Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
[Sammelthread] HDD-Probleme, SMART-Analysen
- Ersteller Heen
- Erstellt am
- Status
- Für weitere Antworten geschlossen.
Mein Notebook ist eben hingefallen und nun wollte ich nachfragen, ob die Festplatte gelitten haben könnte. Die Festplatte weisst eine G-Sense-Fehlerrate von 5Dh oder 93 auf. Kann dies alles bei einem Sturz passiert sein oder deutet jeder Fehler auf eine unabhängige Erschütterung hin?
Nachdem ich das Notebook wieder aufgehoben hatte, war die Festplatte eine recht lange Zeit aktiv.
Vielen Dank für Hinweise.
Nachdem ich das Notebook wieder aufgehoben hatte, war die Festplatte eine recht lange Zeit aktiv.
Vielen Dank für Hinweise.
Anhänge

Inzersdorfer
Admiral
- Registriert
- Juli 2010
- Beiträge
- 7.493
Nein, stammen nicht von einem Fall, max. Einer davon, ansonsten ist nichts zu sehen.
Du scheinst noch Einmal mit einem blauen Auge davongekommen zu sein.
Du scheinst noch Einmal mit einem blauen Auge davongekommen zu sein.
Hi!
Festplatten haben im Controller wohl ein SRAM (Buffer) mit ECC Korrektur. Der Cache selbst (DRAM) hat aber kein ECC.
Ist das so richtig? Gilt das eigentlich nur für Enterprise Festplatten, oder auch für die Null-Acht-Fuffzehn Platte?
Das ECC des SRAMs schützt aber nicht vor Bit-Fehlern im DRAM-Cache.
Mal angenommen der SRAM-Buffer liegt zwischen Platte und DRAM-Cache und wir hätten einen Bit-Fehler im DRAM.
Die Daten aus dem Cache sollen nun auf die Platte gespeichert werden. Der Fehler vom Cache geht zum SRAM, welches eine Prüfsumme darüber erstellt und dann auf die Platte speichert. Problem: Die Prüfsumme ist nun auch falsch, weil sie für schon inkorrekte Daten aus dem Cache erstellt wurde. Es wurde quasi ein fehlerhaftes Bit mit passender Prüfsumme ausgestattet.
Beim Lesen von der Platte landen Daten zunächst im SRAM-Buffer, werden über den ECC Algorithmus ausgewertet und bei Bedarf korrigiert. Dann geht es weiter zum Cache und von dort zur Schnittstelle -> PC. Auch hier wäre ein Cache-Bitfehler ein Problem.
Bei End-to-End Parity-Check kann ein Fehler eventuell erkannt, aber nicht korrigiert werden.
Stimmt meine Annahme so wie oben beschrieben oder liege ich völlig falsch?
PS: Grund für meine Frage ist: Wir haben DRAM Speicherchips mit integrierter ECC Korrektur entwickelt. D.h. die Chips generieren beim Schreiben selbsttätig eine ECC Prüfsumme und legen diese zu den Daten ab. Beim Lesen wird die Prüfsumme ausgewertet und korrigiert. Für den Nutzer des DRAMs verhält sich der DRAM-IC völlig transparent, also exakt wie ein Standard-Chip ohne ECC, nur das er einfach nicht mehr klein zu kriegen ist und auch die typische Altersschwäche-Anzeichen nicht mehr hat.
Und ich frage mich, ob das für die Hersteller von Festplatten interessant sein könnte, insbesondere Enterprise-Platten!?!?
Gruß,
Thorsten
Festplatten haben im Controller wohl ein SRAM (Buffer) mit ECC Korrektur. Der Cache selbst (DRAM) hat aber kein ECC.
Ist das so richtig? Gilt das eigentlich nur für Enterprise Festplatten, oder auch für die Null-Acht-Fuffzehn Platte?
Das ECC des SRAMs schützt aber nicht vor Bit-Fehlern im DRAM-Cache.
