NRJ, ja sind sie. Die eine hat 3 Schreib- und einen Lesefehler, aber die würde ich nicht als kritisch einordnen. Achte trotzdem auf ein Backup, also keine Daten zu verlieren, sollte eine der Platten ausfallen, denn das kann immer mal passieren, z.B. reicht es wenn eine HDD aus einigen cm Hähe reunterfällt und nur Backups schützen dann vor Datenverlust!
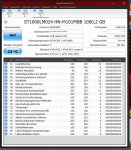
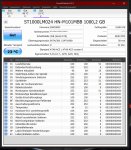
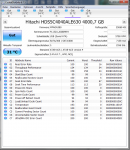
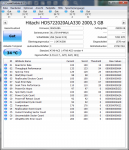
bop99, Schwebende Sektoren sind Sektoren deren Daten nicht mehr zur ECC passen. Da die korrekten Daten nicht mehr feststellbar sind, gibt die Platte statt falscher Daten einen Lesefehler als Antwort wenn man versucht diese zu lesen. Das kann auch anderen Gründe als defekte Oberflächen haben, z.B. einen Stromausfall während eines Schreibvorgang der dazu führt, dass eben nicht die ganze Daten plus der neuen ECC geschrieben wurden oder wegen eines Stoßes oder Vibrationen ist der Kopf beim Schreiben aus der Spur gekommen und hat Daten auf der Nachbarspur überschrieben. Wie viele HDDs sind im Gehäuse? Die Green haben keine Vibrationssensoren, die sind nur dafür gemacht als einige HDD im Gehäuse verbaut zu sein!
Die Controller merken sich die schwebenden Sektoren und prüfen die Daten nach dem erneuten Schreiben auf diese Sektoren, dann verschwinden diese einfach oder werden eben durch Reservesektoren ersetzt. Erstens ist offenbar bei Deiner Platte passiert. Das Geräusch dürfte vom Parken der Köpfe kommen, schau mal auf den Rohwert der Lade-Entladezyklen, wenn der sich nach dem Geräusch erhöht hat, ist es das. Bedachte das man bei
CrystalDiskInfo F5 drücken muss um die Werte neu einlesen zu lassen. Abhilfe könnte das Tool
WDIDLE3 bringen, aber das läuft richtig nur unter DOS, es funktioniert nicht korrekt in einer Eingabeaufforderung von Windows!