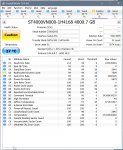
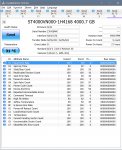
Die TBW sind nur für die Garantie relevant, die beträgt nur 3 Jahre und ist sowieso abgelaufen. Für den Zustand sind die verbrauchten P/E Zyklen wichtig, die stehen im Rohwert vom Attribut AB und der ist 0x01E2 = 482, der Aktuelle Wert von 84 gibt an, dass noch 84% der Spezifizierten P/E Zyjlen der NANDs übrig sind, wenn Du also so 5% der P/E Zyklen pro Jahr verbraucht hast, hast Du noch spezifizierte für die nächsten 17 Jahre übrig. Aber selbst dann sind die ANNDs noch längst nicht am Ende, bei allen SSDs von NAND Herstellern oder deren Tochterfirmen von denen ich bisher Endurancetests gesehen habe, hielten die NANDs mindestens 2 bis 3, bei einer Crucial m4 sogar 12 mal so viele P/E Zyklen wie spezifizieert aus, bevor die SSD platt war, rechen beim bisherigen Verbrauch also noch mal mit locker nochmal 20 Jahren nach den 17 Jahren, wenn die spezifizierten P/E Zyklen verbraucht sind.
Von der 840 Pro 128GB gibt es hier einen Endurance Test, die schneidet dort aber bzgl. der Schreibgeschwindigkeit viel besser als bei Techreport ab. Die 128GB 840 Pro hat dort mehr als 3PB geschrieben, die 256GB müsste also etwa doppelt so viel schaffen, wird bei der "Geschwindigkeit" mit der Techreport arbeitet also noch einige Jahre brauchen und längst nicht mehr aktuell sein, wenn der Test zuende geht.
Übrigens sieht man dort auch gut, wie konservativ die spezifizierten Zyklen angegeben sind:


Weiter sieht man gut, dass die Badblock wie bei vielen anderen SSD im Dauerschreibtest auf xtremesystems.org so etwa nach der Hälfte der Zeit anfangen zu steigen:


Aber erst wenn die ECC-Recoveries massiv ansteigen, dann wird es wirklich kritisch und die NANDs sind dem Ende nah. Die 840 Pro hält rund 6 mal so viel aus und der Verschleiß fing erst wirklich nach der dreifachen Anzahl von P/E Zyklen an und kritisch wird er, wenn die ECC Fehlerrate anfängt massiv zu steigen.
Von der 840 Pro 128GB gibt es hier einen Endurance Test, die schneidet dort aber bzgl. der Schreibgeschwindigkeit viel besser als bei Techreport ab. Die 128GB 840 Pro hat dort mehr als 3PB geschrieben, die 256GB müsste also etwa doppelt so viel schaffen, wird bei der "Geschwindigkeit" mit der Techreport arbeitet also noch einige Jahre brauchen und längst nicht mehr aktuell sein, wenn der Test zuende geht.
Übrigens sieht man dort auch gut, wie konservativ die spezifizierten Zyklen angegeben sind:
Weiter sieht man gut, dass die Badblock wie bei vielen anderen SSD im Dauerschreibtest auf xtremesystems.org so etwa nach der Hälfte der Zeit anfangen zu steigen:
Aber erst wenn die ECC-Recoveries massiv ansteigen, dann wird es wirklich kritisch und die NANDs sind dem Ende nah. Die 840 Pro hält rund 6 mal so viel aus und der Verschleiß fing erst wirklich nach der dreifachen Anzahl von P/E Zyklen an und kritisch wird er, wenn die ECC Fehlerrate anfängt massiv zu steigen.