Mal angenommen der SRAM-Buffer liegt zwischen Platte und DRAM-Cache und wir hätten einen Bit-Fehler im DRAM.
Die Daten aus dem Cache sollen nun auf die Platte gespeichert werden. Der Fehler vom Cache geht zum SRAM, welches eine Prüfsumme darüber erstellt und dann auf die Platte speichert. Problem: Die Prüfsumme ist nun auch falsch, weil sie für schon inkorrekte Daten aus dem Cache erstellt wurde. Es wurde quasi ein fehlerhaftes Bit mit passender Prüfsumme ausgestattet.
Beim Lesen von der Platte landen Daten zunächst im SRAM-Buffer, werden über den ECC Algorithmus ausgewertet und bei Bedarf korrigiert. Dann geht es weiter zum Cache und von dort zur Schnittstelle -> PC. Auch hier wäre ein Cache-Bitfehler ein Problem.
Bei End-to-End Parity-Check kann ein Fehler eventuell erkannt, aber nicht korrigiert werden.
Stimmt meine Annahme so wie oben beschrieben oder liege ich völlig falsch?
PS: Grund für meine Frage ist: Wir haben DRAM Speicherchips mit integrierter ECC Korrektur entwickelt. D.h. die Chips generieren beim Schreiben selbsttätig eine ECC Prüfsumme und legen diese zu den Daten ab. Beim Lesen wird die Prüfsumme ausgewertet und korrigiert. Für den Nutzer des DRAMs verhält sich der DRAM-IC völlig transparent, also exakt wie ein Standard-Chip ohne ECC, nur das er einfach nicht mehr klein zu kriegen ist und auch die typische Altersschwäche-Anzeichen nicht mehr hat.
Und ich frage mich, ob das für die Hersteller von Festplatten interessant sein könnte, insbesondere Enterprise-Platten!?!?
Gruß,
Thorsten

zum DRAM mit ECC:
Hallo Thorsten,
soweit ich das überblicke, ist Dein Ansatz korrekt.
Aus Entwicklersicht ist ein DRAM mit integriertem ECC eine feine Sache, aber in der Festplattenbranche geht es leider fast immer nur um's Geld. Und da wird sicherlich jede noch so gute Idee aus Kostengründen gestrichen.
Anders sieht es bei höherwertigen Platten (SAS, RAID, ...) aus, für die die Kunden gern auch ein wenig mehr Geld lockermachen. Da könnte das eine hervorragende Idee sein. Wie sieht es mit der Gesamtzuverlässigkeit Eurer Chips aus? Ich bin z.B. von diversen FLASH-Speichern geheilt, die dem Anwender eine heile Welt vorgaukeln, intern aber teilweise über 90% ECC-Fehler haben. Der Anwender wundert sich dann nur, warum die "Gurke" immer langsamer wird. Und plötzlich ist Schluß...
Wichtig im täglichen Einsatz bei Massenprodukten sind zwei Dinge: der Preis und die Zuverlässigkeit. Wenn Ihr dies beides in den Griff bekommt, habt Ihr schon fast gewonnen.
Gruß
THomas
@Scotty40:
0xBB: 5199 schwache Sektoren! Die Platte bitte schleunigst austauschen!
0xC7 (UDMA-Fehler) steht für eine schlechte SATA-Verbindung. Bitte das Kabel neu stecken.
Hallo Thorsten,
soweit ich das überblicke, ist Dein Ansatz korrekt.
Aus Entwicklersicht ist ein DRAM mit integriertem ECC eine feine Sache, aber in der Festplattenbranche geht es leider fast immer nur um's Geld. Und da wird sicherlich jede noch so gute Idee aus Kostengründen gestrichen.
Anders sieht es bei höherwertigen Platten (SAS, RAID, ...) aus, für die die Kunden gern auch ein wenig mehr Geld lockermachen. Da könnte das eine hervorragende Idee sein. Wie sieht es mit der Gesamtzuverlässigkeit Eurer Chips aus? Ich bin z.B. von diversen FLASH-Speichern geheilt, die dem Anwender eine heile Welt vorgaukeln, intern aber teilweise über 90% ECC-Fehler haben. Der Anwender wundert sich dann nur, warum die "Gurke" immer langsamer wird. Und plötzlich ist Schluß...
Wichtig im täglichen Einsatz bei Massenprodukten sind zwei Dinge: der Preis und die Zuverlässigkeit. Wenn Ihr dies beides in den Griff bekommt, habt Ihr schon fast gewonnen.
Gruß
THomas
Ergänzung ()
@Scotty40:
0xBB: 5199 schwache Sektoren! Die Platte bitte schleunigst austauschen!
0xC7 (UDMA-Fehler) steht für eine schlechte SATA-Verbindung. Bitte das Kabel neu stecken.
Moin Thomas,_TK_ schrieb:zum DRAM mit ECC:
Hallo Thorsten,
soweit ich das überblicke, ist Dein Ansatz korrekt.
Aus Entwicklersicht ist ein DRAM mit integriertem ECC eine feine Sache, aber in der Festplattenbranche geht es leider fast immer nur um's Geld. Und da wird sicherlich jede noch so gute Idee aus Kostengründen gestrichen.
Anders sieht es bei höherwertigen Platten (SAS, RAID, ...) aus, für die die Kunden gern auch ein wenig mehr Geld lockermachen. Da könnte das eine hervorragende Idee sein. Wie sieht es mit der Gesamtzuverlässigkeit Eurer Chips aus? Ich bin z.B. von diversen FLASH-Speichern geheilt, die dem Anwender eine heile Welt vorgaukeln, intern aber teilweise über 90% ECC-Fehler haben. Der Anwender wundert sich dann nur, warum die "Gurke" immer langsamer wird. Und plötzlich ist Schluß...
Wichtig im täglichen Einsatz bei Massenprodukten sind zwei Dinge: der Preis und die Zuverlässigkeit. Wenn Ihr dies beides in den Griff bekommt, habt Ihr schon fast gewonnen.
also zunächst zu Flash: Die Technologie der NAND Flashes ist leider schon vom Grundsatz her kritisch. SLC kann niemand bezahlen, hier wird nur 1 Bit pro Zelle gespeichert. Eine Null ist sozusagen kein elektrischer Widerstand und eine Eins ist ein sehr hoher Widerstand. Bei MLC NAND gibt es hier schon zwei Bit, also vier mögliche Widerstandswerte. Bei TLC sind es drei Bit und damit 8 Widerstandswerte.
Der Wert des in die Zelle programmierten Widerstands verändert/verflüchtigt sich mit der Zeit. Um von einem extrem hohen Widerstand bis nach ganz unten zu wandern, braucht eine Zelle locker 10 Jahre. Von daher ist SLC relativ sicher.
Aber bei MLC verflüchtigen sich erste Zellen schon nach Monaten, bei TLC nach Wochen.
Zudem leiden die Zellen bei jedem Schreibvorgang erheblich und fallen teils aus.
Der Trend geht gleichzeitig zu immer feineren Strukturen (wir nennen das Prozess-Technologien) und damit werden die NAND Flash-Zellen immer sensibler.
Man versucht diese ganzen Probleme durch sehr viele ECC-Bits auszugleichen. Je größer und komplexer die Prüfsumme, desto mehr gleichzeitig falsche Bits im Datenwort lassen sich damit korrigieren.
Aber der Begriff "zuverlässig" passt einfach überhaupt nicht zu NAND Flash. Das ist wie Katz und Hund.
Beim DRAM sieht es anders aus. Seit 30 Jahren werden DRAMs gefertigt und die Zuverlässigkeit ist sehr gut. Die meisten Geräte verwenden kein ECC und laufen trotzdem recht stabil, mal den Blue-Screen des PCs/Laptops, den sporadischen Crash des WLAN-Routers und den Aufhänger der Telefonanlage, ausgenommen.
Dennoch ist es zweifelsfrei so, daß auch DRAMs alle paar Stunden mal ein einzelnes Bit verlieren und damit begründen sich auch viele der eigenartigen Effekte verschiedenster Geräte, die sich plötzlich seltsam verhalten oder gar abstürzen, obwohl sie eigentlich das gleiche tun was sie schon seit Wochen und Monaten tun, es also eigentlich nicht an der Software liegen kann. Nach einem Neustart ist alles wieder gut, als wäre nie etwas gewesen. Zur Reparatur einsenden macht keinen Sinn, denn man kann den Fehler nicht nochmal nachvollziehen. Die Hersteller glauben also ihre Geräte wären perfekt, die Kunden sind trotzdem etwas genervt.
Ich selbst habe das Problem schon mit etlichen WLAN Routern gehabt und habe es bis heute. Kein Wunder eigentlich, wenn da eine Antenne direkt auf das DRAM strahlt und die Zellen weg-brutzelt.
DRAMs bestehen aus winzigen Kondensatoren, die eine Ladung von nur wenigen Elektronen halten. Alle 64ms brauchen die Zellen einen Refresh, weil sich sonst ihr Inhalt verflüchtigt. Eine Milliarde Zellen sind bei einem 1 Gigabit DRAM Chip auf einem Quadratzentimeter. Bei modernen Chips sind es sogar 4 mal so viel.
Wer nun darauf vertraut, daß jedes Bit unter jeden Umständen immer perfekt so schaltet, möglichst noch bei DDR3-1866, also 1.866 Milliarden mal pro Sekunde, der vertraut sicher auch darauf noch genug Rente zu bekommen.
Einzelne DRAM Zellen sind oft einfach etwas "schwach" und schalten bei intensiver Nutzung oder etwas schwächlicher Stromzufuhr manchmal nicht richtig von 1 auf 0 oder umgekehrt. Oder aber, die Zellen werden durch äußere Umstände (elektromagnetische Induktion, Umgebungsstrahlung, etc) gekippt.
Im Gegensatz zu NAND Flashes sind die Fehler in DRAMs meist nicht permanent, sondern beim nächsten Überschreiben der Zelle ist alles wieder in Ordnung.
Trotzdem altern auch DRAM Zellen. Zellen, die schon mal umgekippt sind, neigen dazu irgendwann wieder zu kippen. Und je älter die DRAMs werden, desto häufiger passiert das.
Zu geringe Spannungen mögen DRAMs genauso wenig wie zu hohe Spannungen. Betrieb bei hoher Temperatur, ständiger Datenverkehr bei hoher Speed ohne viele Pausen (im Beispiel der HDD) lässt DRAMs schnell altern.
Trotzdem sind DRAMs extrem zuverlässig. Sie zeigen hier und da mal einen Einzel-Bit-Fehler, den man selbst mit Testprogrammen kaum erwischen kann, weil sie manchmal nur in Zellen auftreten, die schon länger nicht mehr gelesen wurden. Aber die Testprogramme überschreiben den Speicher und lesen sofort danach wieder, so daß sie eher die Schreibfehler aufs RAM erkennen als die schwachen Zellen, die ihre Daten nicht bis zum nächsten Refresh halten können. Das kritisiere ich persönlich an den meisten Testprogrammen.
So, und nun nimmt man diese schon sehr zuverlässigen DRAMs und fügt noch eine ECC Korrektur hinzu. Damit erreicht man dann eine Zuverlässigkeit von mehreren tausend Jahren bis der erste Bit-Fehler durch die Korrektur hindurch flutscht, aber bis dahin ist das DRAM wahrscheinlich schon an Altersschwäche komplett verstorben.
Gruß,
Thorsten
Inzersdorfer
Admiral
- Registriert
- Juli 2010
- Beiträge
- 7.493
Sehr schön, nach dem gegenseitigen Versichern der Zuneigung und des Verstehens
können wir nun wieder zum Topic zurückkehren, den SMART Werten von Massenspeichern.
Bei der Samsung von Scotty40 teile ich die Meinung TKs bezüglich der 0xBB nicht, die liegen
innerhalb der Lesefehler u.sind den schwebenden Sektoren geschuldet.
Hier einmal die Daten wegsichern und die Platte vollständig Überschreiben, dannach formatieren
und die SMART Werte erneut erheben.
können wir nun wieder zum Topic zurückkehren, den SMART Werten von Massenspeichern.
Bei der Samsung von Scotty40 teile ich die Meinung TKs bezüglich der 0xBB nicht, die liegen
innerhalb der Lesefehler u.sind den schwebenden Sektoren geschuldet.
Hier einmal die Daten wegsichern und die Platte vollständig Überschreiben, dannach formatieren
und die SMART Werte erneut erheben.
- Registriert
- Apr. 2009
- Beiträge
- 751
Das werde ich mal probieren, die Tage werde ich mir Ersatz kaufen, glaube mit einer Seagate 720.14 2TB mache ich Preis/Leistungsmäßig am wenigsten falsch.
Die Samsung läuft auch noch wie am ersten Tag, keine Aussetzer oder ähnliches, habe mehr oder weniger durch Zufall die SMART-Werte mal ausgelesen.
Die Samsung läuft auch noch wie am ersten Tag, keine Aussetzer oder ähnliches, habe mehr oder weniger durch Zufall die SMART-Werte mal ausgelesen.
@Scotty40 / Inzersdorfer:
Die in 0xBB / 0187 aufgeführten schwachen Sektoren sind die, welche die Platte beim S.M.A.R.T. Offline-Selbsttest erkannt hat. Zumindest steht's so (oder so ähnlich) geschrieben. Wie der Hersteller das dann umgesetzt hat, ist eine ganz andere Sache. Da habe ich leider keinen Einblick.
Aber egal ob die Platte 5199 "im Hintergrund erkannte" Schwachstellen, oder fast 2000 mit gekipptem Bit hat - die wird keinesfalls besser! Nach meiner Erfahrung sind alle Werte, die deutlich über 10 liegen, ein lautes Warnsignal. Ich habe mir dabei eine logarithmische Zählweise angewöhnt: bis 10: ok. Bis 100: mit guter Technik meistens auslesbar. ab 1000: Schrott. (diese Werte basieren nicht auf Vermutungen, sondern meiner Datenbank). Hinzu kommt ja, daß die Platte meistens nicht die ganze Wahrheit anzeigt. Daher ist der Hinweis mit dem komplett neu Schreiben / Lesen goldrichtig - nur dies bringt die ganze Wahrheit ans Licht.
Und auch wenn die schwachen Sektoren wieder verschwinden sollten - bei nächter Gelegenheit tauchen wie wieder auf. Garantiert.
@Torsten:
wir sind einer Meinung! Daher sollten wir das Thema hier nicht weiter ausdehnen, sondern ggf. einen anderen Thread aufmachen. Ich hätte noch einiges beizusteuern ;-)
Die in 0xBB / 0187 aufgeführten schwachen Sektoren sind die, welche die Platte beim S.M.A.R.T. Offline-Selbsttest erkannt hat. Zumindest steht's so (oder so ähnlich) geschrieben. Wie der Hersteller das dann umgesetzt hat, ist eine ganz andere Sache. Da habe ich leider keinen Einblick.
Aber egal ob die Platte 5199 "im Hintergrund erkannte" Schwachstellen, oder fast 2000 mit gekipptem Bit hat - die wird keinesfalls besser! Nach meiner Erfahrung sind alle Werte, die deutlich über 10 liegen, ein lautes Warnsignal. Ich habe mir dabei eine logarithmische Zählweise angewöhnt: bis 10: ok. Bis 100: mit guter Technik meistens auslesbar. ab 1000: Schrott. (diese Werte basieren nicht auf Vermutungen, sondern meiner Datenbank). Hinzu kommt ja, daß die Platte meistens nicht die ganze Wahrheit anzeigt. Daher ist der Hinweis mit dem komplett neu Schreiben / Lesen goldrichtig - nur dies bringt die ganze Wahrheit ans Licht.
