Nai
Lt. Commander
- Registriert
- Aug. 2012
- Beiträge
- 1.588
Bitte hier Diskussionen unterlassen, die nichts mit den Benchmarks zu tun haben. Denn ansonsten wird der Thread sehr schnell sehr unübersichtlich. Auch bitte erst die Diskussion der Benchmarkergebnisse lesen und versuchen zu verstehen. Viele Fragen würden sich dann nämlich erübrigen. Bei Crashes bitte zuerst den Watch-Dog abschalten:
http://stackoverflow.com/questions/...after-several-seconds-how-to-work-around-this
Benchmark
Zunächst das aktuelle Benchmark, welches die L2-Cache-Bandbreite, die L2-Cache-Größe und die DRAM-Bandbreite abschätzt:
NaisBenchmark32.exe 59 KB
https://mega.co.nz/#!w1NEhRZK!naPp8kAZVw327il6H_9utrdG21RLh3Z8501W60uWsMQ
NaisBenchmark64.exe 68 KB
https://mega.co.nz/#!kg0zUTIT!3jCTfdvOeO5KPsHiJl_cayNVUB5OzSxnNvC0qERJfd4
CUDA-DLLs:
cudart32_65.dll 242 KB
https://mega.co.nz/#!5g8DzA7T!FZzZf9n5pXLRp4jMvm7GAhNJ7FDF4Sj0-CpBADtFr5o
cudart64_65.dll 298 KB
https://mega.co.nz/#!Eh0GzT4D!Kjhqzljt-i-MtHV82ktDQ8RY002JT7VIhVNpUaVpN6U
Für sonstige DLL-Errors bitte zuerst Google verwenden!
Quelltext:
Code:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "helper_math.h"
#include <stdio.h>
#include <iostream>
#define CacheCount 5
static const int FloatCountPerChunk = 32 * 1024 * 1024;
static const int BenchmarkRepetitionCount = 10;
static const int MaxCacheSize = 4 * 1024 * 1024;
static const int BenchmarkCacheSizeDelta = 64 * 1024;
static const float CacheDRAMDifFactor = 1.1f;
void CheckError(int ErrorCode, char* CallName)
{
if (ErrorCode != cudaSuccess)
{
printf("Error: ");
printf(CallName);
printf("\n");
printf("CUDA errorcode %i \nExiting . . . . \n", ErrorCode);
system("pause");
exit;
}
}
__global__ void BenchMarkCacheSizeKernel(float* In, int IterCount, int CacheSizeFloat)
{
int Index = threadIdx.x;
float Temp = 1;
for (int i = 0; i < IterCount; i++)
{
Temp += In[Index];
Index += blockDim.x;
if (Index >= CacheSizeFloat)
Index -= CacheSizeFloat;
}
if (Temp == -1)
In[0] = -1;
}
__global__ void BenchMarkDRAMReadKernel(float4* In, int FloatCount)
{
int ThreadID = (blockDim.x *blockIdx.x + threadIdx.x) % FloatCount;
float4 Temp = make_float4(1);
Temp += In[ThreadID];
if (length(Temp) == -1)
In[0] = Temp;
}
__global__ void BenchMarkDRAMWriteKernel(float4* In, int FloatCount)
{
int ThreadID = (blockDim.x *blockIdx.x + threadIdx.x) % FloatCount;
float4 Temp = make_float4(1);
In[ThreadID] = Temp;;
}
__global__ void BenchMarkCacheReadKernel(float4* In, int Zero, int FloatCount)
{
int ThreadID = (blockDim.x *blockIdx.x + threadIdx.x) % FloatCount;
float4 Temp = make_float4(1);
#pragma unroll
for (int i = 0; i < CacheCount; i++)
{
Temp += In[ThreadID + i*Zero];
}
if (length(Temp) == - 1)
In[0] = Temp;
}
__global__ void BenchMarkCacheWriteKernel(float4* In, int Zero, int FloatCount)
{
int ThreadID = (blockDim.x *blockIdx.x + threadIdx.x) % FloatCount;
float4 Temp = make_float4(1);
#pragma unroll
for (int i = 0; i < CacheCount; i++)
{
In[ThreadID + i*Zero] = Temp;
}
}
int main()
{
printf("Nai's Cache Size Benchmark \n");
printf("DISCLAIMER:\n"
"This Benchmark tries to roughly estimate the L2 cache size in \n"
"CUDA by benchmarking memory latencies for differently sized\n"
"working sets and different chunks of global memory.\n"
