, dann lass ich sie mir vom System geben und arbeite mit denen, ob die da am Ende noch mal gewürfelt werden und Co interessiert mich ja nicht.
Und das ist der Punkt: Die Absicherung des Arbeitsspeichers, als auch des VRAMs erfolgt nun durch die virtuellen Memory-Spaces, also hat man als Entwickler einer Engine und sogar ggf. als Treiber-Entwickler nicht mehr soviel zu tun. Dafür aber die Entwickler des OS und ggf. die »CPU«-Treiberentwickler.
TLR; Ein Adress-Mapping findet statt, es ist dabei egal ob BAR 64Bit <-> MMIO 32 Bit <-> CPU 64 Bit oder Hardware <-> virtuell. Ob und wie sich da pext und pdep auswirkt, steht dann auf einem anderen Punkt.
@HighDefinist
jaha, dass mit den 32Bit … ich habe da den Wald vor lauter Bäumen nicht gesehen und bin auf den falschen Baum geklettert. Jetzt habe ich einen weiteren Baum gefunden: Virtuell zu Hardware, auch da finde ich das Maskieren überall und am Ende werden die Funktionen genutzt, wissen wir bereits. Aber auch, dass es einen brauchbaren Workaround gibt. Aber ob es dann wirklich so »zeitkritisch« ist. Und selbst da auch wieder: Zeitkritisch ist kein fester Faktor, sondern fließend. Bringt die CPU zu wenig Bilder zur CPU, dann kann hier eine schnell Decodierung zwischen virtuellen zu realen Adressen Gold wert sein … ist die CPU aber ohnehin schnell genug, ist es egal.
Aber es gibt ja noch einen weiteren Baum: MMIO >4GB und wie AMD es umgesetzt hat und ob es da Unterschiede zwischen <= Zen 2 gibt und eben Zen 3.
Egal wie ich es drehe und wende: Meine ursprüngliche Vermutung mit dem Mappen der Adressen ist nicht vom Tisch, nur dass es eben an einer anderen Stelle liegt.
Und macht euch nichts draus, selbst wenn wir am Ende total falsch liegen: Wir haben wenigstens nicht pauschal und ohne jegliches Wissen AMD verteufelt, sondern wir haben uns hingesetzt, wir haben uns durch Prozessor-Dokumentationen, durch den Linux-Quelltext durch gewühlt, wir haben Indizien und Hinweise gesucht und versucht eine Erklärung zu finden. Wir sind auf die meisten Kritiker eingegangen, haben versucht Beweise zu finden und haben damit zumindest versucht Licht ins Dunkel zu bringen. Wir haben das gemacht, was eigentlich die Aufgaben von so manchen News- und Hardwareseiten gewesen wäre, die aber stattdessen lieber einen Skandal produzieren wollten, nur um des Skandalswillen.
Und noch etwas will wichtigeres haben wir getan: Wir haben nicht einfach uns hingestellt und einfach nur widersprochen, wie es manche getan haben, sondern wir haben versucht einen Beweis zu finden. Viele haben einfach nur pauschal widersprochen, keine Hinweise, nichts, sodass man da eben auch kein neues Wissen generieren konnte.
Egal wie das Thema jetzt ausgeht: Wir sind das Thema so angegangen, wie man es als rationaler Menschen angehen sollte: Mit Neugierde und Wissensdurst und vollkommen offen.
Er hat doch hier zum Teil auch bereits was dazu geschrieben: » It's true that Zen 3 has full rate pdep/pext, which is very nice indeed. Intel has had this since Haswell. Zen 2 pdep/pext is micro-coded and super slow. This instruction can be used to implement single cycle morton decode/encode, among other things.«
Er bestätigt bereits, dass man es für »encode« und »decode« für viele Sachen gebrauchen kann und hier kommen wir halt zum virtuellen Adressraum: Die Adressen des virtuellen Adressraumes müssen auf den richtigen Adressraum abgebildet werden, man könnte das einfach per ner statischen Map machen, dann geht aber der Sinn der Speicheradressenverwurzelung verloren und wenn man dann auf diese statische Map noch zugriff hat, kann man als Entwickler wieder allerhand böse Sachen machen.