Und auch wenn die schwachen Sektoren wieder verschwinden sollten - bei nächter Gelegenheit tauchen wie wieder auf. Garantiert.
@Torsten:
wir sind einer Meinung! Daher sollten wir das Thema hier nicht weiter ausdehnen, sondern ggf. einen anderen Thread aufmachen. Ich hätte noch einiges beizusteuern ;-)
Inzersdorfer
Admiral
- Registriert
- Juli 2010
- Beiträge
- 7.493
187/0xBB Reported Uncorrectable Errors: The count of errors that could not be recovered using hardware ECC.
Du meintest wohl 198/0xC6 Uncorrectable Sector Count. Es kostet ja nichts, einmal zu schauen ob und wie lange
die C5 und C6 verschwinden.
Du meintest wohl 198/0xC6 Uncorrectable Sector Count. Es kostet ja nichts, einmal zu schauen ob und wie lange
die C5 und C6 verschwinden.
- 0xBB: offline uncorrectable - beim SMART-Offlinetest gefunden (ob 1 oder 2 Bits gekippt, ist nicht definiert. Vermutlich aber 2 Bits, da sich die Anzahl dieser Sektoren meistens mit denen deckt, die ich selbst mit PC-3000 nicht mehr auslesen kann)
- 0xC5: pending sectors: Hier hat die Platte festgestellt, daß nach dem Schreiben 1 Bit gekippt war. Die Daten lassen sich noch fehlerfrei dank ECC auslesen, aber nach dem nächsten SChreibvorgang wird der Sektor noch einmal kontrollgelesen. Sind dann die Daten wieder ok, wird er von der Liste gestrichen, ansonsten gegen einen Reservesektor getauscht.
- 0xC6: 2 oder mehr Bits gekippt, nicht mehr fehlerfrei auslesbar.
Die S.M.A.R.T. Werte werden durch die verschienen Hersteller verschieden umgesetzt, z.B. haut Seagate traditionell 0xC5 und 0xC6 in einen Topf, ist dafür aber bei 0xBB recht zuverlässig. Alle anderen Hersteller blenden die Rohdaten-Lesefehler aus, obwohl die naturgemäß immer auftreten. Was mich am meisten ärgert ist der Umstand, daß viele Hauptplatinen- und auch Computerhersteller im BIOS S.M.A.R.T. standardmäßig deaktivieren. Vermutlich, um Garantieansprüchen ("Ich hab' da im SMART 1 defekten Sektor...") vorzubeugen.
Einträge bei 0xBB sind bei Samsung-Platten her selten. Evtl. hat die Platine einen schlechten Kontakt (auch das wäre bei Samsung ein absolutes Novum, für vergammelte Kontakte sind eher Seagate und WD zuständig). Evtl. mal abschrauben und reinigen. Aber trotzdem bleibe ich dabei: der Platte würde ich nur noch vertrauen, wenn sie mindestens 3 Monate lang keine weiteren Einträge bringt.
- 0xC5: pending sectors: Hier hat die Platte festgestellt, daß nach dem Schreiben 1 Bit gekippt war. Die Daten lassen sich noch fehlerfrei dank ECC auslesen, aber nach dem nächsten SChreibvorgang wird der Sektor noch einmal kontrollgelesen. Sind dann die Daten wieder ok, wird er von der Liste gestrichen, ansonsten gegen einen Reservesektor getauscht.
- 0xC6: 2 oder mehr Bits gekippt, nicht mehr fehlerfrei auslesbar.
Die S.M.A.R.T. Werte werden durch die verschienen Hersteller verschieden umgesetzt, z.B. haut Seagate traditionell 0xC5 und 0xC6 in einen Topf, ist dafür aber bei 0xBB recht zuverlässig. Alle anderen Hersteller blenden die Rohdaten-Lesefehler aus, obwohl die naturgemäß immer auftreten. Was mich am meisten ärgert ist der Umstand, daß viele Hauptplatinen- und auch Computerhersteller im BIOS S.M.A.R.T. standardmäßig deaktivieren. Vermutlich, um Garantieansprüchen ("Ich hab' da im SMART 1 defekten Sektor...") vorzubeugen.
Einträge bei 0xBB sind bei Samsung-Platten her selten. Evtl. hat die Platine einen schlechten Kontakt (auch das wäre bei Samsung ein absolutes Novum, für vergammelte Kontakte sind eher Seagate und WD zuständig). Evtl. mal abschrauben und reinigen. Aber trotzdem bleibe ich dabei: der Platte würde ich nur noch vertrauen, wenn sie mindestens 3 Monate lang keine weiteren Einträge bringt.
- Registriert
- Apr. 2009
- Beiträge
- 751
Danke euch beiden für die Ausführungen, ich werde die Platte ersetzen, und nach komplett Überschreiben und Formatieren aber weiterhin im Betrieb lassen und mal beobachten.
Der Wert bei C5 ist seit 3 Tagen bei 1907 - C6 fällt leicht, jetzt bei 1865
Der Wert bei C5 ist seit 3 Tagen bei 1907 - C6 fällt leicht, jetzt bei 1865
Zuletzt bearbeitet:
Wilhelm14
Fleet Admiral
- Registriert
- Juli 2008
- Beiträge
- 23.694
Eine Seagate Barracuda 7200.14 oder auch st1000dm003
http://geizhals.at/de/seagate-barracuda-7200-14-1tb-st1000dm003-a686480.html
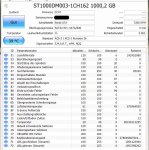
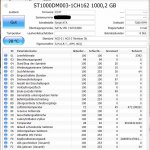
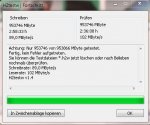
Es wurde h2testw komplett laufen lassen und vorher/nachher Screenshots erstellt. Die ersten beiden stehen auf DEC, der dritte auf HEX, was auch am Dateinamen zu erkennen ist. seagate1 ist vorher, seagate2 nachher. Gerne kann ich noch andere Screenshots einstellen (DEC 2 Byte zum Beispiel).
Mag die jemand erläutern? Taugt die HDD? Vielen Dank vorab!")
PS: Die HDD lief in einem Sharkoon Esata Dock Quick Port Pro.
http://geizhals.at/de/seagate-barracuda-7200-14-1tb-st1000dm003-a686480.html
Es wurde h2testw komplett laufen lassen und vorher/nachher Screenshots erstellt. Die ersten beiden stehen auf DEC, der dritte auf HEX, was auch am Dateinamen zu erkennen ist. seagate1 ist vorher, seagate2 nachher. Gerne kann ich noch andere Screenshots einstellen (DEC 2 Byte zum Beispiel).
Mag die jemand erläutern? Taugt die HDD? Vielen Dank vorab!
PS: Die HDD lief in einem Sharkoon Esata Dock Quick Port Pro.
Anhänge

Inzersdorfer
Admiral
- Registriert
- Juli 2010
- Beiträge
- 7.493
Was siehst du bei den Einträgen in der Spalte "Aktueller Wert"? Richtig, nix, lauter optimale Werte.
Was siehst du bei den hexadezimalen Rohwerten? Richtig, nix, kein einziges Fehlerchen.
Wie war noch gleich die Frage?
Was siehst du bei den hexadezimalen Rohwerten? Richtig, nix, kein einziges Fehlerchen.
Wie war noch gleich die Frage?
Wilhelm14
Fleet Admiral
- Registriert
- Juli 2008
- Beiträge
- 23.694
Danke. Gut, HDD i.O. Ich hielt die C5, 6, 7 für wichtig, die sind ja sogar als Rohwert auf Null. Allerdings kamen mir die anderen Rohwerte seltsam vor. Zumindest kenne ich das von Samsung oder WD anders. Hier bei der Seagate kann man ja noch bei der Temperatur vom "Rohwert" Hex 24 auf "Aktuell" 36 °C schließen. Mich wundert einfach, dass die sich riesig ändernden Rohwerte bei Lesefehlerrate und Suchfehlerrate keine Änderung bei "Aktuell" erzeugen.
Vermutlich muss ich das gar nicht alles wissen. Mir reicht die Aussage, dass die HDD i.O. ist. Danke
Vermutlich muss ich das gar nicht alles wissen. Mir reicht die Aussage, dass die HDD i.O. ist. Danke
Inzersdorfer
Admiral
- Registriert
- Juli 2010
- Beiträge
- 7.493
Bei 01 und 07 verwendet Seagate einen geteilt auszuwertenden hexadezimalen 48 Bit Rohwert, die ersten 16 Bit/ 4 Stellen sind die Anzahl der Fehler, die letzten 32 Bit / 8 Stellen die Anzahl der Lese/Such-Vorgänge.
Habe auch mal eine Frage zu meiner HDD. Diese ist eine SAMSUNG HD154UI
----------------------------------------------------------------------------
(5) SAMSUNG HD154UI
----------------------------------------------------------------------------
Model : SAMSUNG HD154UI
Firmware : 1AG01118
Disk Size : 1500,3 GB (8,4/137,4/1500,3/1500,3)
Buffer Size : 32767 KB
Queue Depth : 32
# of Sectors : 2930277168
Health Status : Vorsicht
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
C5 100 100 __0 000000000002 Aktuell schwebende Sektoren
C6 100 100 __0 000000000001 Unkorrigierbare Sektoren
Ich habe das mal gekürzt mit den wichtigsten Infos. Diese HDD wird laut Crystal Disk Info mit gelb und Vorsicht angezeigt.
Aktuell schwebende Sektoren = 2
Unkorrigierbare Sektoren = 1
Allerdings sind diese Werte eine ganze Weile (sprich mehrere Monate, evtl auch 1 Jahr schon) unveränderlich immer auf 2 und 1.
Muss ich mir da Sorgen machen oder läuft das noch eine Weile?
----------------------------------------------------------------------------
(5) SAMSUNG HD154UI
----------------------------------------------------------------------------
Model : SAMSUNG HD154UI
Firmware : 1AG01118
Disk Size : 1500,3 GB (8,4/137,4/1500,3/1500,3)
Buffer Size : 32767 KB
Queue Depth : 32
# of Sectors : 2930277168
Health Status : Vorsicht
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
C5 100 100 __0 000000000002 Aktuell schwebende Sektoren
C6 100 100 __0 000000000001 Unkorrigierbare Sektoren
Ich habe das mal gekürzt mit den wichtigsten Infos. Diese HDD wird laut Crystal Disk Info mit gelb und Vorsicht angezeigt.
Aktuell schwebende Sektoren = 2
Unkorrigierbare Sektoren = 1
Allerdings sind diese Werte eine ganze Weile (sprich mehrere Monate, evtl auch 1 Jahr schon) unveränderlich immer auf 2 und 1.
Muss ich mir da Sorgen machen oder läuft das noch eine Weile?
Inzersdorfer
Admiral
- Registriert
- Juli 2010
- Beiträge
- 7.493
Nein, wenn solange gleichbleibend dann gibts keinen Grund zur Panik. Hier in den CDI Optionen: mit Windows mitstarten, Verzögerung 30 Sekunden, Hauptfenster verstecken wählen und die Warnschwelle in Optionen/Zustandseinstellungen auf 3 bzw. 2 einstellen, dann gibts eine Warnung bei einem weiteren C5/C6.
- Status
- Für weitere Antworten geschlossen.
Ähnliche Themen
- Antworten
- 7.721
- Aufrufe
- 712.474