"Use it without anything in the DRAM of your GPU or else\n"
"the swapping behaviour of the GPU may corrupt the measurement.\n"
"If the benchmark produces strange outputs nevertheless,\n"
"there is a high proability that this benchmark is not working\n"
"as intended. Your GPU is probably just fine. So please stop \n"
"making annoying whine posts in any forums, if this benchmark \n"
"produces a suspicous output.\n"
);
system("pause");
int nDevices;
CheckError(cudaGetDeviceCount(&nDevices),"Getting devices");
if (nDevices == 0)
{
printf("Error: No CUDA devices found \n");
system("pause");
exit;
}
cudaDeviceProp prop;
CheckError(cudaGetDeviceProperties(&prop, 0), "Getting device properties");
if (prop.major < 3)
{
printf("Error: Compute Capability 2.x and 1.x are not supported anymore\n");
system("pause");
exit;
}
printf("Device name: %s\n", prop.name);
printf("Device memory size: %i MiByte\n", prop.totalGlobalMem/1024/1024);
static const int PointerCount = 5000;
int ChunkSize = FloatCountPerChunk*sizeof(float);
int ChunkSizeMB = (ChunkSize / 1024) / 1024;
float* Pointers[PointerCount];
int UsedPointers = 0;
while (true)
{
int Error = cudaMalloc(&Pointers[UsedPointers], ChunkSize);
if (Error == cudaErrorMemoryAllocation)
break;
cudaMemset(Pointers[UsedPointers], 0, ChunkSize);
UsedPointers++;
}
printf("Chunk Size: %i MiByte \n", ChunkSizeMB);
printf("Allocated %i Chunks \n", UsedPointers);
printf("Allocated %i MiByte \n", ChunkSizeMB*UsedPointers);
cudaEvent_t start, stop;
CheckError(cudaEventCreate(&start), "Creating events");
CheckError(cudaEventCreate(&stop), "Creating events");
printf("Benchmarking L2 cache size\n");
for (int i = 0; i < UsedPointers; i++)
{
float BestLatency = 99999999.f;
for (int j = BenchmarkCacheSizeDelta; j <= MaxCacheSize; j += BenchmarkCacheSizeDelta)
{
int CurrentCacheFloatSize = j / sizeof(float);
int IterCount = BenchmarkRepetitionCount * (CurrentCacheFloatSize / 32);
CheckError(cudaEventRecord(start), "Recording events");
BenchMarkCacheSizeKernel <<<1, 32 >>>(Pointers[i], IterCount, CurrentCacheFloatSize);
CheckError(cudaEventRecord(stop), "Recording events");
CheckError(cudaEventSynchronize(stop), "Synchronizing with GPU");
float milliseconds = 0;
CheckError(cudaEventElapsedTime(&milliseconds, start, stop), "Calculating ellapsed time");
float Latency = (milliseconds) / ((float)(IterCount));
if (j == BenchmarkCacheSizeDelta)
{
BestLatency = Latency;
}
else if (Latency >= CacheDRAMDifFactor * BestLatency)
{
printf("L2 cache size of chunk no. %i (%i MiByte to %i MiByte): %i kiByte \n", i, ChunkSizeMB*i, ChunkSizeMB*(i + 1), (j - BenchmarkCacheSizeDelta) / 1024);
break;
}
if (j == MaxCacheSize)
{
printf("Error estimating L2 cache size of chunk no. %i (%i MiByte to %i MiByte) probably because of swapping!\n", i, ChunkSizeMB*i, ChunkSizeMB*(i + 1));
printf("Latency for the smallest working set: %f ms \nLatency for the largest working set: %f ms \n",Latency, BestLatency);
}
}
}
int Float4CountPerChunk = FloatCountPerChunk / 4;
int BlockSize = 128;
int BlockCount = BenchmarkRepetitionCount * Float4CountPerChunk / BlockSize;
printf("Benchmarking DRAM \n");
for (int i = 0; i < UsedPointers; i++)
{
float milliseconds = 0;
