@Gelbsuch:
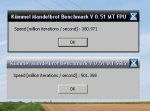
Erstmal, klar, mein Benchmark ist wirklich rein darauf abgezielt, zu sehen, was FPU oder SSE2 im core machen, da er quasi keinen Speicher braucht und komplett im 1st level cache abläuft...ist keine real world Anwendung, solange man nicht viel mit Mathe zu tun hat. Ich sehe aber schon, dass das zum Teil bei so DIVX-encodern und 3D-Renderer ebenso gut zum tragen kommt wie bei den Fractalen.
Zum zweiten schein dein Prescott einer ohne Hyper-Threading zu sein, mit sähe es schon besser aus, wie du in meiner Ergebnis-Liste sehen kannst.
Für die Beurteilung der CPUs für 'normale' Office Anwendungen oder Speicherschauflereien ist mein Benchmark natürlich nicht gedacht...eher eben da wo viel Mathe gebraucht wird, am besten noch, wo sie sich mit SSE parallelisieren läßt. SuperPI geht teilweise eher wieder auf den Speicher, aber ich kenne den Algorithmus nicht so genau, der dahintersteckt...aber parallelisiern könnte sich da vielleicht auch mal was lassen, sofern der Autor sich mal dahinterklemmt...