Er ist der verdammte Chef-Entwickler von Unity, soll er doch mal bei Microsoft und AMD anfragen ob er den Quelltext bekommt, wie die virtuellen Adressen auf die realen Hardware-Adressen gemappt werden und was da für eine Funktion genutzt wird.
Oder er zahlt mir mal 5000,- den Monat, dann klemme ich mich gerne dahinter.
Weißt du, ich habe im pci-Subsystem von Linux zur Kommunikation mit dem PCI-Device den Hinweis auf die entsprechenden Maskierungsfunktionen gefunden, die zu pext und pdep aufgelöst werden. Ich habe im amdgpu-Subsystem im Memory-Bereich entsprechende Stellen gefunden, die zu pext und pdep aufgelöst werden und jetzt noch den virtuellen Adressraum und die Informationen von Windows dazu und dass die zu den Hardware-Adressen gemappt werden müssen.
Ich habe ehrlich gesagt keine Lust mehr, weil ich jetzt an dem Punkt angelangt bin: Ich weiß wonach ich suchen muss und ich erkenne es, wenn ich es sehe, aber ich weiß nicht mehr wo ich suchen muss und wie.
-- Bin auf Nachtwanderung, das hat jetzt zu viel Zeit alles gekostet. Ich brauch mal entspannung!
"If PDEP is needed to extract linear memory address from a GPU space address then you need that on SAM as you need it on "classic old style" 256MB limited aperture size."
Also, selbst wenn PDEP fuer die Speichertransformationen wichtig ist, ist noch nicht einmal klar, warum man mehr PDEP-Kommandos fuer SAM benoetigen wuerde, als ohne SAM...
Teralios schrieb:
Aber es gibt ja noch einen weiteren Baum: MMIO >4GB und wie AMD es umgesetzt hat und ob es da Unterschiede zwischen <= Zen 2 gibt und eben Zen 3.
Grundsaetzlich waere es schon interessant zu wissen, welche Variante des Speicherzugriffes wie haeufig und wo eingesetzt wird, und ausserdem auch, wie wichtig PDEP/PEXT nun wirklich konkret ist (anstatt es nur abzuschaetzen), aber ich vermute auch, dass es wirklich sehr viel Arbeit waere, alle PDEP/PEXT Befehle im AMD-Treiber zu finden, die Frequenz deren Aufrufe abzuschaetzen bei einem "typischen Spiel", und das dann auch noch im Kontext von SAM vs Nicht-SAM zu vergleichen.
@Teralios
Tech Journalismus ist so ein Ding. David Kantner scheint nichts mehr zu machen, Andreas Stiller ist im Ruhestand, Aigner ist deutlich weniger aktiv, Thorsten Leemhuis setzt das Jahr aus und es bleibt fast nur noch Andre von Anandtech.
Echt alles ein bisschen dünn
"If PDEP is needed to extract linear memory address from a GPU space address then you need that on SAM as you need it on "classic old style" 256MB limited aperture size."
In dem Fall nicht ganz: Classic BAR ist recht einfach: 4 Bit für die Device-ID, 28 Bit für die Adressen. Man holt sich die ersten 4 Bits, setzt die im 64Bit-Raum (sind glaub ich nur 52 aktuell) setzt die an die stelle, füllst den rest mit Null auf.
Bei der 64Bit-BAR musst du dann schon vorsichtiger sein, weil du die Devie-ID an die passende Stelle setzten musst.
Ich denke langsam, dass das Problem weniger in der Software zu suchen ist, als viel mehr darin, wie die MMIO bei AMD intern verarbeitet.