CheckError(cudaEventRecord(start), "Recording events");
BenchMarkDRAMReadKernel << <BlockCount, BlockSize >> >((float4*)Pointers[i], Float4CountPerChunk);
CheckError(cudaEventRecord(stop), "Recording events");
CheckError(cudaEventSynchronize(stop), "Synchronizing with GPU");
CheckError(cudaEventElapsedTime(&milliseconds, start, stop), "Calculating ellapsed time");
float BandwidthRead = ((float)(BenchmarkRepetitionCount)* (float)(ChunkSize)) / milliseconds / 1000.f / 1000.f;
CheckError(cudaEventRecord(start), "Recording events");
BenchMarkDRAMWriteKernel << <BlockCount, BlockSize >> >((float4*)Pointers[i], Float4CountPerChunk);
CheckError(cudaEventRecord(stop), "Recording events");
CheckError(cudaEventSynchronize(stop), "Synchronizing with GPU");
CheckError(cudaEventElapsedTime(&milliseconds, start, stop), "Calculating ellapsed time");
float BandwidthWrite= ((float)(BenchmarkRepetitionCount)* (float)(ChunkSize)) / milliseconds / 1000.f / 1000.f;
printf("%i MiByte to %i MiByte: %5.2f GByte/s Read, %5.2f GByte/s Write \n", ChunkSizeMB*i, ChunkSizeMB*(i + 1), BandwidthRead, BandwidthWrite);
}
printf("Benchmarking L2 cache \n");
for (int i = 0; i < UsedPointers; i++)
{
float milliseconds = 0;
CheckError(cudaEventRecord(start), "Recording events");
BenchMarkCacheReadKernel << <BlockCount, BlockSize >> >((float4*)Pointers[i], 0, Float4CountPerChunk);
CheckError(cudaEventRecord(stop), "Recording events");
CheckError(cudaEventSynchronize(stop), "Synchronizing with GPU");
CheckError(cudaEventElapsedTime(&milliseconds, start, stop), "Calculating ellapsed time");
float BandwidthRead = (((float)CacheCount* (float)BenchmarkRepetitionCount * (float)ChunkSize)) / milliseconds / 1000.f / 1000.f;
CheckError(cudaEventRecord(start), "Recording events");
BenchMarkCacheWriteKernel<< <BlockCount, BlockSize >> >((float4*)Pointers[i], 0, Float4CountPerChunk);
CheckError(cudaEventRecord(stop), "Recording events");
CheckError(cudaEventSynchronize(stop), "Synchronizing with GPU");
CheckError(cudaEventElapsedTime(&milliseconds, start, stop), "Calculating ellapsed time");
float BandwidthWrite = (((float)CacheCount* (float)BenchmarkRepetitionCount * (float)ChunkSize)) / milliseconds / 1000.f / 1000.f;
printf("%i MiByte to %i MiByte: %5.2f GByte/s Read, %5.2f GByte/s Write \n", ChunkSizeMB*i, ChunkSizeMB*(i + 1), BandwidthRead, BandwidthWrite);
}
system("pause");
}Diskussion des Benchmarks bei einer Geforce 980 GTX
Wie versprochen habe ich eine ausführliche Diskussion des Benchmarks angefertig. Die Problematik ist zwar nach NVIDIAs Statement nicht mehr aktuell, aber eventuell kann man in Zukunft das gut verwenden. Ich weiß auch nicht, ob das jemanden noch interessiert, ob es nicht zu sehr Wall of Text ist, und ob es 100 prozentig korrekt ist, ich hoffe es aber.
Zuerst soll auf die Hardware-Eigenschaften beziehungsweise Treiber-Eigenschaften eingegangen werden. Hierbei bin ich mir aber zum Teil etwas unsicher, da das nicht dokumentiert ist. Deshalb musste ich das aus den Benchmarks und diversen Stack-Overflow-Posts folgern. Ich weiß auch, dass es durchaus kritisch ist, etwas mit sich selbst zu beweisen. Aber das Gesamtbild scheint zu stimmen. Falls jemand sich mit GPGPU gut auskennen sollte, bitte sofort Kritik äußern!
