smartctl 5.41 2011-06-09 r3365 [i686-linux-3.2.13-pmagic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF INFORMATION SECTION ===
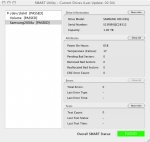
Model Family: SAMSUNG SpinPoint P80
Device Model: SAMSUNG SP1614N
Serial Number: S016J10Y360778
Firmware Version: TM100-30
User Capacity: 160,041,885,696 bytes [160 GB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: 7
ATA Standard is: ATA/ATAPI-7 T13 1532D revision 0
Local Time is: Sat Feb 2 16:04:24 2013 UTC
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
See vendor-specific Attribute list for marginal Attributes.
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 6000) seconds.
Offline data collection
capabilities: (0x1b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
No Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
No General Purpose Logging support.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 100) minutes.
SMART Attributes Data Structure revision number: 16
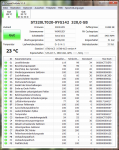
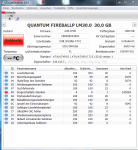
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 100 096 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0007 100 001 025 Pre-fail Always In_the_past 5696
4 Start_Stop_Count 0x0032 096 096 000 Old_age Always - 4856
5 Reallocated_Sector_Ct 0x0033 100 100 011 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 100 100 051 Pre-fail Always - 0
8 Seek_Time_Performance 0x0025 100 100 015 Pre-fail Offline - 0
9 Power_On_Half_Minutes 0x0032 098 098 000 Old_age Always - 11821h+04m
10 Spin_Retry_Count 0x0033 100 100 051 Pre-fail Always - 0
11 Calibration_Retry_Count 0x0012 100 100 000 Old_age Always - 527
12 Power_Cycle_Count 0x0032 097 097 000 Old_age Always - 3812
194 Temperature_Celsius 0x0022 151 091 000 Old_age Always - 29
195 Hardware_ECC_Recovered 0x001a 100 100 000 Old_age Always - 82338
196 Reallocated_Event_Count 0x0032 099 099 000 Old_age Always - 4
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Total_Offl_Uncorrectabl 0x0030 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x000a 100 100 051 Old_age Always - 0
201 Soft_Read_Error_Rate 0x000a 100 100 051 Old_age Always - 0
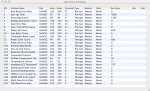
SMART Error Log Version: 1
ATA Error Count: 7 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 7 occurred at disk power-on lifetime: 11820 hours (492 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
04 51 01 01 4f c2 b0 Error: ABRT
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
b0 d0 01 01 4f c2 b0 00 00:04:35.375 SMART READ DATA
ec 00 00 00 00 00 b0 00 00:04:35.375 IDENTIFY DEVICE
ec 00 00 00 00 00 b0 00 00:00:35.563 IDENTIFY DEVICE
ef 02 00 00 00 00 b0 00 00:00:35.563 SET FEATURES [Enable write cache]
f5 00 00 00 00 00 b0 00 00:00:35.563 SECURITY FREEZE LOCK
Error 6 occurred at disk power-on lifetime: 9835 hours (409 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
01 51 00 1f 12 60 e0 Error: AMNF at LBA = 0x0060121f = 6296095
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
c8 d8 00 1f 12 60 e0 00 00:01:28.063 READ DMA
c8 d8 08 df 0c 60 e0 00 00:01:28.000 READ DMA
c8 d8 88 e7 0a 60 e0 00 00:01:27.625 READ DMA
c8 d8 70 67 09 60 e0 00 00:01:27.438 READ DMA
c8 d8 08 a7 ac 1a e1 00 00:01:27.375 READ DMA
Error 5 occurred at disk power-on lifetime: 4870 hours (202 days + 22 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
02 51 00 00 00 00 a0 Error: TK0NF
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
10 00 00 00 00 00 a0 00 06:53:38.250 RECALIBRATE [OBS-4]
00 00 01 01 00 00 a0 00 06:53:38.188 NOP [Abort queued commands]
90 00 04 01 00 00 e0 00 06:53:37.188 EXECUTE DEVICE DIAGNOSTIC
ec 00 05 01 00 00 a0 00 06:53:37.125 IDENTIFY DEVICE
00 00 01 01 00 00 a0 00 06:53:25.500 NOP [Abort queued commands]
Error 4 occurred at disk power-on lifetime: 4839 hours (201 days + 15 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
02 51 00 00 00 00 a0 Error: TK0NF
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
10 00 00 00 00 00 a0 00 00:02:00.563 RECALIBRATE [OBS-4]
00 00 01 01 00 00 a0 00 00:02:00.500 NOP [Abort queued commands]
90 00 04 01 00 00 e0 00 00:01:59.500 EXECUTE DEVICE DIAGNOSTIC
ec 00 05 01 00 00 a0 00 00:01:59.375 IDENTIFY DEVICE
00 00 01 01 00 00 a0 00 00:01:45.188 NOP [Abort queued commands]
Error 3 occurred at disk power-on lifetime: 4839 hours (201 days + 15 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
02 51 00 00 00 00 a0 Error: TK0NF
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
10 00 00 00 00 00 a0 00 19:11:03.438 RECALIBRATE [OBS-4]
00 00 01 01 00 00 a0 00 19:11:03.375 NOP [Abort queued commands]
90 00 04 01 00 00 e0 00 19:11:02.375 EXECUTE DEVICE DIAGNOSTIC
ec 00 05 01 00 00 a0 00 19:11:02.313 IDENTIFY DEVICE
00 00 01 01 00 00 a0 00 19:10:48.125 NOP [Abort queued commands]
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 11821 -
Device does not support Selective Self Tests/Logging