Mich würde es gar nicht stören, wenn wir falsch liegen. Ich habe mir dadurch viel angelesen und alleine deshalb hat es sich schon gelohnt
Das einzige, was mich wirklich stört, ist das Schweigen von AMD
Mich würde es gar nicht stören, wenn wir falsch liegen. Ich habe mir dadurch viel angelesen und alleine deshalb hat es sich schon gelohnt
Das einzige, was mich wirklich stört, ist das Schweigen von AMD
Postiv ist, das anscheinend auch PCiE 3.0 schnell genug ist.
Man könnte genauso fragen, ob net noch mehr ältere Intel-CPU´s auf Board XYZ
von SAM/BAR profitieren können. Weiss ja net ob die Boardhersteller alleinig darüber entscheiden.
Aber Das wird das Geschäftsmodell von A+I net zulassen, auch wenn Es momentan die Nachfragesituation entspannen tät.
Und seitdem büßte die c't nach meiner Meinung massiv an Qualität ein.
Der Kernel Log von heise ist noch so ein Highlight - aber klar mit dpa News scheint schneller Geld verdient zu sein als mit doch aufwändigen Recherchen
Mal die Frage an die Experten:
Würde denn Intel 9900k und 7700k auch SAM/Bar können?
(falls die Boards ein entspr. Bios bekämen)
aus gegebenem Anlass CP: evtl. ohne DRM bei GOG zu empfehlen für schwächere CPU`s
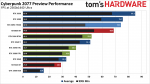
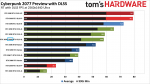
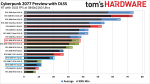
TH hatte ne Version mit DRM, lief aber trotzdem net im CPU-Limit.(ab WQHD interessiert nur noch die Graka) Cyberpunk 2077 Performance Preview and Initial Impressions | Tom's Hardware
WQHD scheint 60fps auch auf nem ollen 7700k zu schaffen.
In UHD geht den Grakas der Vram aus.(Da könnte wohl CP noch bis 2077 weiter optimieren.)
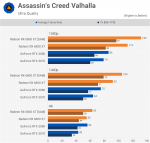
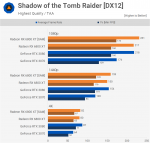
edit: mal noch ein paar Ergebnisse zu SAM von Techspot
Die Wirksamkeit lässt in höheren Auflösungen etwas nach, weil die Shader in 4k schon voll ausgelastet sind.
Könnte mir gut vorstellen, das ne 6900 von SAM in 4k mehr profitiert als die kleine XT.
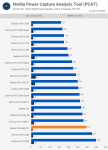
Zur Vgl.barkeit von 6800xt vs. 3080 sollte man net vergessen, das die 3080 ca. 30W mehr zieht! (7W über TBP?)
(Also könnte man die 6800xt mit PL+10 betreiben, um Vgl.barkeit herzustellen.= sollte gut skalieren, den
Vram würde ich vorsichtshalber net höher als 2124 nehmen, die 2150 könnten langsamer sein.)
btw.
Anscheinend wirds tatsächlich 6900-Customs geben.(hoffentlich net nur die TUF... ne LC wäre ideal)
Ich wüsste nicht, warum es nicht klappen sollte. Erste Tests auf einem Z490 + 10900K sehen sehr gut aus.
Was ich ja auch stets faszinierend finde, ist die Tatsache, dass SAM eher im CPU-Limit Wirkung zeigt. Es muss also letztlich etwas sein, dass auf der CPU passiert (man sprach ja teilweise von Vorteilen der GPU gegenüber der CPU) und zum anderen kann es auch nicht einfach so parallelisierbar sein auf einem anderen Kern, denn so ein 10900K kann immerhin 20 Threads wuchten. Allzu statisch oder temporär statisch können diese Operationen auch nicht sein, sonst wären die Average FPS eher unbeeindruckt davon?!
Ich bin wirklich mal gespannt, wie sich das mit dem Zen 2 Support noch entwickelt.
Mit den neuen Grakas taucht jetzt das CPU-Limit auch an Stellen auf ....
(da wird man die 99p-Werte in den Games net mehr auf die Goldwaage legen können)