Die Geforce 970 GTX hat gemäß NVIDIAs aktualisierten Spezifikationen die folgenden Daten:
- Schnelles DRAM-Segment: "physikalisch" 0 bis 3.5 GiByte, 1.75 MiByte L2-Cache, volle L2-Cache-Bandbreite, 224-Bit Speicherandindung, 192 GByte/s Peak-DRAM-Bandbreite
- Langsames DRAM-Segment: "physikalisch" 3.5 bis 4.0 GiByte, 0.25 MiByte L2-Cache, 1/7 L2-Cache-Bandbreite, 32-Bit Speicheranbindung, 28 GByte/s Peak-DRAM-Bandbreite
CUDA zeigt wahrscheinlich folgendes Allozierungsverhalten:
- Zuerst alloziert sich CUDA den freien Speicherplatz aus dem 0 bis 3.5 GiByte großen Segment.
- Dann alloziert es sich den freien Speicherplatz aus dem 3.5 bis 4.0 GiByte großen Segment.
- Zuletzt alloziert es sich den Speicherplatz aus dem 0 bis 3.5 großen Segment, welcher bereits belegt ist. In diesem Bereich muss die GPU dann irgendwie die Daten Swappen, also die Daten CUDA oder von den anderen Programmen von dem GPU-DRAM auf den CPU-DRAM auslagern.
CUDA zeigt mit Wahrscheinlichkeit folgendes Swapping-Verhalten beziehungsweise Paging-Verhalten für seinen virtuellen globalen Speicherraum:
- Das Paging ist einfach assoziativ. Falls eine Page sich im DRAM der GPU befindet, dann kann sie dort auch an nur einer bestimmten physikalischen Addresse sein.
- Auch kann es in einem CUDA-Prozess nicht zwei Pages geben, welche die selben physikalischen Adressen im GPU-DRAM verwenden. Dadurch können sich die Pages eines CUDA-Prozesses nicht selbst aus dem DRAM der GPU verdrängen. Auch kann man deshalb nur so viel Speicher in CUDA allozieren, wie viel auch auf der GPU physikalisch vorhanden sind.
- Es ist mir noch unklar, wann genau eine CUDA-Page mit einer Page von einem anderen Prozess geswapt wird. Bei einer CPU geschieht das Swappen in der Regel bei einem Page-Fault, also wenn die Page nicht mehr im DRAM der CPU sondern auf der Platte liegt. Bei den aktuellen NVIDIA GPUs scheint dies nicht der Fall zu sein (siehe unten).
- Für Speicher-Objekte aus OpenGL und DirectX gilt das einfach assoziative Paging nicht. Das heißt sie dürfen durch das Swapping überall in dem DRAM der GPU eingefügt werden.
Bei einem Page-Fault in einem Kernel, also einem Programm was auf der GPU läuft, zeigt CUDA folgendes Verhalten:
- Die Page wird aus dem DRAM der CPU über den PCI-E angefordert.
- Der Zugriff findet ohne L2-Cache statt.
- Die Page wird nicht in den DRAM der GPU geladen. Dadurch werden bei einem erneuten Zugriff auf die Page wieder die Daten aus dem DRAM der CPU angefordert.
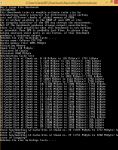
Als Nächstes soll das Benchmark diskutiert werden. Dabei wird die Messung mit einer Geforce 970 GTX aus der Antwort Nummer 31 herangenommen und zuerst in ein Diagramm eingetragen:

Das Diagramm zeigt, dass innerhalb des CUDA-Speicherbereichs von 0 bis 3072 MiByte, den CUDA sich zuerst alloziert hat, die Messergebnisse einen konstant großen Wert einnehmen. Im Speicherbereich zwischen 3072 bis 3584 MiByte sind die Messergebnisse ebenfalls konstant, aber deutlich niedriger. In den Bereichen von 3584 bis 3840 MiByte sind die Messergebnisse auch konstant und wiederum etwas kleiner. Die verbleibenden 256 MiByte der GPU konnten mit CUDA nicht alloziert werden.
