Krautmaster
Fleet Admiral
- Registriert
- Feb. 2007
- Beiträge
- 24.312
Die für mich interessanten Themen der letzten Post greife ich nochmals auf.
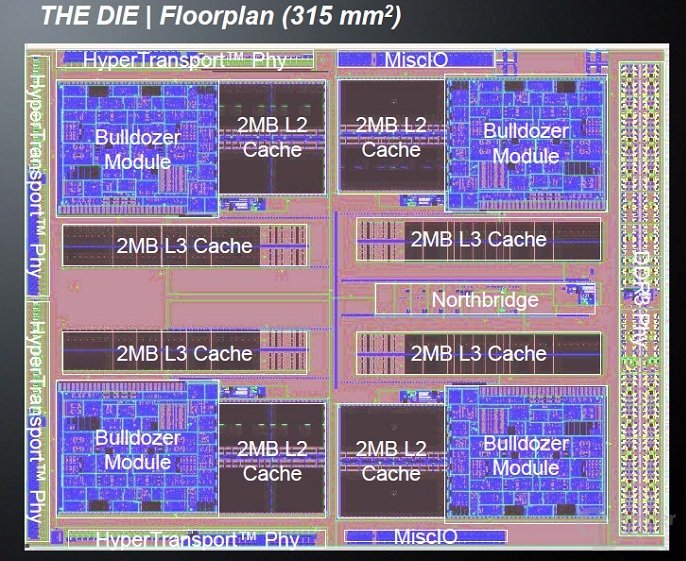
Interessant finde ich in der Tat das Fehlen von L3 Cache bei Trinity.
Wenn man die DIE von Bulldozer anschaut stellt man schnell fest, dass die eigentlichen Recheneinheiten die Leistung bringen bei ~30-40% liegen, der Cache ist ein rießen Klopfer und treibt auch den Vebrauch nach oben.
Für mich ein Resultat, dass BD natrürlich mit Fokus auf Server Umgebungen konzipiert wurde (viel Cache), Trinity für den Massenmarkt wohl eher aus Stückzahlgründen darauf verzichtet.
Weiter wird es interessant in wie fern die neuen GPU Shader dastehen, auch bezüglich Leistung / Fläche da die bisherige bereits sehr effizient war (zumindest was Spieleleistung angeht).
Interessant finde ich in der Tat das Fehlen von L3 Cache bei Trinity.
Wenn man die DIE von Bulldozer anschaut stellt man schnell fest, dass die eigentlichen Recheneinheiten die Leistung bringen bei ~30-40% liegen, der Cache ist ein rießen Klopfer und treibt auch den Vebrauch nach oben.
Für mich ein Resultat, dass BD natrürlich mit Fokus auf Server Umgebungen konzipiert wurde (viel Cache), Trinity für den Massenmarkt wohl eher aus Stückzahlgründen darauf verzichtet.
Weiter wird es interessant in wie fern die neuen GPU Shader dastehen, auch bezüglich Leistung / Fläche da die bisherige bereits sehr effizient war (zumindest was Spieleleistung angeht).
Zuletzt bearbeitet: