Wobei ein Core der mit 5-fast 6Ghz läuft, eher am gleichschnellen RAM verhungert, als einer mit ~3,5.bensen schrieb:unterschiedliche L3 Cache zur Verfügung bei Strix Point.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Bericht Intel Lunar Lake im Detail: Die neuen E-Cores schlagen die alten P-Cores, Xe2 löst Xe ab
N
Nooblander
Gast
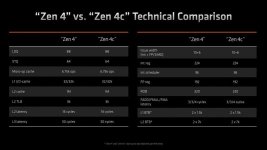
Bei Zen 4C war das nicht der Fall und das wird sich mit 5C auch nicht geändert haben.bensen schrieb:Das scheduling ist auch hier sehr wichtig.
YouTube
An dieser Stelle steht ein externer Inhalt von YouTube, der den Forumbeitrag ergänzt. Er kann mit einem Klick geladen und auch wieder ausgeblendet werden.
Ich bin damit einverstanden, dass YouTube-Embeds geladen werden. Dabei können personenbezogene Daten an YouTube übermittelt werden. Mehr dazu in der Datenschutzerklärung.
Im Video werden die Dense Cores auch nochmal sehr gut erklärt.
Ergänzung ()
Das mit dem Cache wurde ursprünglich mal so vermutet für Ryzen, vor Release. Wurde aber nur für Epyc/Bergamo so umgesetzt.Novasun schrieb:Und etwas weniger Cache - weil das mit den meisten Platz spart. Und sie takten nicht ganz do hoch... Also nicht exakt die gleiche Leistungsfähigkeit..
Du meintest sie haben exakt das selbe Featureset.
Der Taktunterschied bei Zen 4/Zen 4C war/ist bei den Ryzen 8000 APUs zum Bsp minimal (Mhz, nicht Ghz Bereich)
Exakt habe ich auch nicht geschrieben aber es ging hier auch eher darum ob der Leistungsunterschied einen Extra Scheduler notwendig macht und der Fall ist nicht gegeben.
Ist die Cache Anpassung bei Zen 5C tatsächlich bereits bekannt so im Detail?
Hatte hier bisher nichts gelesen dazu.
Anhänge


Zuletzt bearbeitet von einem Moderator:
Piktogramm
Admiral
- Registriert
- Okt. 2008
- Beiträge
- 9.471
Intel schreibt schon präzise, dass weniger Load/Store im Assembly erscheint, was aber nur sehr bedingt etwas mit den von der CPU ausgeführten L/S-Operationen zu tun hat. Mit dem größeren Registersatz der ISA kann man eine L/S als Anweisungen vermeiden, wenn man ein paar Instruktionen einen Wert wiederverwenden will. Der kann mit mehr GPRs eher mal in einem der logischen Register verbleiben. Das große ABER an der Stelle ist, dass über Renaming und Reorderbuffer weit mehr physische Register zur Verfügung stehen als logische Register in der ISA definiert sind (>>100 GPRs sind es real). Nur weil da ständig der Befehl kommt Register zu laden und zu schrieben heißt das nicht, dass die CPU das ohne Not tut.DevPandi schrieb:Lies dir mal die Angaben zu Intel APX durch und was das Erhöhen der Register von 16 auf 32 bringt. Es wird von 20 % Store und 10 % Load.
Load/Store kosten Energie und je länger das Programm mit den Registern arbeiten kann, umso besser ist es für die Effizienz. Im Gegenzug kann man entweder die gleiche Menge an ALUs mit weniger "Infrastruktur" versorgen oder mehr ALUs mit der gleichen Infrastruktur.
Ein typisches Beispiel wäre der Zähler einer Schleife. Nach Assembler fliegt der bei einem knappen Registersatz ständig aus den logischen Registern. Praktisch wird eine moderne CPU diesen Wert aber so gut wie möglich in einem physichem Register vorhalten.
APX ist dennoch sehr sinnvoll. Mit mehr logischen Registern gibt es weniger L/S Befehle die durchs FrontEnd müssen, Renaming/Reordering wird etwas simpler.
Und ja, entsprechend meiner Fußnote. Alle gewünschten Daten immer magisch in irgend einem Register finden zu können wäre der optimale Fall. Aber das klappt halt nicht.
N
Nooblander
Gast
Hier sprechen Test nunmal von eine sehr ähnlichen Leistung und Spezifikationen und auch AMD (siehe meine 1. Antwort) und selbst wenn die Dense Cores 3% langsamer sind macht dies keinen Scheduler notwendig. Du stellst eine Frage, weil du etwas nicht weißt, bekommst eine Antwort und sagst direkt man lügt, was schon schwach ist. Dann suche dir doch demnächst die frei verfügbaren Informationen selbst aus dem Netz und erspare Anderen deine UnterstellungenDonnidonis schrieb:@DevPandi Nur eben nicht @Nooblander, das was er sagt (c-Cores gleiche Leistungsfähigkeit etc.) ist halt nicht wahr.
https://www.phoronix.com/review/amd-zen4-zen4c-scaling/
www.hardwareluxx.de/index.php/news/hardware/prozessoren/63013-isscc-2024-warum-amds-zen-4c-kerne-sogar-schneller-als-der-gro%25C3%259Fe-bruder-sein-kann
www.techpowerup.com/310057/amd-zen-4c-not-an-e-core-35-smaller-than-zen-4-but-with-identical-ipc
Anhänge

Zuletzt bearbeitet von einem Moderator:
- Registriert
- Juli 2021
- Beiträge
- 3.150
Lies den Text mal als ganzes und was auch die Intension sind.Piktogramm schrieb:Intel schreibt schon präzise, dass weniger Load/Store im Assembly erscheint, was aber nur sehr bedingt etwas mit den von der CPU ausgeführten L/S-Operationen zu tun hat.
Das, was du hier schreibst, ist weitgehend falsch, sowohl register Renaming als auch der reoderbuffer haben kaum Auswirkungen darauf, wie viele Load/Store-anweisungen durch die CPU ausgeführt werden.Piktogramm schrieb:Mit dem größeren Registersatz der ISA kann man eine L/S als Anweisungen vermeiden, wenn man ein paar Instruktionen einen Wert wiederverwenden will. Der kann mit mehr GPRs eher mal in einem der logischen Register verbleiben. Das große ABER an der Stelle ist, dass über Renaming und Reorderbuffer weit mehr physische Register zur Verfügung stehen als logische Register in der ISA definiert sind (>>100 GPRs sind es real). Nur weil da ständig der Befehl kommt Register zu laden und zu schrieben heißt das nicht, dass die CPU das ohne Not tut.
Der Reoderbuffer sortiert die Befehle passend, dass sie möglichst parallel ausgeführt werden und das renaming sorgt dafür, dass möglichst wenig Kopieraktionen notwendig sind. Am Ende bleibt es aber bei 16 Register, die genutzt werden.
zudem sind die vielen GPRs in der CPU auch heute notwendig, weil für jede ALU entsprechende Register vorhanden sein müssen, damit diese auch gefüllt werden. Bei 5 ALUs müssen alle 16 Register 5 mal vorhanden sein, was bereits 80 Register aus macht, nur damit das alles abgedeckt werden kann.
Mit den ganzen weiteren EInheiten für Load sowie den Spekulativen-Ausführung, Branches usw, ist es eine Notwendigkeit, dass die Register da sind, weil man sonst viel zu wenig hätte.
Das heißt, weniger Load/Store-Anweisungen im Programm, wirken sich natürlich auch unmittelbar auf die CPU aus, sonst würde sich Intel das ganze sparen.
D
Donnidonis
Gast
Dein erster Link zeigt es doch schon: Zen4 Core 5.07 GHz, der Zen4c Core 3.73 GHz.Nooblander schrieb:und selbst wenn die Dense Cores 3% langsamer sind
Der Kern kann genau das selbe, ja. Wie jetzt der DenseCore nur 3% langsamer sein kann bei 1.34 GHz weniger, Respekt. Dann sollten die die richtigen Cores direkt abschaffen, denn der Dense Core wird ja viel sparsamer sein, taktet geringer, ist kleiner. Was will man mehr.
GR Supra
Lieutenant
- Registriert
- Mai 2024
- Beiträge
- 527
Unterstellen wir seriöse Aufbauten und Abläufe, dann ist LL wirklich der Knüller.

YouTube
An dieser Stelle steht ein externer Inhalt von YouTube, der den Forumbeitrag ergänzt. Er kann mit einem Klick geladen und auch wieder ausgeblendet werden.
Ich bin damit einverstanden, dass YouTube-Embeds geladen werden. Dabei können personenbezogene Daten an YouTube übermittelt werden. Mehr dazu in der Datenschutzerklärung.
Zuletzt bearbeitet:
Nooblander schrieb:Ist die Cache Anpassung bei Zen 5C tatsächlich bereits bekannt so im Detail?
Hatte hier bisher nichts gelesen dazu.
Mir wäre auch nichts bekannt. Ich gehe aber davon aus. 5c zu 4c wird in meinen Augen "nur" ein Shrink plus das was Zen 5 kann.
Und damit hat man schon genug zu tun. Und Cache sparen bedeutet in der Fläche richtig Holz. Und die Kerne sollen ja Flächentechnisch klein sein.
Was problematisch sein kann sind Hotspots. Zen 5 wird doch auch einen der 3er Prozesse von TMSC nutzen..
Was ich mich frage - ob AMD erst Zen5 fertig entwickelt und dann hingeht und mit Cache beschneiden und Bibliotheken für dichtes Packaging den Zen 5 Entwurf hin zum 5c optimiert...
Oder ob das parallel läuft...
Wenn nicht parallel werden wir 5c ja erst später zu Gesicht bekommen.
Und was willst du damit sagen? Verstehe nicht wie das zum Thema passt.bad_sign schrieb:Wobei ein Core der mit 5-fast 6Ghz läuft, eher am gleichschnellen RAM verhungert, als einer mit ~3,5.
Das stimmt, aber das ist nicht der Kern des Problems. Was in der Form nicht möglich ist, ist eine Verteilung auf Basis der Wichtigkeit innerhalb der Applikation. Die Aufgabe des Thread Schedulers ist, ankommende Aufgaben auf die vorhandenen Ressourcen nach definierten Mustern zu verteilen. Soweit sogut, aber technisch bedingt ist für den Thread Scheduler jede Aufgabe gleich gewichtig und so eine "von oben" Verteilung kann nicht wissen, ob die Aufgabe jetzt wichtiger ist und möglichst schnell abgearbeitet oder eher unwichtig ist und einfach nur irgendwie abgearbeitet werden muss.DevPandi schrieb:Das macht der Scheduler in Windows selbstständig, er weis welche Kerne er hat und welche wie im Einsatz sind. Auch die Zuweisung übernimmt das OS.
Das hat zur Folge, dass mit zunehmend knapper werden real freien Ressourcen Konflikte entstehen und im Zuweifel die falschen Threads "warten" -> was zu Lesitungsverlust führt.
Wie gesagt, das stimmt so nur bedingt. Denn es ist nicht entscheidend zu wissen, ob ein CPU Kern Rechenzeit frei hat, sondern es muss gewusst werden, welche Aufgabe von der Prio her wie gewichtig ist und welcher der Threads sich diesen gewichtigeren hinten an stellen sollte. Das kann das OS bzw. der Threadscheduler prinzipbedingt nicht wissen. Denn es steckt sprichwörtlich da nicht drin.DevPandi schrieb:Ja, nur hat das OS diese Informationen in der Regel bereits. Die werden entweder per Treiber oder andere Weise hinterlegt.
Für das OS bzw. den Thread Scheduler ist eine Aufgabe eine Aufgabe. Wenn zwei solcher um die Rechenzeit buhlen, dann wird eine ca. 50:50 Verteilung entstehen. Als Programmierer kann man das beeinflussen. Aber von außen ist das so nur bedingt möglich zu beeinflussen.
Das Ding dabei ist, nimm bspw. das Gaming Beispiel (ihr kamt ja oben argumentativ vom Umstand eines normalen Cores vs. einen C-Cores bei AMD) -> wenn der Thread, der für den FPS Loop zuständig ist, auf dem falschen Core läuft, also nicht auf dem mit dem höchsten Takt sondern auf einem langsamen, dann verliert das in Summe Leistung obwohl das OS 1a seiner Verteilaufgabe nach kommt und alles schön sauber verteilt. Einfach nur weil es nicht wissen kann, dass der Bench/das Game limitiert durch diesen Loop ist.
Piktogramm
Admiral
- Registriert
- Okt. 2008
- Beiträge
- 9.471
Ich habe den Text gelesen.DevPandi schrieb:Lies den Text mal als ganzes und was auch die Intension sind.
Und was sind weniger Kopieraktionen bitte? Sind das vielleicht eingesparte Load/Stores, weil der physische Registersatz schlicht groß genug ist?DevPandi schrieb:Das, was du hier schreibst, ist weitgehend falsch, sowohl register Renaming als auch der reoderbuffer haben kaum Auswirkungen darauf, wie viele Load/Store-anweisungen durch die CPU ausgeführt werden.
Der Reoderbuffer sortiert die Befehle passend, dass sie möglichst parallel ausgeführt werden und das renaming sorgt dafür, dass möglichst wenig Kopieraktionen notwendig sind. Am Ende bleibt es aber bei 16 Register, die genutzt werden.
Und physisch werden viel mehr Register genutzt, logisch werden nur weniger direkt angesprochen.
? Nur weil es physisch mehr Register gibt für die Sheduler der Executionports braucht die ISA nicht zwingend mehr logische Register.DevPandi schrieb:zudem sind die vielen GPRs in der CPU auch heute notwendig, weil für jede ALU entsprechende Register vorhanden sein müssen, damit diese auch gefüllt werden. Bei 5 ALUs müssen alle 16 Register 5 mal vorhanden sein, was bereits 80 Register aus macht, nur damit das alles abgedeckt werden kann.
Ja deswegen gibts ja zig hundert physische Register fürs Renaming..DevPandi schrieb:Mit den ganzen weiteren EInheiten für Load sowie den Spekulativen-Ausführung, Branches usw, ist es eine Notwendigkeit, dass die Register da sind, weil man sonst viel zu wenig hätte.
Ja habe ich auch beschrieben, dass es durchaus sinnvoll ist. Nur eben mit der Einschränkung, dass logische GPRs in der ISA zu weniger L/S Instruktionen im Assembly führen, aber nicht zwingend im gleichen Maße zu ausgeführtem L/S der CPU.DevPandi schrieb:Das heißt, weniger Load/Store-Anweisungen im Programm, wirken sich natürlich auch unmittelbar auf die CPU aus, sonst würde sich Intel das ganze sparen.
Die CPU-Entwickler sind ja nicht all die Jahre doof gewesen und haben nicht versucht L/S auf Ebene der CPU zu minimieren.
Sorry, hatte 8P+8E im Kopf, aber ich hab vergessen, dass schon Raptor 8+16 hatCr4y schrieb:@BAR86 :
Die letzten Gerüchten gehen doch von zwei Compute-Tile-Konfigurationen aus:
8P + 16E
6P + 8E
z.B.: https://www.pcgameshardware.de/Inte...-als-Basis-fuer-alle-Modelle-kein-i3-1446426/
AMD hat Zen 4c im Consumer Bereich NICHT beim Cache beschnitten, sowohl Phoenix als auch Phoenix2 haben jeweils 16MB L3.Novasun schrieb:Und Cache sparen bedeutet in der Fläche richtig Holz.
crustenscharbap
Rear Admiral
- Registriert
- Jan. 2008
- Beiträge
- 5.148
Hier kannst du anschauenPhilste schrieb:Wo sieht man das? Würde mich echt interessieren, war mir bisher so nicht bekannt
Kam jetzt erst zum durchlesen: Das hört sich recht heftig an. Mal sehen was Intel wirklich umsetzen kann. Welch Wunder auch ein gänzlich anderer Prozess wirken kann.. Ich halte AMD trotzdem die treue. Aber so langsam müssen die auch mal wieder in die Pötte kommen. Vor allem auch was Ausstattung angeht.
Northstar2710
Admiral
- Registriert
- Aug. 2019
- Beiträge
- 8.031
Du hast aber schon gemerkt das der 16gb minisforum mini pc nur 2gb RAM für die igpu reserviert sind und beim beelink mit 32gb sind es 4gb. Das macht den grossen unterschied aus. nicht die 16gb mehr RAM. Das kannst du im bios auch für das minisforum gerät ändern. dann steht zwar mur noch 12gbRAM zur verfügung, reicht bei den fps aber für die allermeisten spiele ohne Probleme.crustenscharbap schrieb:
das machen viele am steamdeck genauso, nur muss man dort im steamos die swap datei vergrößern damit zur not genug platz in der swap datei zur verfügung steht. die ist dort mit 1gb begrenzt.
N
Nooblander
Gast
Was stellst du dir denn da so vor, was bisher nicht geboten wird bzw. zeitnah verfügbar ist?janer77 schrieb:Vor allem auch was Ausstattung angeht.
D
Donnidonis
Gast
Donnidonis schrieb:Der Kern kann genau das selbe, ja. Wie jetzt der DenseCore nur 3% langsamer sein kann bei 1.34 GHz weniger, Respekt.
Kommt dazu noch eine Erklärung @Nooblander ? Da wäre ich dich sehr dran interessiert.Nooblander schrieb:und selbst wenn die Dense Cores 3% langsamer sind macht dies keinen Scheduler notwendig
v_ossi
Commodore
- Registriert
- Juni 2011
- Beiträge
- 4.793
Bin spät dran, aber ein paar Fragen hätte ich dann doch noch:
Die Lion Cove Kerne haben kein HT, habe ich verstanden, aber die Skymont Kerne schon, richtig?
Würde sich nämlich trotz offensichtlicher Steigerungen bei IPC und Takt merkwürdig anfühlen von 6K/12T (Coffee Lake) auf 8K/8T Lunar Lake 'aufzurüsten'.
Und wie viel schneller ist der RAM (32 GB LPDDR5 @ 8.533 MT/s) auf dem Package im Vergleich zu meinem betagten 16 GBDDR4 @ 2600Mhz?
Die Lion Cove Kerne haben kein HT, habe ich verstanden, aber die Skymont Kerne schon, richtig?
Würde sich nämlich trotz offensichtlicher Steigerungen bei IPC und Takt merkwürdig anfühlen von 6K/12T (Coffee Lake) auf 8K/8T Lunar Lake 'aufzurüsten'.
Und wie viel schneller ist der RAM (32 GB LPDDR5 @ 8.533 MT/s) auf dem Package im Vergleich zu meinem betagten 16 GBDDR4 @ 2600Mhz?
Ähnliche Themen
- Antworten
- 203
- Aufrufe
- 23.803
- Antworten
- 34
- Aufrufe
- 4.189
- Antworten
- 76
- Aufrufe
- 7.639