Als Erstes soll auf den CUDA-Speicherbereich von 0 bis 3072 MiByte eingegangen werden. So wird in diesem CUDA-Speicherbereich eine konstant hohe Speicherbandbreite von 150 GByte/s gemessen, welche in etwa 78 % der Peak-Bandbreite des schnellen Speichersegments der GPU von 192 GByte/s entspricht. Diese 78 % sind in etwa das Maximum, welches ein durch die Speicherbandbreite limitiertes Programm auf der GPU erreichen kann. Auch wird in diesem Bereich durch das Benchmark in etwa eine Cache-Größe von 1792 KiByte geschätzt. Dies entspricht den tatsächlichen Wert der L2-Cache-Größe für das schnelle Speichersegment. Es gibt aber in diesem Bereich bei der Schätzung der L2-Cache-Größe einen Ausreißer bei 384 MiByte, der wahrscheinlich eben wegen der Schätzung entstanden ist. Ebenso ist die L2-Cache-Bandbreite in diesem Bereich mit 396 GByte/s verglichen mit den anderen Messbereichen am höchsten. Dadurch ist es sehr wahrscheinlich, dass dieser CUDA-Speicherbereich in dem schnellen physikalischen Speichersegment von 0 bis 3.5 Gibyte liegt, welches über 224 Bit angebunden ist.
Als Nächstes sollen die Messungen des CUDA-Speicherbereichs von 3072 bis 3584 MiByte diskutiert werden. Hier beträgt die gemessene DRAM-Bandbreite nur noch und nahezu konstant 22 GByte/s. Das sind in etwa 79 % der Peak-Speicherbandbreite des langsamen Speichersegments. Des Weiteren beträgt die durch das Benchmark geschätzte L2-Cache-Bandbreite mit 77 GByte/s in etwa 19 % der gemessenen Cache-Bandbreite des schnellen Speichersegments. Unter der Annahme, dass dieser CUDA-Speicherbereich im langsamen DRAM-Segment liegt, so wäre ein Bandbreitenverhältnis 1/7 also 14 % zu erwarten. Auch wurde eine Cache-Größe 256 kiByte ermittelt, welche eben der Speichergröße im langsamen Segment entspricht. Somit liegt dieser CUDA-Speicherbereich sehr wahrscheinlich in dem langsamen physikalsichen Speichersegment von 3.5 bis 4.0 GiByte, welches nur über 32 Bit angebunden ist.
In dem CUDA-Speicherbereich von 3648 bis 3776 MiByte ist die geschätzte DRAM-Bandbreite mit 12.7 GByte/s in etwa genauso hoch wie die geschätzte L2-Cache-Bandbreite mit ebenfalls 12.7 GByte/s. Auch schlägt die Ermittlung einer L2-Cache-Größe fehl. Deshalb ist es sehr wahrscheinlich, dass kein L2-Caching stattfindet. Die geschätzte DRAM-Bandbreite beträgt in etwa 80 % der PCI-E 3.0 Bandbreite mit 15.7 GByte/s. Da bei einem Page-Fault auf der GPU kein L2-Caching stattfindet und die Daten jedes mal über den PCI-E aus dem DRAM der CPU angefordert werden, verhält sich die GPU so, als ob dieser Speicherbereich sich im DRAM der CPU ausgelagert ist.
CUDA konnte sich allerdings nur 3840 MiByte allozieren. Das heißt 256 MiByte konnten durch das Benchmark nicht untersucht werden. Wahrscheinlich liegen diese 256 MiByte im schnellen DRAM-Segment und sind ein Teilrest, da sich das Benchmark nur 128 MiByte große Blöcke alloziert.
Damit scheint insgesamt der physikalische Speicher in etwa wie folgt belegt zu sein:
- 0 bis 512 MiByte (schnelles Segment): Hierinnen befinden sich Windows und andere Programme. Auch würde sich dort der dort der CUDA-Speicherbereich von 3584 bis 3840 MiByte befinden, wenn er nicht gerade wie in diesem Benchmark in dem DRAM der CPU ausgelagert ist.
- 512 bis 3584 MiByte(schnelles Segment): Hier befindet sich nur der CUDA-Speicherbereich von 0 bis 3072 MiByte
- 3584 bis 4096 MiByte(langsames Segment): Der Cuda-Speicherbereich von 3072 bis 3584 MiByte
Insgesamt stimmt das Benchmark somit sehr gut mit den aktualisierten Spezifikationen der GPU überein.
1. Edit: Habe beide Benchmarks zusammengeführt.
2. Edit: Diskussion eingebaut.
Zuletzt bearbeitet: