Apfelorange
Lieutenant
- Registriert
- Dez. 2009
- Beiträge
- 870
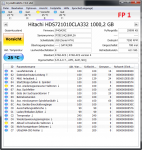
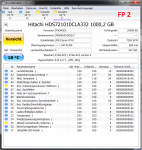
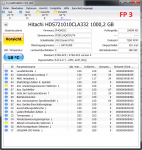
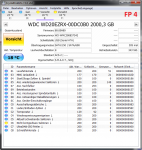
Danke für die Antwort.Die Temperaturen sollte man im Auge behalten, zu warm sollte sie nicht werden und auch zu schnelle Temperaturänderungen sind nicht gut. Bei Platten in USB Gehäuse sind also durchaus eine gewisse Vorsicht bei den Burn In Tests geboten um sie nicht dadurch zu schädigen.
Schade, dass HGST das nicht im pdf angibt, weiviel Grad pro Nutzungsdauer die Temperatur ansteigen darf. Ich erinnere mich, dass du mal ein pdf von einer anderen Platte (Enterprise) in diesem thread gepostet hast, da wurde das mit angegeben.
--------
Ich habe noch ne Verständnisfrage unabhängig von obiger Frage.
Hier https://www.thomas-krenn.com/de/wiki/Analyse_einer_fehlerhaften_Festplatte_mit_smartctl steht unter Punkt 4 folgende, ein Erklärbeispiel zu einer WD RE4 und einer Samsung HD.
Ich versteh nicht worauf das abzielt (mich irritiert, dass er irgendwas vom RAID redet. Heißt das, in einem RAID werden keine wiederzugewiesenen Sektoren verzeichnet, wenn er auf Platte A einen Sektor vom Abbild A' her wieder herstellen konnte?).
Dann hab ich noch eine Frage zu deinem Post weiter vorne
Schwebender Sektor gefunden, kann beim erneuten lesen gelesen werden, wird wieder auf 0 gesetzt dabei steigt aber der reallocated event count an und der reallocated sector count kann, muss aber nicht hochgezählt werdenNicht unbedingt, es leider auch Fälle wo zwar weiterhin der Rohwert von 05 (reallocated sector count) bei 0 bleibt, aber der von Attribut C5 (reallocation event count) steigt. Den sollte man also auch im Auge behalten. Von vorgemerkt würde ich auch nur bedingt reden, die Controller merken sich die schwebenden Sektoren eben und prüfen beim Überschreiben die neu geschriebenen Daten. Wenn diese korrekt lesbar sind, sollte der schwebende Sektor einfach verschwinden, wenn nicht, dann sollte er auch verschwinden, aber eben ein Reservesektor an seiner Stelle genutzt werden.
Schwebender Sektor gefunden, kann nicht erneut gelesen werden, wird Reservesektor zugeteilt (gemapped), auf jeden Fall steigt der "reallocated sector count". Habe ich das verstanden?
Steht der Wert 01 Lesefehlerrate in einem Zusammenhang dazu? Kann der eine Zahl aufweisen, aber 05 und C5 stehen auf 0?
Zuletzt bearbeitet: