Um eine Speicherbandbreite von 512 GB/s zu erreichen werden derzeit 16 GDDR5-Chips benötigt, die jeweils eine Geschwindigkeit 8 Gb/s leisten und mit Hilfe eines 512 MB großen Interface angebunden werden müssen. Der Energiebedarf liegt dann bei etwa 85 W. Bei HBM werden dagegen vier Speicherstapel (mit jeweils vier Dies) mit einer Geschwindigkeit von 1 Gb/s über eine 1024 Bit breiten Schnittstelle angebunden; der Stromverbrauch bleibt dann bei unter 30 W.
Naja, wenn man eine Speicheranbindung von 1024 bit anstrebt, könnte AMD eventuell den Hawaii mit der Technik schneller anpassen.
Sagen wir AMD lässt das Hawaii Interface auf bit 768 Bit anwachsen, das würde dann genau (mit den 40% Ersparnis) 1075,2 betragen.
Anderseits müsste man aber den HBM dann anders anbinden :/
Vllt passt das oben erwähnte Beispiel nicht, man würde viel langsameren HBM Speicher nehmen, das Interface vllt schrumpfen um dann anschließend einen kleineren MCM Chip realisieren können.
Wenn neben dem GPU Die dann eben HBM integriert wird, wird AMD wohl die GPU selbst versuchen schrumpfen zu lasen um die Kosten zu senken und die Kühlung zu vereinfachen.
Oder HBM wird sogar direkt auf den Chip integriert. Naja ich lasse mich bis dahin einfach überraschen.
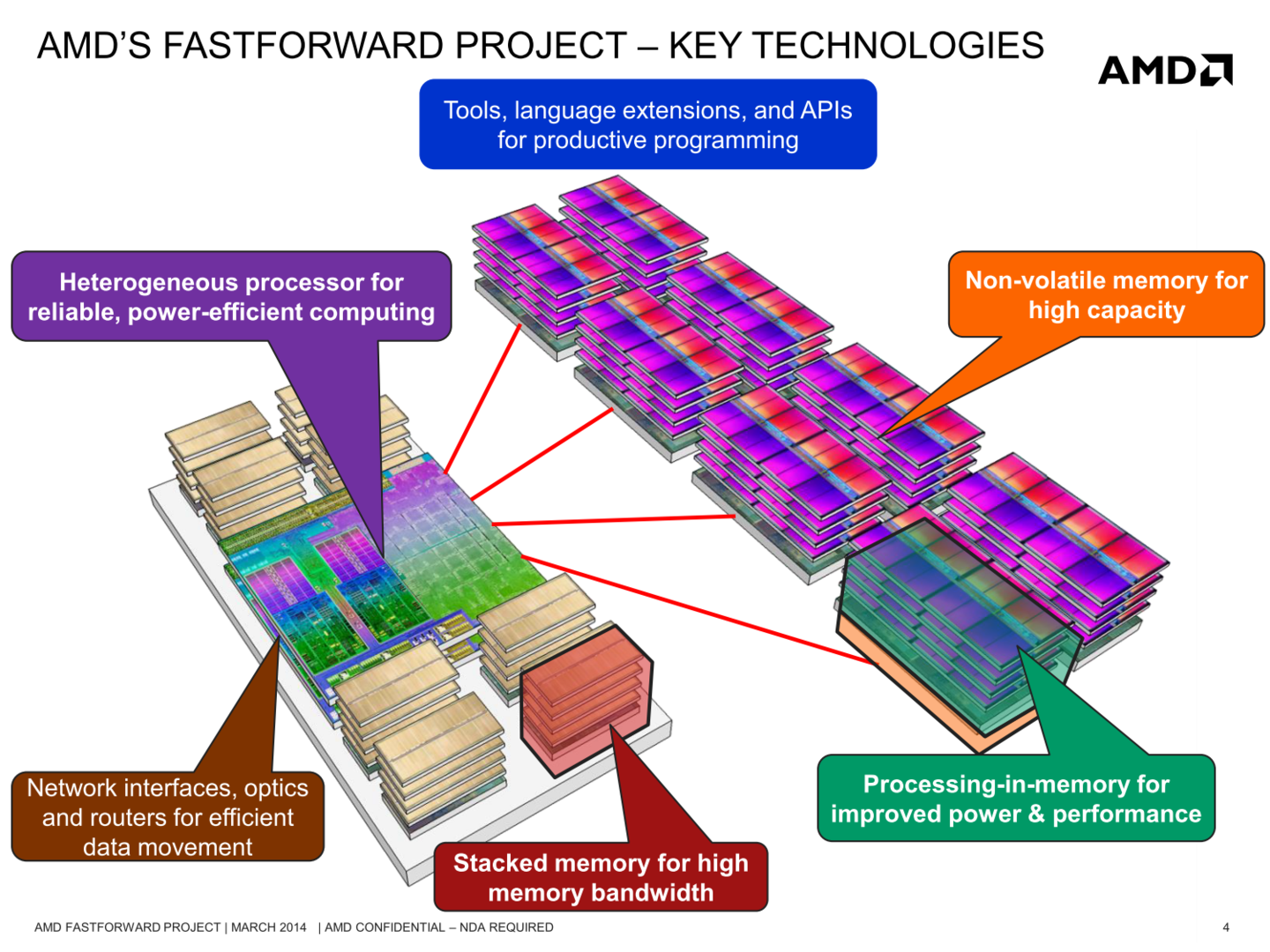
Ich glaube, AMD hat in der Technik mehr Sinn gesehen, weil diese Technik jetzt bei Carrizo eventuell genützt werden kann. Den L2 Cache hat man offensichtlich nicht stark erhöht, weil man da wohl eher schon an Wege interessiert ist, HBM in die nächsten Karten zu integrieren.
https://www.computerbase.de/news/prozessoren/amd-mit-stacked-memory-und-pim-bei-zukunfts-apus.45765/
Eventuell können wir uns von dem Design ableiten, wie es mal bei den Grafikkarten aussehen wird.
Auch sagte ich schon mal, AMD könnte genauso eines Tages APU Karten als Grafikkarte auf den Markt bringen, aber genauso könnte NV Tegra Know How auf ihre Karten packen.