Matzegr schrieb:
Steht das zu 100% fest?
die Aussage des GF Sprechers:
Zuerst ersten Frage, würde ich ich nein sagen.
Aber bei meiner Aussage war es mir Wurscht, ob es 28HP oder 28SHP heißt.
Es geht auch darum, dass wenn AMD mit Kaveri nicht nur eine iGPU-Perforance-Steigerung und iGPU-Effizienz-Steigerung schafft, sowie iCPU-Performance-Steigerung und iCPU-Effizienz-Steigerung im ähnlichen Ausmaß schafft, dass dann Intel Ende des Jahres praktisch nicht mehr darauf reagieren kann und es da ein ordentliches Kräfteverschieben geben kann, weil AMD schon jetzt ziemlich stark ist.
Es hat sich ja nicht nur meine Spekulationen einer 16nm-Einführung von Intel @ Juni 2014 bestätigt, sondern es gibt ja auch schon erst Gerüchte, ob 16nm vielleicht doch erst Ende 2014 kommt.
Alleine wenn Kaveri in Sachen iCPU & iGPU mit >15% Performance-Steigerungen und Effizienz-Steigerungen zulegen kann (von hUMA mal begesehen), dann reicht es, dass die meisten ein längeres Gesicht machen, als die Kontrollöre bei Pferdefleischproben.
Eines muss man klarstellen.
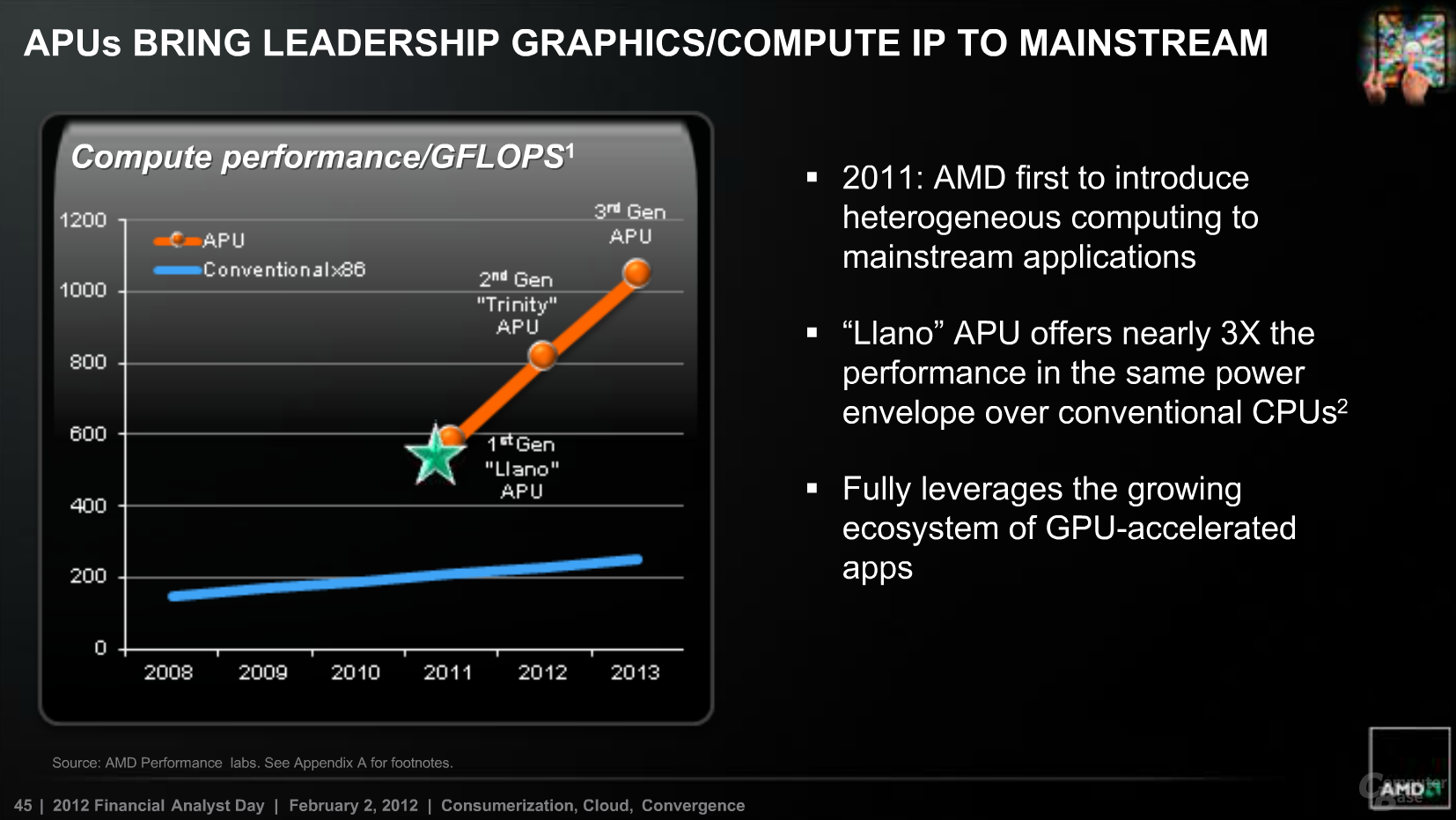
AMD bzw. Rory Read hat alle seine Folien-Marketing-Aussagen erfüllt, sodass man eine Erfüllung von 1000GFlops ausgehen kann.
Also, wenn man +30%-GFlops-Steigerungen versprochen werden, sind die Chancen recht groß, dass es eine +10 bis 15%-CPU-Steigerung könnte.
Im Falle Jaguar hat AMD seine Versprechungen von +15%-IPC-Steigerungen sogar gelogen und mit +30+% überrascht.
Die Größte Änderung hätte ich fast mit der Die-Größe gesehen und mit <200mm² gerechnet. Momentan sieht es so aus, dass Kaveri deutlich >200mm² dahertanzt. Also könnten da noch einige Überraschungen auftauchen. Denn während über die GPU-Performance schon sehr früh diese 1000GFlops erwähnten, wurde über die CPU-Performance ja noch überhaupt nichts angedeutet.
Ich kann mich noch an ne Aussage von Thomas Seifert Anfang 2012 erinnern. Da hieß es alle 28nm Produkte sind bulk.
Anfang 2013 tauchte dann beim Common-Plattform-Technology-Forum allerdings ne GF Roadmap auf wo 28nm SHP abgebildet war. Dazu
SHP muss jetzt nicht unbedingt SOI oder FD-SOI heißen. Es kann ja auch ein verbessertes HP sein ohne SOI a la ULK.
SLP hat ja genauso Stoffliche oder Qualitätsmäßige Verbesserungen gegenüber LP.